
July 2024
Horizontal Pod Autoscaling, Enhanced GPU Monitoring, and Improved Kubernetes Security Features
Major Features and Improvements
Horizontal Pod Autoscaling (HPA)
Workload autoscaling got a significant upgrade with our new Horizontal Pod Autoscaler (HPA). Working independently or in tandem with our Vertical Pod Autoscaler, HPA dynamically adjusts pod counts based on CPU usage, ensuring your applications stay responsive and cost-effective. Configure it easily through our UI, API, or Kubernetes annotations to keep your workloads perfectly balanced. Just ensure you're running the latest versions of our autoscaler and agent to take full advantage of this powerful new feature. Get started in our docs!
Billing Report Enhancements
We've significantly improved our billing system to ensure accuracy and consistency across all reporting channels. The Billing Report now uses 10-minute aggregation intervals, aligning with other reporting services as of July 1st. These changes streamline our billing processes, eliminating manual reconciliations and providing you with more accurate, consistent financial data across all platforms.
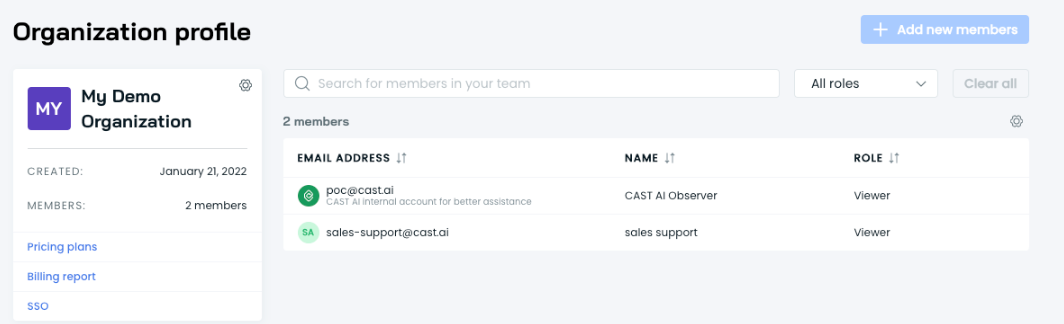
Streamlined Support Access with CAST AI Observer
We have streamlined our support process by automatically adding the newly renamed CAST AI Observer account (formerly the POC account) to all newly created organizations with view-only permissions. This account allows our support and engineering teams to assist you more efficiently, analyze workloads proactively, and resolve incidents faster - all without requiring manual intervention from your side. Don't worry; you retain complete control: the account's purpose is transparently displayed in the UI, and you can remove it at any time if you prefer.
Cloud Provider-Specific Updates
EKS: Flexible AMI Selection
We've enhanced the flexibility of node configurations for Amazon EKS clusters. In both our API and Terraform provider, you can now specify an AMI family instead of an exact AMI when setting up your node templates. This improvement allows you to choose from supported image families like Amazon Linux 2, Amazon Linux 2023, or Bottlerocket, giving you more control over your node operating systems while benefiting from automatic updates within your chosen family.
EKS: Multiple Load Balancer Support
We've enhanced our EKS node configuration to support multiple load balancers per node. The UI, API, and Terraform providers now accept an array of target groups, replacing the previous single target group field. This update allows for more flexible and complex load balancing setups, catering to scenarios where nodes must simultaneously be associated with multiple load balancers. The old single target group field has been deprecated but remains functional for backward compatibility.

GKE: Local SSD Enhancements
We've expanded our local SSD support for GKE clusters across our platform. The new useEphemeralStorageLocalSsd boolean parameter is now available in our Node configuration API, allowing you to easily enable or disable local SSD-backed ephemeral storage for your GKE nodes. We've also integrated this option into our node configuration UI, making it even more accessible.

Kubernetes Security and Compliance
New Workloads View for Enhanced Visibility
Our team has expanded our Kubernetes Security section with a new Workloads view, providing an overview of all workloads across your clusters from a security perspective. This new view lets you easily search, filter, and sort your workloads by cluster, namespace, and labels. This addition complements our existing security features, offering you a more holistic approach to workload security management.
Enhanced Malware Detection
We've improved our runtime security capabilities with a new built-in rule to detect executions of known hacking tools. The Hacking tool executed rule complements our existing detections, providing broader coverage against potential security threats in your clusters. This enhancement is part of our Kubernetes Runtime Security feature, which is currently in closed preview. If you're interested in gaining early access to these advanced security capabilities, please contact our support team for availability and enrollment details.
Reporting and Cost Optimization
Persistent Volume (PV) Storage Dimension Added
You'll now find PV usage (in GiB) and associated costs integrated throughout our API reports and metrics, from cluster-level to organization-wide. This new dimension provides a more comprehensive view of your resource utilization, enabling better-informed decisions for storage optimization alongside compute resources.
New GPU Utilization Tab
We've introduced a dedicated GPU utilization tab in the Workloads view, offering deeper insights into your GPU-enabled workloads. This new tab provides a comprehensive overview of GPU usage, including average utilization rates and associated costs. These insights are also available per workload and as a summary in the Dashboard. You can quickly identify top GPU consumers and potential optimization opportunities, enhancing your ability to manage and optimize GPU resources effectively.
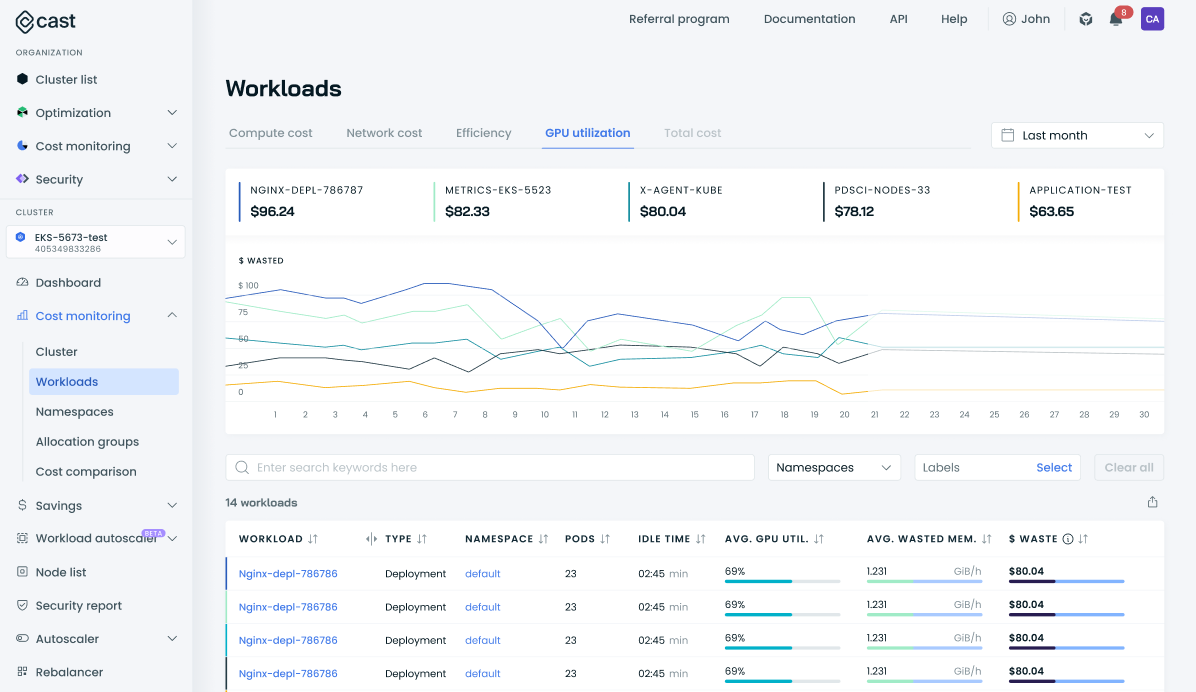
Expanded GPU Metrics Collection
We've enhanced our GPU monitoring capabilities by adding four new metrics to our data collection: FP64, FP32, and FP16 pipeline activity, as well as integer pipeline activity. These additional data points, collected via our gpu-metrics-exporter, provide a more comprehensive view of GPU utilization across different computation types. Read about all of the metrics the exporter collects.
Cluster Rebalancer: Enhanced Flexibility in Savings Thresholds
We improved the Cluster Rebalancer to give you more control over when rebalancing operations occur. While you can still set a target savings threshold to trigger rebalancing, we've now added an option to bypass this requirement. By unchecking the Execute only if there are guaranteed minimum savings box, you can ensure rebalancing proceeds even if the projected savings don't meet the specified threshold.

UI/UX Improvements
Billing Report Re-re-location
Following user feedback on the Billing Report's recent relocation to the Organization Profile, we've enhanced accessibility by restoring access from the Optimization section. Now, you can conveniently access the Billing Report from both the Organization Profile and the Optimization section.
Cluster Dashboard Enhancements
We've upgraded the Cluster Dashboard to provide you with more crucial information. The last reconciliation timestamp is now in the top-right corner, giving you immediate insight into the freshness of your cluster data. Additionally, we've added the Kubernetes version to the cluster details section, allowing you to verify your cluster's compatibility with the latest features quickly.
Improved Image Scan Error Reporting
We've enhanced the visibility of our image-scanning process in the Kubernetes Security section. When an image scan fails, you'll now see a detailed error message explaining the reason for the failure. This improvement allows you to quickly identify and address issues that may be preventing successful scans, such as invalid characters in image names or network connectivity problems.
Enhanced Resource Filtering in Kubernetes Security
We've added a labels filter to the Kubernetes Security Best Practices drawer in the resources tab, allowing for more granular resource filtering.
Improved Sorting in Commitments UI
We've enhanced the commitments view to prioritize active commitments. While maintaining the existing sort by start and end dates, active commitments now appear at the top of the list. This change provides a clearer overview of your current resource allocations, allowing for quicker access to the most relevant commitment information.
API and Metrics Improvements
Workload Optimizer Metrics Tracking
We've introduced a new Prometheus metric to track the Workload Optimization status across your clusters. The workload_optimization_enabled label is now available through our metrics API, allowing you to monitor the number of workloads with Optimizer enabled versus those without.
Component Updates
Autoscaler: Legacy Agent Version Limitations
Users running castai-workload-autoscaler versions below 0.5.0 will notice restricted functionality in the autoscaler configuration UI. The mode selection option between deferred and immediate is now hidden for these older versions. We strongly recommend upgrading your agent to the latest version to access the full range of autoscaling features and options.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the CAST AI agent. The complete list of changes is here.