
September 2025
Container Live Migration, Multi-Cloud Cluster Extension with OMNI, and Other Platform-Wide Improvements
Major Features and Improvements
Container Live Migration for Zero-Downtime Workload Optimization
Container live migration enables seamless relocation of running workloads between nodes without downtime or service interruption. Unlike traditional pod eviction, live migration preserves complete runtime state, including memory, process state, and active network connections, allowing stateful applications to be moved without impact.
The feature integrates with Cast AI's Evictor for continuous cluster optimization and also works with Rebalancer to support scheduled optimization and maintenance without disruption. Cast AI automatically identifies eligible workloads and handles migration with fallback to traditional eviction if needed.
Currently available in early access for AWS EKS clusters running Kubernetes 1.30 or later, the feature can be enabled through node templates with minimal configuration.
Learn more about Container Live Migration or see our documentation for setup instructions.
OMNI: Multi-Region and Multi-Cloud Cluster Extension
OMNI extends Kubernetes clusters to additional regions and cloud providers, enabling node provisioning beyond the cluster's primary region. Once configured, Cast AI's Autoscaler automatically selects the most cost-effective location based on real-time pricing and instance availability, comparing options across the main cluster region and configured edge locations.
The feature addresses GPU capacity constraints by expanding access across multiple regions and clouds. OMNI supports both cross-region expansion (EKS to additional AWS regions, GKE to additional GCP regions) and cross-cloud extension (EKS to GCP regions, GKE to AWS regions). Edge nodes appear as standard nodes in the cluster and are managed through familiar Cast AI workflows.
OMNI is currently available in early access for Phase 2 EKS and GKE clusters. It can be enabled during cluster onboarding or added to existing automated clusters.
Come see us live when we demo OMNI at KubeCon North America later this year.
For setup instructions and technical details, see our OMNI documentation.
Security and Compliance
HuggingFace Authentication Integration
Users can now sign up and log in to Cast AI using their HuggingFace accounts. This authentication option works alongside existing login providers like Google and GitHub, streamlining access for AI Enabler users who are deploying LLMs from HuggingFace directly to their Kubernetes clusters managed by Cast AI.
Cast AI sign-in page offering the new HuggingFace option
Enterprise-Level API Key Management
API key creation now supports organization-level selection for Enterprise accounts. Users can create API keys at either the Enterprise level (with automatic access to all child organizations) or at individual child organization levels directly through the console.
Previously, users were automatically redirected to the child organization context when accessing API key settings. The API key creation modal now includes an organization selector for proper scope management.
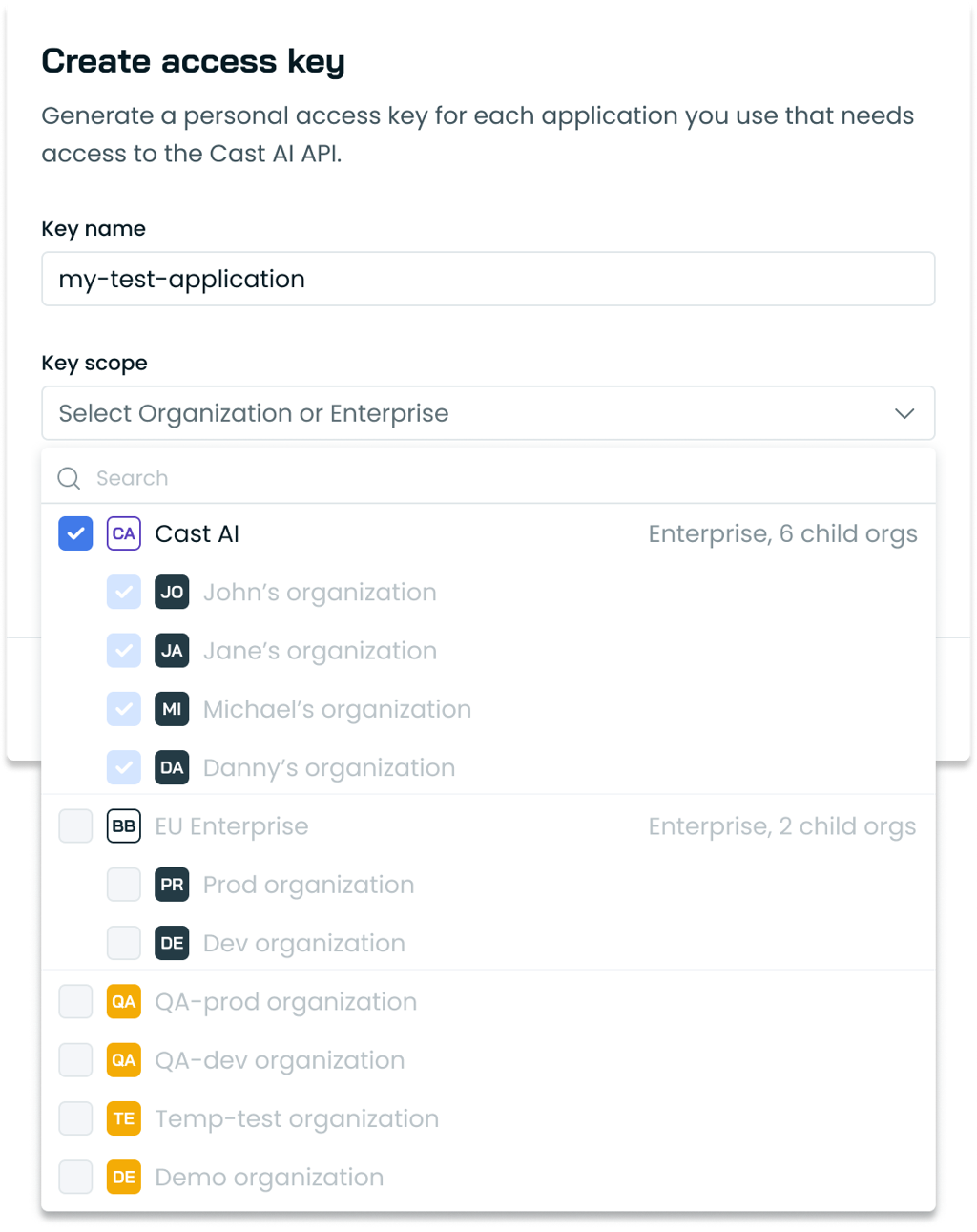
API access key creation modal showing the new Enterprise key scopes
Terraform Support for Enterprise Group Management
Enterprise groups can now be managed through the Cast AI Terraform provider using the new castai_enterprise_groups resource. Users can configure group membership, role bindings, and access scopes across Enterprise child organizations through familiar IaC tooling.
Cloud Provider Integrations
Configurable Permission Scopes for Cloud Connect
Cloud Connect now supports granular permission scope selection during AWS and GCP onboarding. This flexibility enables organizations to grant Cast AI only the access levels required for their use case while maintaining strict security controls.
For all available scopes and their permissions, see our updated cloud permissions documentation.
Azure
Automated Azure Reserved Instance Sync
Azure Reserved Instance importing now supports automated synchronization through an updated script. The new script configures a Cloud Connect integration scoped to commitments-related permissions that automatically syncs Reserved Instance commitments on a recurring basis. This streamlines the user experience and ensures Cast AI always has current Reserved Instance data for optimization decisions.
Oracle
Oracle Cloud Infrastructure Cluster Discovery
Cloud Connect now supports discovering Kubernetes clusters running on Oracle Cloud Infrastructure (OCI). Users can run a discovery script to identify their OCI-based Kubernetes clusters and view potential optimization opportunities before onboarding them. Discovered Oracle clusters can subsequently be connected as Cast AI Anywhere clusters to access workload optimization and resource consolidation features.
Node Configuration
Dynamic Max Pods Formula for GKE
GKE node configurations now support a dynamic max pods per node formula that calculates pod limits based on instance characteristics. This advanced option allows different pod limits for different instance types within the same node configuration using variables like CPU count and RAM. The formula accounts for GKE's Pod CIDR reservation methodology, providing more flexible pod density management for clusters with diverse instance types. For most use cases, the existing static max pods per node value remains the recommended approach.
See our updated node configuration documentation for details.
Hyper-Threading Control for AWS EKS Nodes
AWS EKS node configurations now support disabling Hyper-Threading (simultaneous multithreading) on worker nodes. When Hyper-Threading is disabled, the number of available vCPUs equals the number of physical CPU cores on the instance. The setting can be configured through the Cast AI Console, API, or Terraform and only affects newly provisioned nodes after the configuration is applied.
See our updated node configuration documentation for details.

The new option to disable Hyper-Threading (or SMT) in Node Configuration
Cluster Optimization
Pod Events for Node Provisioning Failures
The Autoscaler now generates Kubernetes pod events when node provisioning fails, providing visibility into why capacity cannot be added for pending pods. When the Autoscaler exhausts all provisioning options without successfully adding a node, it creates an event with the specific failure reason, such as Upscaling failed due to: no alternatives available.
We are hoping this improves visibility for customers as it allows monitoring tools to programmatically detect and respond to provisioning issues.
Workload Optimization
Gradual Scaling for New Clusters
Workload Autoscaler now provides immediate optimization for newly onboarded clusters through gradual scaling during the first 24 hours. Rather than waiting days to collect sufficient historical data, the system applies conservative resource adjustments with progressive limits to both upscaling and downscaling. After 24 hours, the system transitions to confidence-based optimization with unrestricted recommendations.
This feature is enabled by default for new clusters and allows users to see optimization results within hours rather than days.
Sidecar Container Support in Workload Autoscaler
Workload Autoscaler now supports optimization of Kubernetes native sidecar containers, which are init containers with restartPolicy: Always. Workload Autoscaler automatically identifies these containers, collects their CPU and memory usage metrics, and generates resource recommendations alongside the main application containers.
This enables optimization of containers such as Istio service mesh proxies, logging agents, and monitoring sidecars. The feature requires updating to Workload Autoscaler v0.56.0 (Helm chart 0.1.126 or later) and Evictor Helm chart 0.33.61 or later.
ContainerResource HPA Support
Workload Autoscaler now fully supports Kubernetes ContainerResource HPA configuration, which allows horizontal autoscaling based on individual container metrics rather than pod-level metrics. The system properly accounts for ContainerResource HPA when generating vertical scaling recommendations, preventing unnecessary horizontal scale-ups and ensuring workloads maintain appropriate resource allocations.
Datadog Injected-Container Support
Workload Autoscaler now automatically detects and accommodates Datadog containers that are injected into pods via admission controllers. The system identifies workloads using Datadog through pod annotations and labels, and applies appropriate minimum resource constraints to ensure Datadog's init containers have sufficient CPU and memory to function properly.
Automatic Override Reset When Toggling Scaling Policies
Workload Autoscaler now automatically clears workload-level management overrides when toggling a scaling policy on or off. For example, if you applied an override to a workload and excluded it from optimization, the next time you toggle the scaling policy's automation setting, the override will reset and the workload will follow the policy's optimization configuration. Users can still apply workload-specific overrides after policy changes if needed.
Optional One-by-One Pod Restart for Immediate Mode
Workload Autoscaler now offers an optional one-by-one pod restart strategy when choosing to apply recommendations immediately. When enabled, the system restarts pods sequentially, waiting for each to become healthy before proceeding to the next. This reduces disruption for workloads without Pod Disruption Budgets or with aggressive rollout strategies that might cause multiple simultaneous restarts.
Whitelisting Mode for Workload Autoscaler
Workload Autoscaler now supports an optional whitelisting mode that provides explicit control over which workloads receive automated optimization. When enabled at the cluster level via Helm configuration, the system continues to generate recommendations for all eligible workloads, but only applies them to workloads labeled with workload-autoscaler.cast.ai/enabled: "true". This enables customers to maintain stricter control over optimization through infrastructure-as-code while preventing unintended UI-based changes to workload management.
Cost Monitoring
Idle Resources Report
A new Idle Resources report is now available under Cost Monitoring, providing organization-level visibility into unused cloud resources that continue to accumulate costs after their associated clusters are deleted.
The report currently identifies unattached disks in Google Cloud Platform environments and their estimated monthly cost. This enables teams to identify and eliminate waste from forgotten resources, such as persistent volumes that remain after GKE cluster deletion.
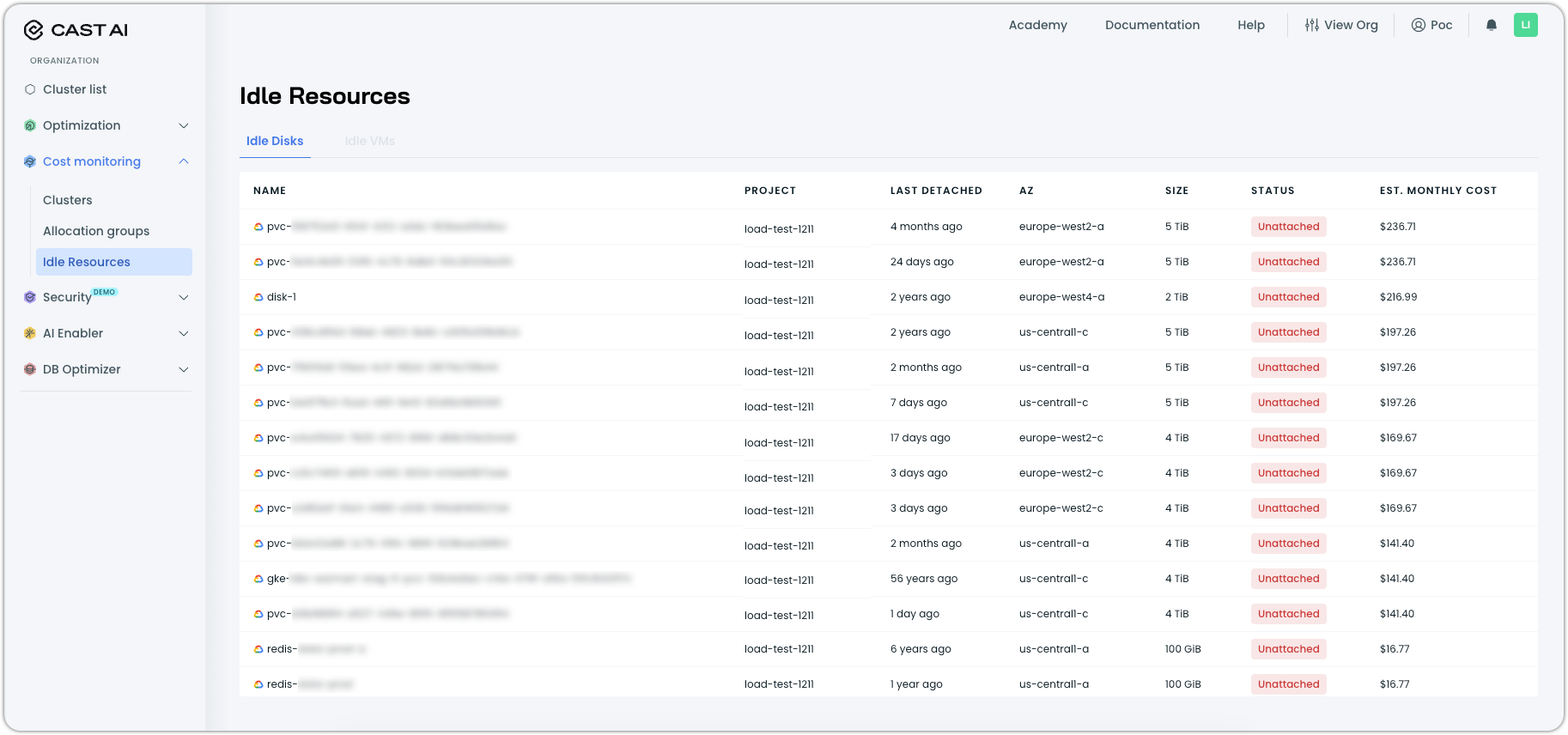
Idle resources report in Cost monitoring
Enhanced Cost Report Granularity
Cost reports now support 5-minute data granularity across all cluster-level and organization-level endpoints, enabling near real-time visibility into cost changes. Users can track the immediate impact of optimization actions such as rebalancing or autoscaling adjustments without waiting for daily aggregation. This enhanced granularity is available for all cost, efficiency, resource usage, and workload cost reports with a maximum time range of 10 days per query through the API.
List Price vs. Discounted Price View Toggle
Cost reports now include a pricing view selector that allows users to toggle between discounted prices (reflecting commitments and negotiated rates) and list prices (public cloud provider rates). This addresses scenarios where commitment coverage causes clusters to appear as having zero cost. The selector is available across cluster-level cost reports.
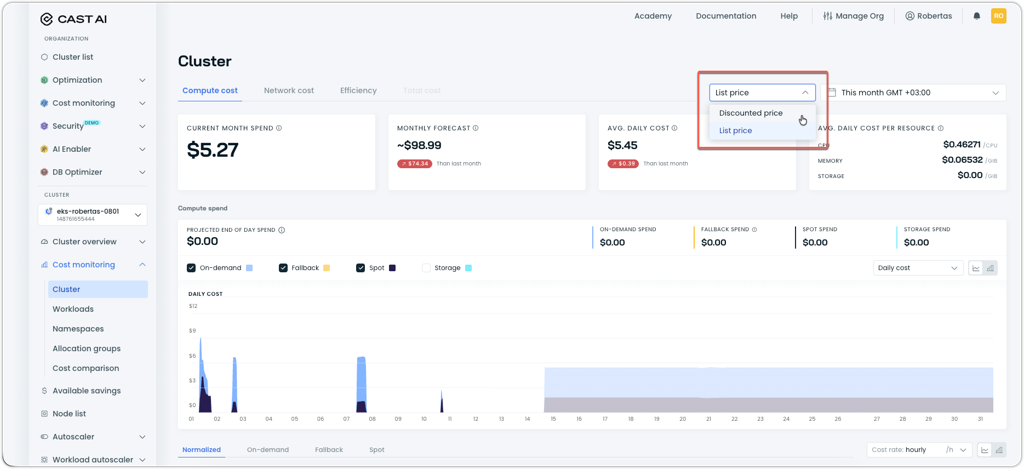
Cluster cost report showing the new pricing view selector dropdown
Database Optimization
Granular Query Visibility and Performance Insights
Database Optimizer now provides detailed visibility into individual query performance through an improved query detail view. Users can drill into specific queries to view time-series metrics, including cache hit rates, query volume, miss latency percentiles, and TTL values over customizable time periods.
The cache configuration page has been updated to display normalized query templates alongside their caching rules, making it easier to understand and manage cache behavior at the query level.
Cache Redeployment Option
Database Optimizer now includes a redeploy option in the cache management menu. This allows users to regenerate and rerun deployment scripts without waiting for an update notification.

Cache configuration showing the "Redeploy cache" option
AI Enabler
Expanded Model Support and Deployment Capabilities
AI Enabler continues expanding its model library. Recent additions include:
Gemma3:27Bfor multimodal use cases such as image classification and captioningmultilingual-e5-largeembedding model for enhanced semantic search across languagesLlama Guard 3for content moderation and safety filteringgpt-ossmodel support for extended deployment options.
These additions ensure teams have access to the latest AI capabilities while maintaining cost efficiency through Cast AI's automated model selection and Kubernetes optimization.
For the complete list of available models, see the AI Enabler documentation, which includes instructions for querying the API endpoint with the most up-to-date model catalog.
API Usage Examples for Embedding Models
The AI Enabler integration modal now includes code examples for embedding model endpoints in Python, JavaScript, and cURL formats. The examples are organized by use case type (Text, Text and Image, Embedding) for easy navigation.
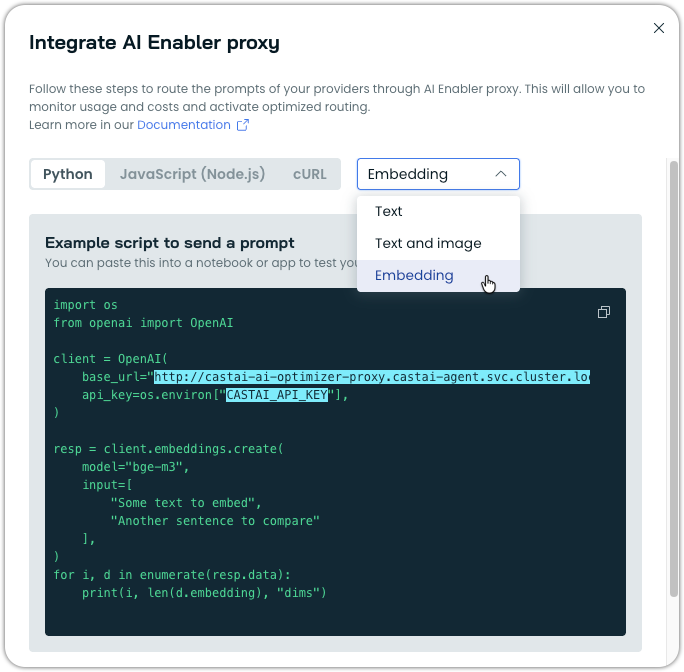
AI Enabler proxy integration modal showing the example for embedding models
Reduced Autoscaling Metric Options for Embedding Models
AI Enabler no longer offers GPU KV cache utilization as an autoscaling trigger for embedding models, as these models perform single forward passes and do not utilize KV cache. Instead, embedding models now default to request queue depth as the primary autoscaling metric, which better reflects their actual workload patterns.
Terraform Module Installation Support
AI Enabler can now be installed directly through Cast AI's official Terraform modules for EKS, GKE, and AKS clusters. Set the install_ai_optimizer variable to true in your cluster configuration to automatically deploy the AI Enabler Proxy during cluster onboarding. Manual Helm installation and console-based script installation options remain available for users who prefer those methods.
Google Vertex AI Integration Fixes
AI Enabler now distinguishes between Google's two AI platforms when registering providers: Vertex AI (Anthropic) and Vertex AI (Gemini). The Vertex AI integration now supports proper authentication using Service Account JSON credentials. This update enables correct provider registration for Google Cloud Vertex AI deployments while maintaining the existing API key authentication for Gemini SaaS.
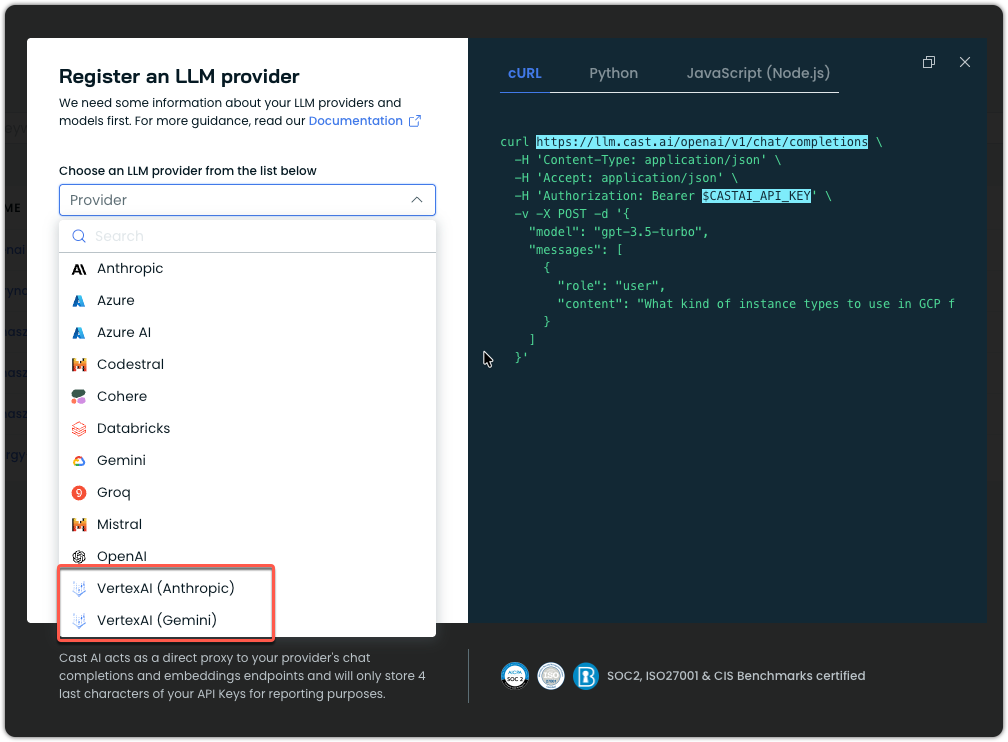
Provider registration modal in AI Enabler showing two distinct Vertex AI options
Ollama Deployment Support Removal
Ollama is no longer available as a deployment option for self-hosted models in AI Enabler. Users should deploy self-hosted models using vLLM, which provides better performance and broader model compatibility.
User Interface Improvements
Reworked Node List
The Node list has been redesigned with improved capabilities and information. Key updates include:
- Dedicated node details page: Access comprehensive node information by clicking node names in the details drawer (attached image)
- Workloads tab: View all workloads running on each node with filtering capabilities
- Problematic node indicators: Visual badges highlight nodes requiring attention for quick issue identification
- Expanded node actions: New context menu options include the ability to drain a node
These improvements are part of an ongoing effort to make the node list provide better visibility into node health and streamline node management on the platform.
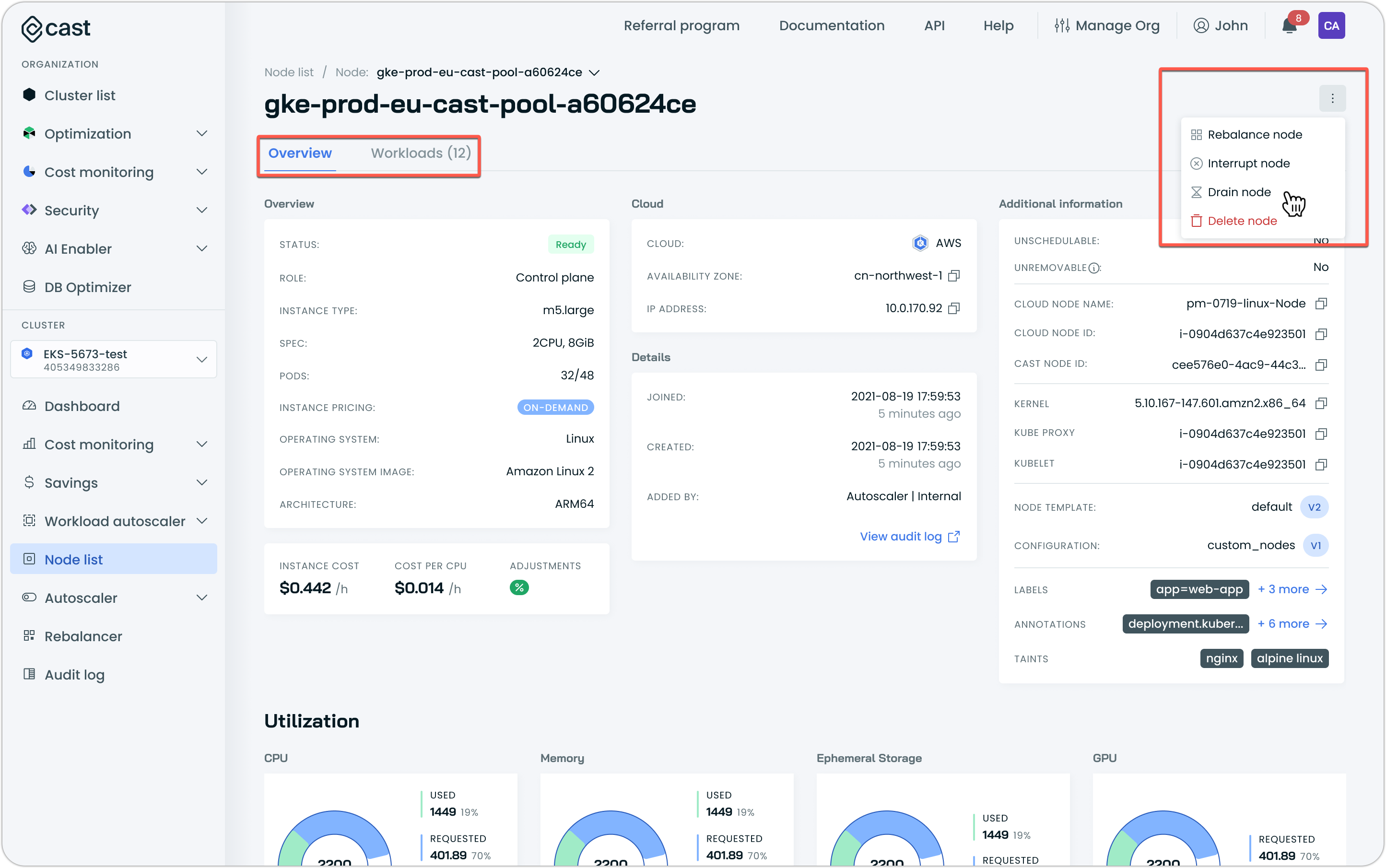
Node details page, accessible from the Node list
Workload Autoscaler Indicator in Cluster List
The cluster list now displays whether Workload Autoscaler is enabled for each cluster through a visual indicator in the Features column. This indicator is also available as a filter option, making it easier to identify clusters using Workload Autoscaler across your organization.

Cluster list showing Workload Autoscaler among the features enabled for a cluster
Search Functionality in AI Enabler Model Library
The Model Library page in AI Enabler now includes a search bar, allowing users to quickly find specific models by entering keywords. No more manually scrolling through the model catalogue or using browser search functionality.
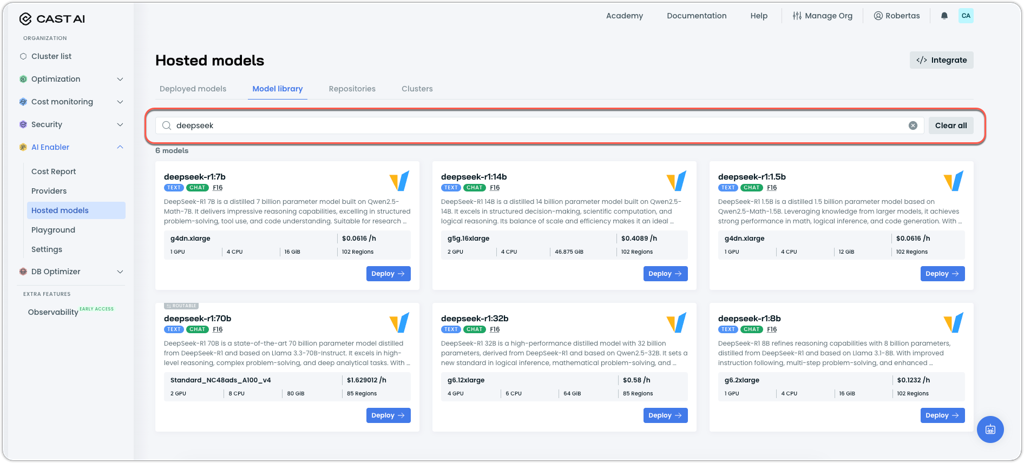
AI Enabler's hosted model deployment library with a search bar up top
Improved Endpoint Configuration Management
Database Optimizer cache configuration now displays endpoint information in a more user-friendly layout for accessing and copying connection details. The cache configuration drawer includes an Endpoints tab alongside Cache settings, consolidating all connection information in one location. This view provides access to both direct database hostnames and DBO proxy hostnames with dedicated copy buttons for each value.
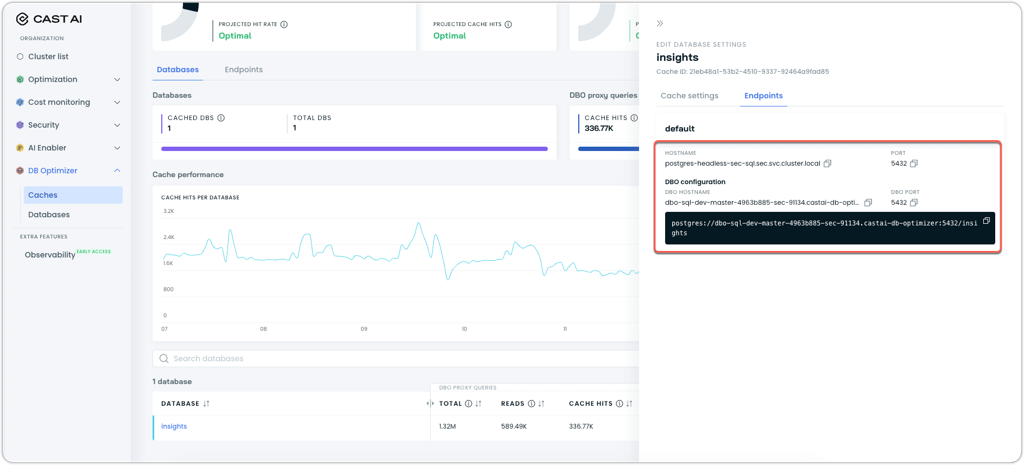
Database settings drawer showing the Endpoints tab with conveniently split connection strings
Simplified Enterprise Overview Access
The organization dropdown now allows direct access to Enterprise Overview by clicking on the Enterprise organization name.
Editable Names for Auto-Generated Node Templates
Auto-generated node templates now support name customization during the creation process. Users can review and modify template names in the generation preview before adding them to their cluster, which was not possible before.
Updated Rebalancing Interface
The Rebalancer now features an updated interface with improved navigation and configuration options. The new layout includes separate Nodes and Workloads tabs for visibility into affected resources and their impact on savings.
Users can now also customize aggressive mode behavior through a dedicated configuration dialog that allows fine-grained selection of which pod types to include during rebalancing.
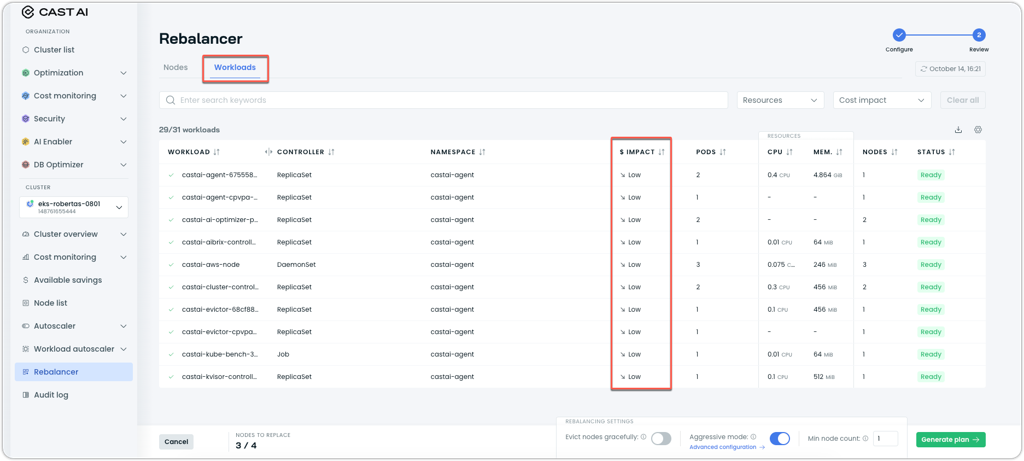
Rebalancing plan with the new Workloads tab selected
Billing Report QoL Improvements
The billing report now uses clearer terminology and hover tooltips for CPU metrics and handles long cluster names more gracefully with truncation.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.