
August 2024
Storage Cost Reporting, StatefulSet Optimization, and Enhanced Cloud Provider Support
Major Features and Improvements
Storage Cost Reporting
CAST AI now offers comprehensive storage cost and utilization reporting. This enhancement delivers crucial insights into your Kubernetes cluster's storage expenses and usage patterns, enabling more effective resource management and cost optimization.
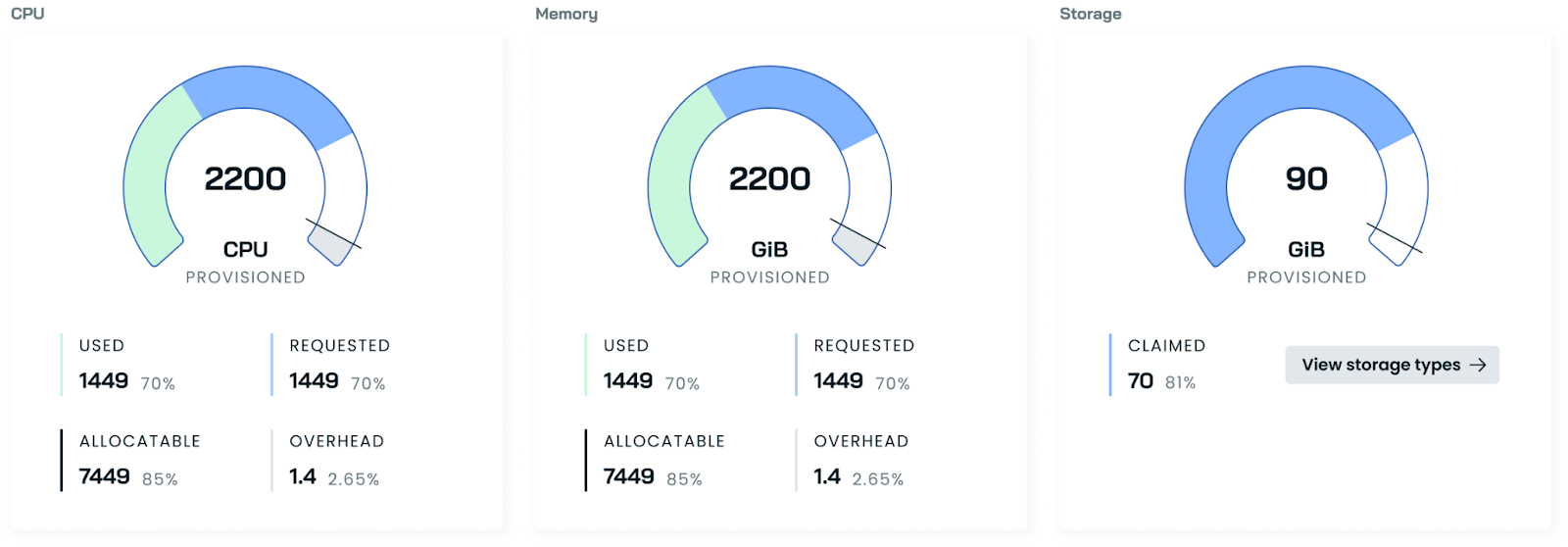
Key features:
- View provisioned and claimed storage metrics in the cluster dashboard
- Track storage costs alongside compute costs in cluster and workload reports
- Identify storage over-provisioning in the Efficiency tab
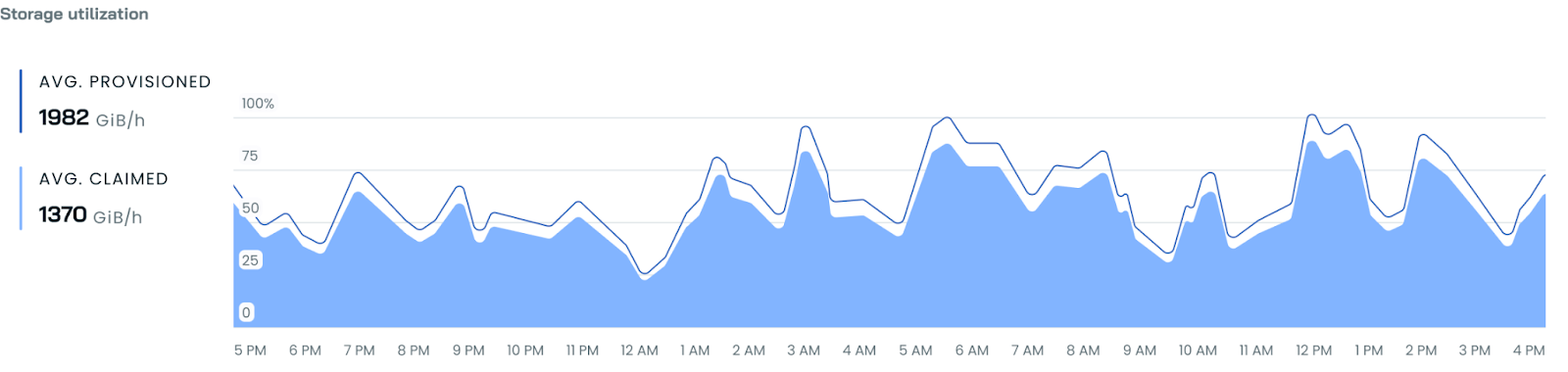
Currently supported for GCP persistent block storage. We're actively working on expanding support to other cloud providers and storage types.
StatefulSet Support in Workload Optimizer
StatefulSet Support in Workload OptimizerWe're excited to introduce support for StatefulSets in our Workload Optimizer. This feature is currently available to select customers.
Key aspects:
StatefulSetsare now supported for both Horizontal Pod Autoscaling (HPA) and Vertical Pod Autoscaling (VPA)- New default scaling policy for
StatefulSetswith deferred apply type to minimize disruptions - Compatible with existing autoscaling modes and policies
This enhancement expands our optimization capabilities to a broader range of workloads, allowing for more comprehensive cluster management.
Azure Preview Instances and Customer-Specific Instance Constraints
We've expanded our support for Azure instances and added new customization options:
- Azure Preview Instances: CAST AI now supports Azure Preview Instances, allowing customers to access early hardware at reduced prices and optimize their clusters for additional savings.
- Customer-Specific Instance Constraint: A new "Customer specific" constraint has been added to Node Templates for Azure Kubernetes Service (AKS) clusters. This opt-in feature allows users to include instances exclusively available to their account, such as preview instances or other specially arranged hardware.
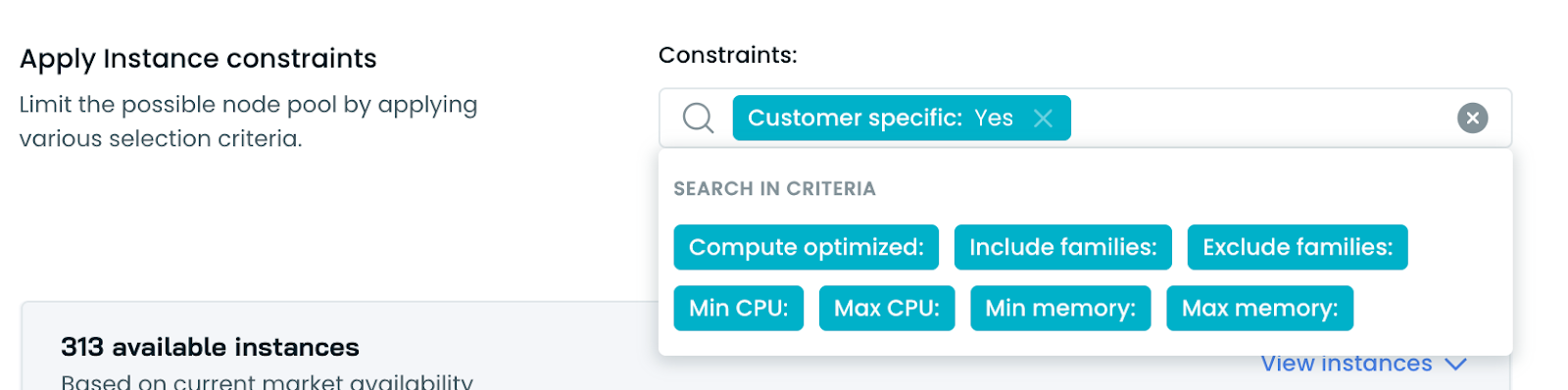
These additions provide more flexibility in instance selection and potential cost savings for Azure users. The Customer-Specific constraint is disabled by default and must be explicitly enabled to use these exclusive instances.
Optimization and Cost Management
Enhanced Node Selection for Scheduled Cluster Rebalancing
We've introduced new options for node selection in cluster rebalancing schedules, giving you more control over how your clusters optimize resource usage and costs. You can now choose from three node selection algorithms:

This flexibility allows you to tailor your rebalancing strategy to your specific needs, whether you're prioritizing cost efficiency, resource utilization, or a balance of both. The new options are beneficial for addressing scenarios with uneven resource utilization or when dealing with nodes that have similar pricing but different usage patterns. The feature is available via API and in the CAST AI console.
Remember that the Least utilized option may not be optimal for spot instances, where price optimization is typically prioritized over utilization.
Cost Anomaly Indicators in Cluster Reports
We've added indicators for cost anomalies directly in the cluster cost reports. When you receive an anomaly notification, you'll see a clear marker on the cost graph, pinpointing exactly when the anomaly occurred. This allows for quicker identification and investigation of unusual cost patterns, improving your ability to manage and optimize cluster expenses.
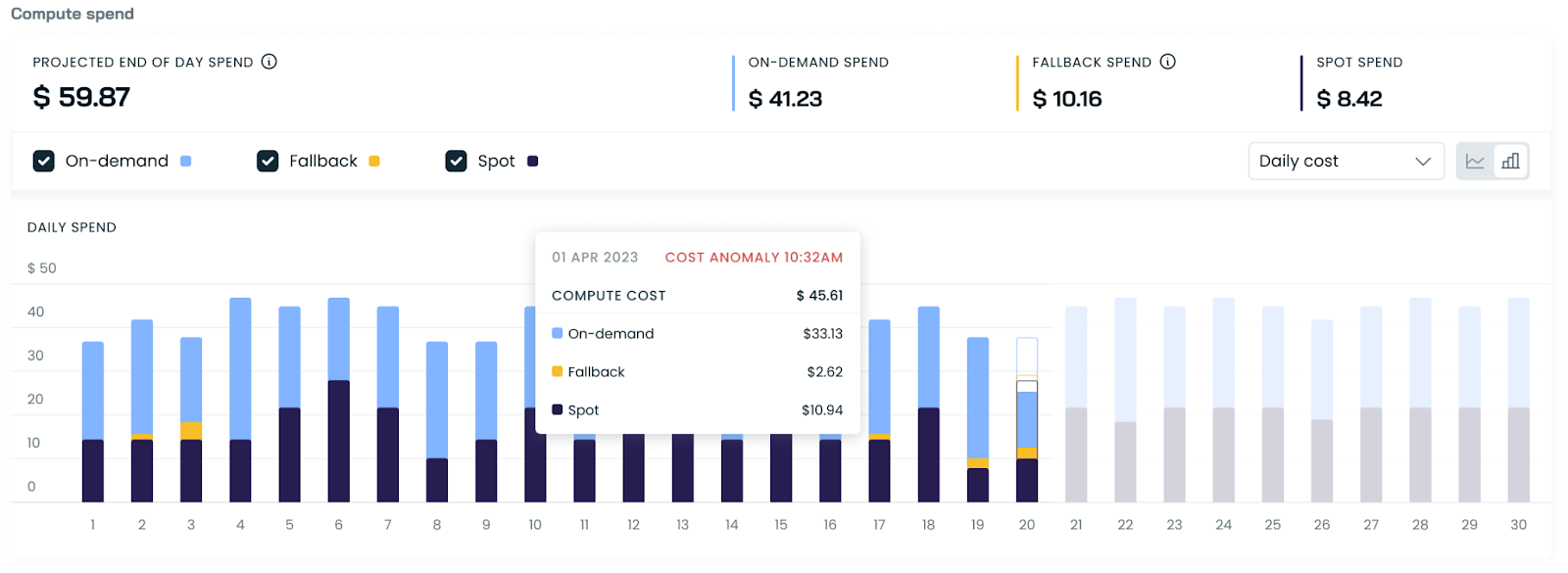
This new addition provides visibility into cost anomalies at a glance, helping you quickly identify and investigate unusual spending patterns in your clusters.
Extended Time Range for Cluster Reports
We've expanded the time range for cluster and organization-level reports fetched via API from 33 days to 3 months. This enhancement allows for more comprehensive long-term analysis and trend identification across various report types, including network costs and efficiency reports. Data granularity adjusts automatically for optimal performance with longer time ranges.
Improved AWS Spot Instance Interruption Handling
We've optimized our response to AWS spot instance interruptions by removing the 90-second delay before initiating node replacement. This change aligns our AWS spot handling with other cloud providers, allowing for faster node replacement and improving the chances of graceful workload shutdown during spot interruptions.
New Rebalancing Mode: Aggressive Mode
We're excited to introduce Aggressive Mode in our rebalancer, allowing you to forcefully roll problematic nodes that would normally be skipped. This feature is perfect for customers who need to ensure strict compliance, even if it means accepting some operational risk. Aggressive Mode makes sure that all nodes in the cluster are updated, maintaining alignment with compliance requirements.

Node Configuration
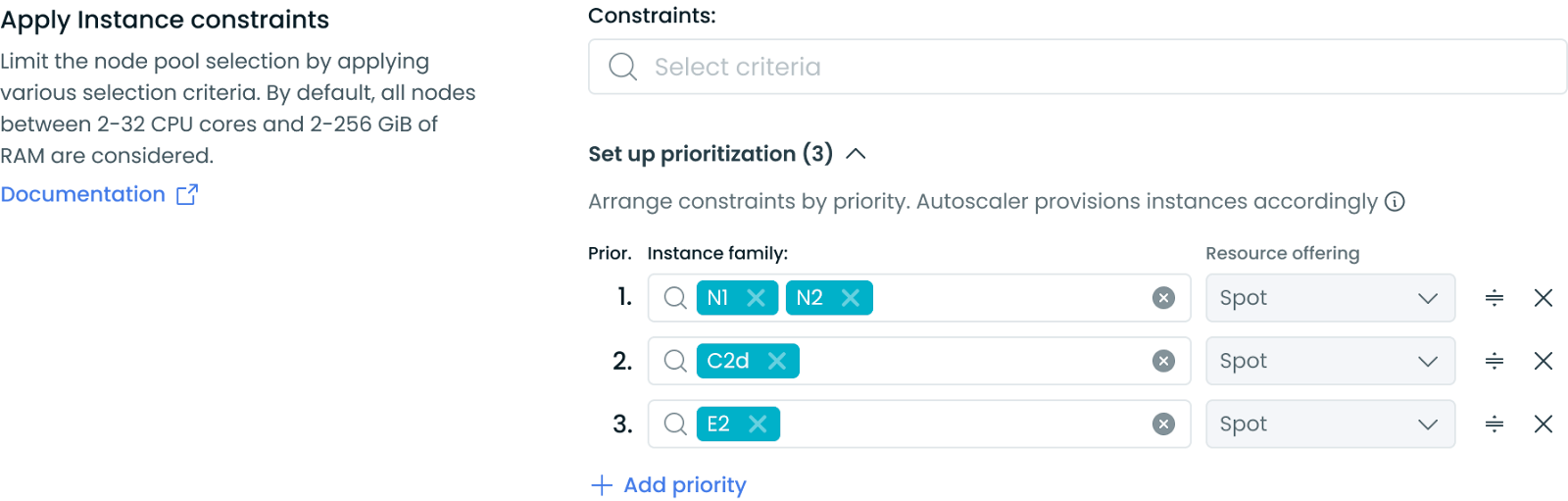
Prioritized Instance Families in Node Templates
We've introduced support for prioritizing instance families in node templates, catering to customers prioritizing performance over cost. This new feature allows you to define a specific order of instance families based on your performance testing results. The system will attempt to schedule workloads on the highest-priority instance family first. If capacity is full or unavailable, it will move to the next in the defined order, ensuring your workloads run on the most suitable instances for optimal performance, regardless of price.
Windows Server 2022 Support for AKS Clusters
We've expanded our support for Windows workloads in Azure Kubernetes Service (AKS) clusters to include Windows Server 2022. This enhancement allows for greater flexibility in running Windows containers within your Kubernetes environments.
Workload Optimization
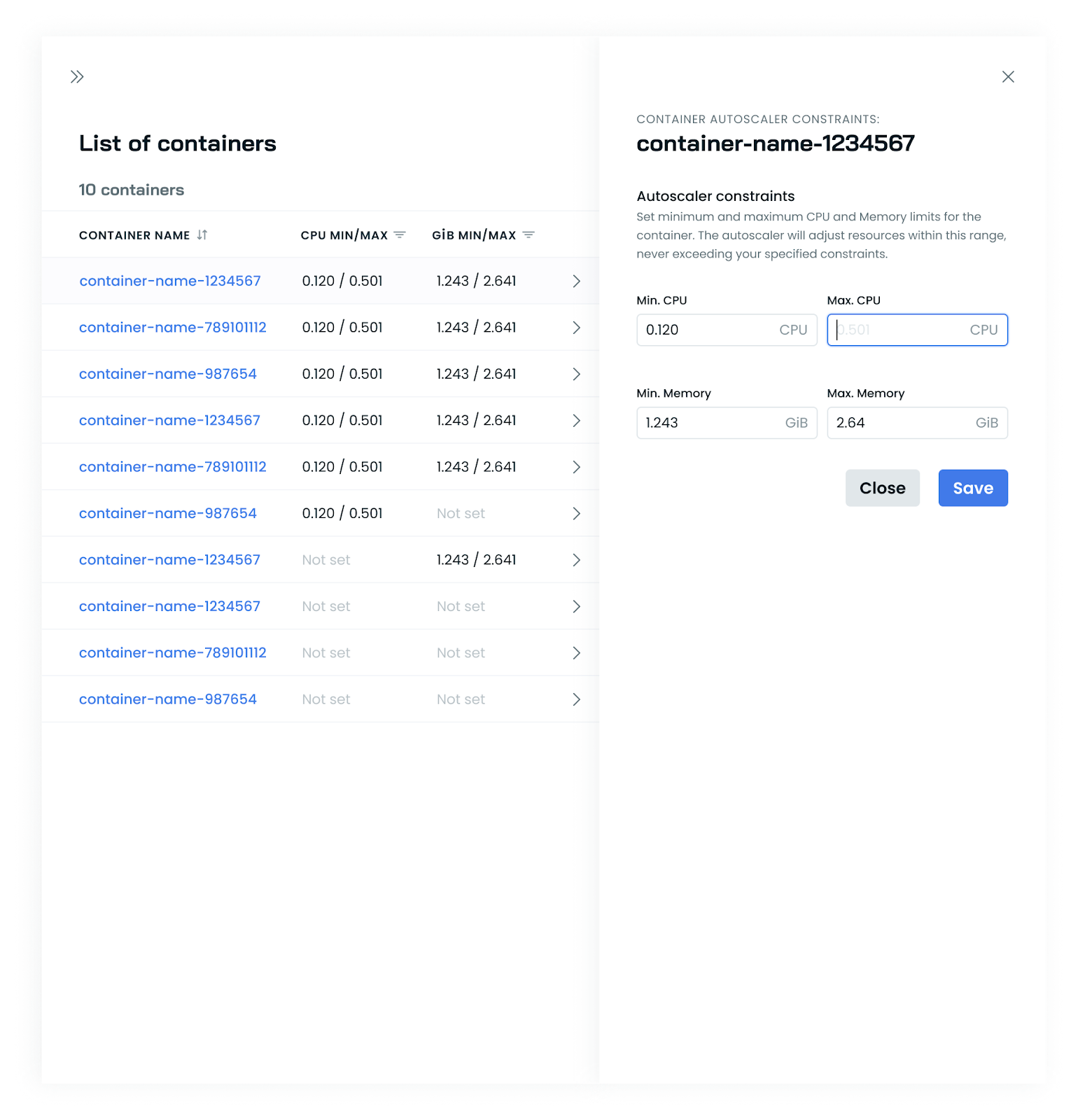
Container-Level Constraints for Workload Optimization
Our Workload Optimizer now supports setting constraints at the individual container level within a pod. This enhancement allows for more precise resource allocation for multi-container workloads, especially beneficial for applications with diverse container resource needs. By tailoring constraints to each container, you can achieve better resource utilization and potentially reduce costs while maintaining optimal performance across your applications.
Workload-Level Scaling Policy Editing
We've added the ability to edit scaling policies directly from the workload view. An edit button now appears next to each workload's scaling policy, allowing for quick adjustments without navigating away from the workload context.
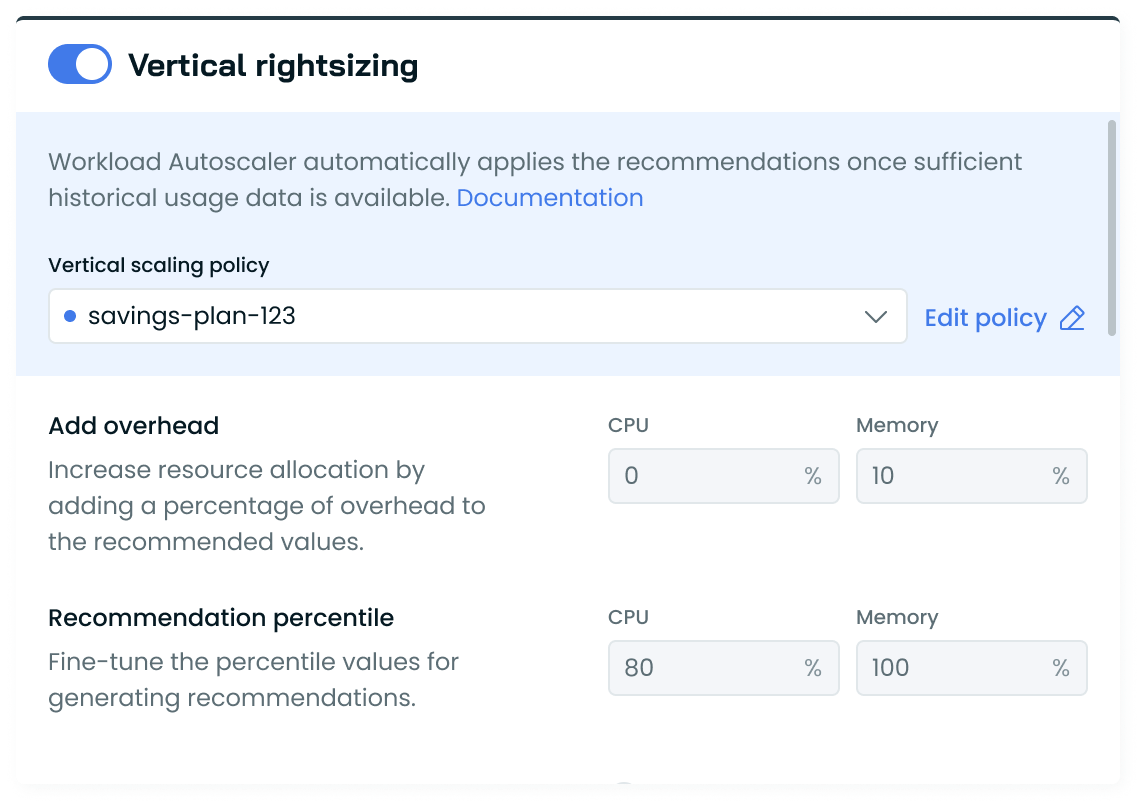
This streamlines the process of fine-tuning your autoscaling settings, making it easier to optimize individual workloads. Note that read-only policies do not have this edit option, maintaining proper access control.
API Update: Optional Startup Period Setting
The updateworkloadscalingpolicy API endpoint now includes an optional periodSeconds field, which defines the duration of increased resource usage during startup. When set, recommendations will adjust to ignore startup spikes, ensuring more accurate resource recommendations. If not specified, recommendations will be based on regular execution patterns.
Infrastructure as Code
Terraform Support for Workload Autoscaler
We're excited to introduce full Terraform support for Workload Autoscaler, making managing and automating your scaling configurations easier than ever. With this update, you can use Terraform to create, update, and delete scaling policies directly. This includes setting up critical parameters like thresholds, enabling auto-enable settings, and managing the entire policy lifecycle through Terraform.
Additionally, we've updated our AKS, GKE, and EKS Terraform modules to include these Workload Autoscaler resources and an option to install the workload autoscaler. These enhancements streamline the deployment and management of scaling policies across your clusters, allowing you to streamline and move workload autoscaling management to an organizational level.
Security and Compliance
Enhanced Performance for Image Vulnerability Scanning
We've improved the performance of our image vulnerability scanning and reporting processes. This optimization especially benefits organizations with large numbers of container images, providing faster and more efficient vulnerability assessments. The enhancement includes pre-calculation of vulnerability counters, resulting in quicker image list loading and more responsive image overviews. Users will experience noticeably faster access to critical security information, enabling more timely decision-making around container security.
Expanded CA Certificate Support Across CAST AI Agents
We've strengthened our security capabilities by expanding private CA certificate support across the CAST AI platform. Previously available only for the CAST AI agent, this crucial feature is now extended to our workload autoscaler, cluster-controller, spot-handler, and evictor components. This advancement ensures that SSL connections within these critical components can seamlessly integrate with private CA certificates, providing enhanced security for customers with stringent compliance requirements.
New Event Tab in Runtime Security
We've added an Event tab to the Runtime Security section, mirroring the functionality found in the anomalies view. This new tab allows users to easily review security events and helps streamline the process of creating custom security rules.
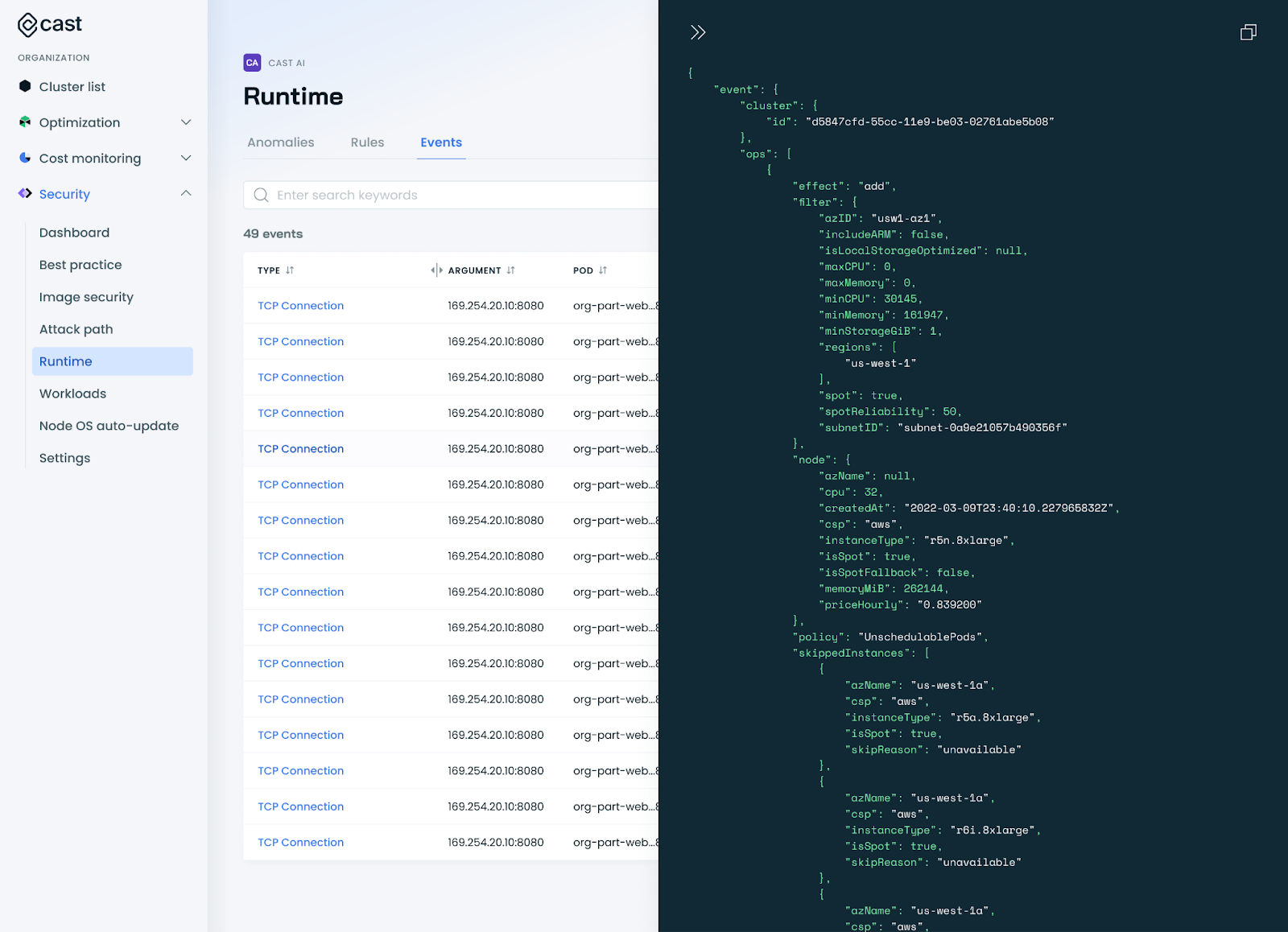
Improved RuntimeSecurityAPI Endpoint
We've updated the RuntimeSecurityAPI to help you retrieve and analyze security events. You can now filter events by date and group results by multiple fields. Paging and sorting are also supported for efficient data handling. For more details, see our API documentation.
API and Metrics Improvements
New Storage Metric: cluster_claimed_disk_bytes
cluster_claimed_disk_bytesWe've added a new storage metric, cluster_claimed_disk_bytes, to our API. This metric is now available in the GetClusterResourceUsage and GetClustersSummary endpoints, allowing you to monitor claimed disk storage across your clusters more effectively.
Improved Namespace Network Cost Reporting
We've updated our NamespaceReportAPI to provide data for network costs. This update introduces a new endpoint specifically designed for retrieving such data: [getClusterNamespaceDataTransferCost](https://docs.cast.ai/reference/namespacereportapi_getclusternamespacedatatransfercost)
Improved ReportMetricsAPI
ReportMetricsAPIWe’ve updated our ReportMetricsAPI to now allow for filtering by cluster. See our API documentation for details.
New Discounts API
We've introduced a new [Discounts API](https://docs.cast.ai/reference/discountsapi_listdiscounts) to expose discount-related functionalities. This API allows you to access and manage discount features directly through our platform.
New GET Endpoint for Individual Commitments
We've added a new GET endpoint for retrieving individual commitments by ID. This update allows users to view the details of a specific commitment, improving the ability to verify and manage commitments more conveniently.
New Workload Network Metrics for Prometheus Endpoints
We've added workload network metrics to Prometheus endpoints, providing organizational-level metrics, including:
workload_network_bytesworkload_to_workload_traffic_bytes
This means that more network-related metrics from egressd are now available, improving visibility and monitoring for network traffic within workloads. For more information, refer to our updated metrics documentation.
User Interface Improvements
Notifications for New Instance Types
We've introduced a new notification system to inform you about the latest instance types available across AWS, Azure, and Google Cloud Platform. This feature ensures you're always aware of new opportunities to optimize your cloud resources:
- In-product notifications when new instance families become available in your active regions
- Webhook support for easy integration with your existing notification systems
- Tailored notifications based on your organization's cloud usage and regions
This feature helps you stay at the forefront of cloud technology, enabling better performance and cost optimization for your Kubernetes clusters.
Improved Side Menu Navigation
We've enhanced the side menu navigation to make it more intuitive and user-friendly. Now, when you hover over any menu icon in the collapsed state, a dropdown card will appear, showing all available options for that section.
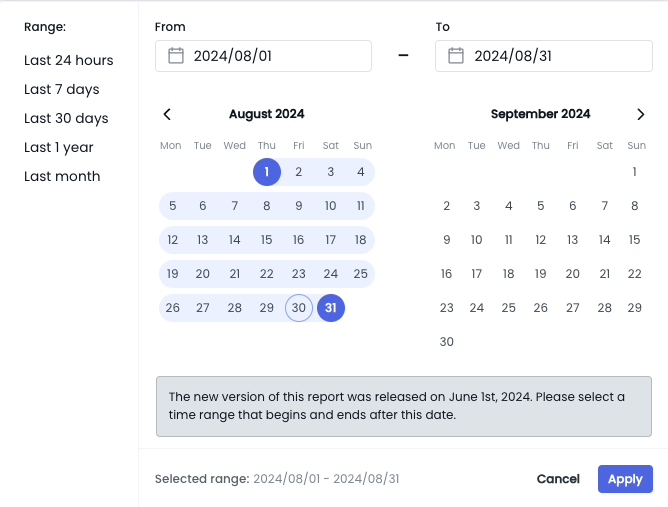
Enhanced Billing Report Date Selection
We've improved the date selection process in the Billing Report to make it easier for you to access commonly needed information. A new "Last Month" option has been added to the date picker, allowing you to quickly view your billing data for the previous calendar month.
Self-Service SSO Setup for OpenID Providers
We’ve expanded our Single Sign-On (SSO) capabilities to include a self-service setup for OpenID providers. This new feature allows users to configure SSO for OpenID in the CAST AI console, similar to the existing process for Azure and Okta integrations. See our SSO documentation for instructions.
Component Updates
Autoscaler Update: Instance Type Selection Based on PV Storage Type
The autoscaler now selects instance types based on the persistent volume (PV) storage type, ensuring that only compatible instance types are chosen. This update also improves grouping to handle conflicting storage types required by different pods. To ensure proper scheduling, the use of pod pinning or taints may be required to match pods with nodes that support the necessary storage type.
Autoscaler Support for Native Sidecar Containers
We've added support for native sidecar containers in our autoscaler, aligning with Kubernetes v1.28's introduction of this feature. This update ensures that autoscaling can now handle pods with native sidecar containers.
Support for topology.kubernetes.io/zone in Pod Anti-Affinity Rules
topology.kubernetes.io/zone in Pod Anti-Affinity RulesIntroduced support for Pod Anti-Affinity on the topology.kubernetes.io/zone key, addressing a critical need for customers requiring zonal distribution of their workloads. This feature ensures that your pods are correctly scheduled across different availability zones, adhering to your anti-affinity rules and preventing unnecessary node creation in the wrong zones.
Enhanced Pod Topology Spread with matchLabelKeys Support
matchLabelKeys SupportWe've expanded our support for Kubernetes pod topology spread constraints to include the matchLabelKeys feature, introduced in Kubernetes 1.27. This addition allows for more flexible and precise control over pod distribution across your cluster. By specifying label keys without values, you can now maintain optimal pod spread during redeployments and updates, ensuring better application resilience and resource utilization. This feature is particularly useful for complex applications that require careful balancing of pods across nodes or zones.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the CAST AI agent. The complete list of changes is here.