
December 2024
Enhanced Reporting, Workload Optimization, and Security Improvements
Workload Optimization
Immediate Apply Mode for Rollouts in Workload Autoscaler
The immediate apply mode for the Workload autoscaler has graduated from feature flag testing and is now generally available. Following successful validation, this feature is enabled by default for Workload autoscaler users.
See our Workload autoscaler documentation.
Container-Level Constraints via Annotations
The Workload autoscaler now supports setting resource constraints at the container level using annotations. This provides more granular control over resource allocation for individual containers within a pod. See the updated documentation before applying this to your workloads.
Resource Limit Management
Resource limits for both CPU and memory can now be configured relative to their requests using annotations or Terraform. This is particularly beneficial for applications using limit-based resource management (like JVM's MaxRAMPercentage), helping prevent issues when applications attempt to scale up to their limit thresholds.
For configuration details, see:
- Terraform: CPU limits, memory limits
- Annotations: Workload Autoscaling Configuration
Support for Argo CD Rollouts in Horizontal Pod Autoscaling
The Workload autoscaler's Horizontal Pod Autoscaling (HPA) capabilities have been expanded to include support for Argo CD Rollouts, enabling automated scaling for progressive delivery deployments.
Improved Workload Sorting
The Workload autoscaler page now uses a simplified, stable sorting approach based on name, kind, and namespace. This replaces the previous sorting logic that caused workloads to shift position when their optimization status changed.
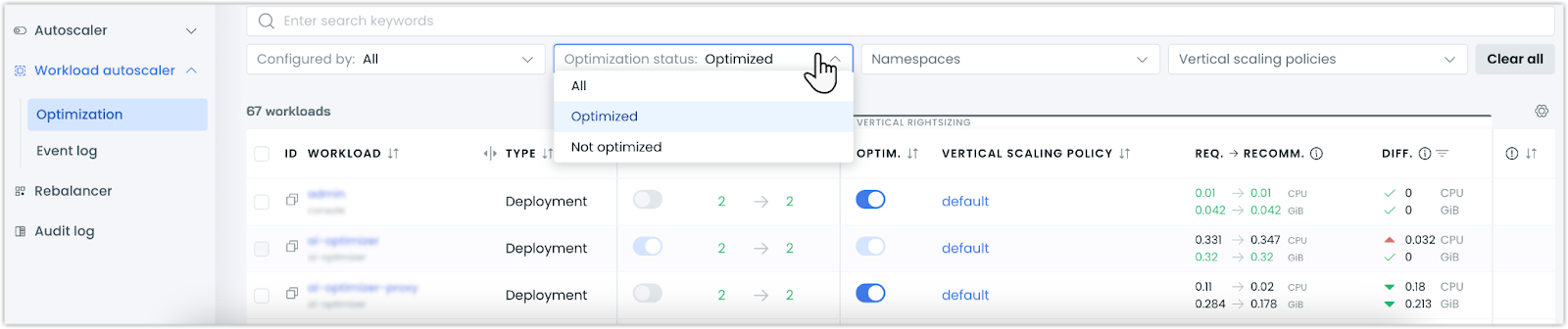
New Optimization Filter for Workloads
The workloads view now includes an optimization filter to sort workloads based on their autoscaling configuration. Users can choose to show only optimized or non-optimized workloads, making it easier to track which workloads are being actively managed by the Workload autoscaler.
Node Configuration
OS Image Family Selection
Node configuration now supports specifying an OS image family (like Amazon Linux 2 or Bottlerocket) instead of exact image versions for AWS and Azure clusters. When an image family is selected, Cast AI automatically uses its latest compatible version, eliminating the need to update image versions when the control plane is upgraded manually.

Required IOPS Field for EKS Provisioned IOPS Volumes
When configuring EKS nodes with io1 or io2 volume types, the IOPS field is now required. This prevents potential node addition failures that might occur when IOPS values are not specified for these Provisioned IOPS volume types.
IPv6 Detection for EKS Clusters
Cast AI now automatically detects IPv6 configuration during EKS cluster onboarding and reconciliation. This ensures proper handling of IPv6-enabled clusters, even when clusters are recreated without going through the re-onboarding process.
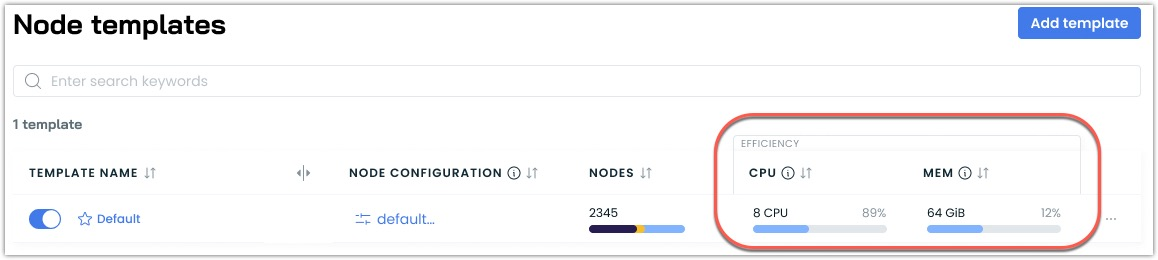
Efficiency Metrics Added to Node Templates
Node template listings now display CPU and memory efficiency metrics calculated across all nodes using each template. This aggregate view helps quickly identify templates that may be contributing to resource overprovisioning.
Security and Compliance
Custom List Integration with Security Rules
The custom list API endpoints have been expanded with two key improvements:
- Initial list entries can now be included during list creation
Using the Create list endpoint:
{
"entries": [
{
"kind": "LIST\_ENTRY\_KIND\_STRING",
"value": "test1"
},
{
"kind": "LIST\_ENTRY\_KIND\_STRING",
"value": "test2"
}
]
}- Security rule details now include information about associated custom lists
Using the GET rules endpoint:
"usedCustomLists": [
{
"id": "string",
"name": "string"
}
]These updates enable better tracking of which custom lists are used in security rules and provide a more streamlined list creation process.
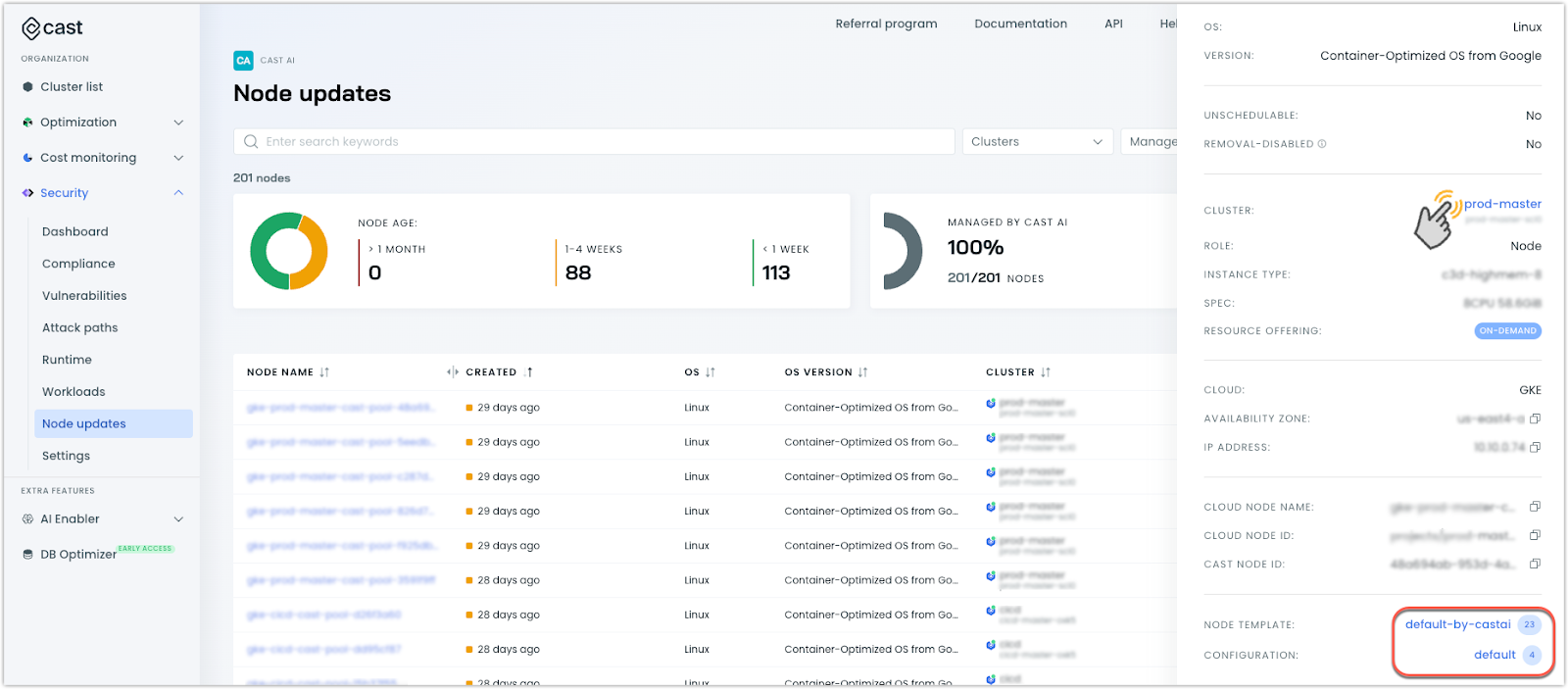
Improved Navigation in Node Updates View
The Node updates page within our Security product now includes direct links to related configurations. When viewing node update details, you can now:
- Navigate to the associated cluster dashboard
- Access node configuration settings or node template details directly from the updated view
These contextual links simplify the verification and management of node-related settings.
Reporting and Cost Management
Extended Time Range for Cluster Reports
The console UI has expanded the time range limit for cluster and organization-level reports from 33 days to 3 months. Data granularity automatically adjusts for optimal performance with longer time ranges—daily aggregation for shorter periods and monthly for ranges over 2 months. The date picker now includes a "Last 3 months" preset option for convenient access to longer-term data.
Hourly Cluster Efficiency Reporting
The time step in cluster efficiency reports has been reduced from 1 day to 1 hour, providing better alignment between efficiency reports and dashboard data. This granular view is particularly valuable for clusters with frequent resource changes. This update affects the /v1/cost-reports/clusters/{clusterId}/efficiency API endpoint and the Cast AI console UI.
Timezone Support for Commitment Usage History Endpoint
The commitment usage history API endpoint (/savings/v1beta/organizations/{organizationId}/commitments/{commitmentId}:getUsageHistory) now supports timezone offsets in time ranges of up to 15-minute increments.
AI Enabler
Added Quantization Information to AI Model Specs
The /ai-optimizer/v1beta/hosted-model-specs API endpoint now includes quantization information for AI models. This field indicates whether a model uses quantized weights for reduced resource usage at the cost of some accuracy.
User Interface Improvements
Improved Error Visibility for Azure Clusters
The platform now consistently exposes all underlying errors when Azure clusters enter a Warning state, similar to how the Failed state is handled.
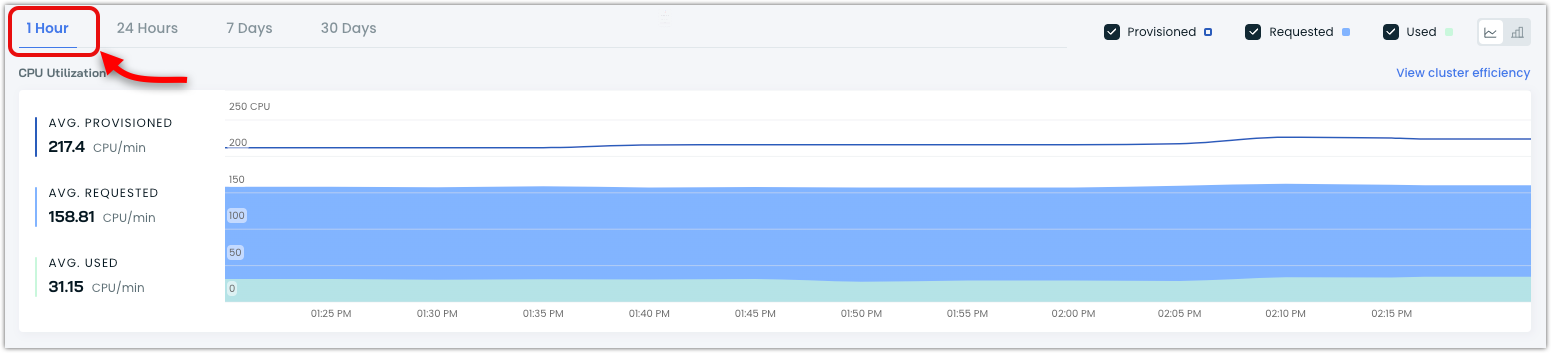
New 1-Hour Timeframe Option in Dashboard
The cluster dashboard's time range selector now includes a 1-hour timeframe option alongside the existing 24-hour, 7-day, and 30-day views. This finer granularity helps monitor immediate cluster changes, which is particularly useful when validating configuration updates.
Updated Default Sorting for Notifications
Notifications are now sorted from newest to oldest by default, eliminating the need to adjust sorting preferences to view recent notifications first manually.
API and Metrics Improvements
Expanded Sorting Options for Organization Efficiency Reports
The organization-level cluster efficiency API now supports additional sorting fields, including:
- Wasted CPU, RAM, and storage
- Requested, provisioned, and used storage metrics
- Cost per storage category (requested, provisioned, used)
See the updated endpoint documentation.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.