
November 2024
Pod Mutations, Workload Autoscaler Annotations v2, and Custom Workload Support
Major Features and Improvements
Introducing Pod Mutations for Simplified Workload Configuration
Pod Mutations streamlines the onboarding and configuration process for Kubernetes workloads. This new feature automates pod setup by offering predefined configurations for labels, tolerations, and topology settings based on Node Templates and other platform features.
Key capabilities include:
- Label-based workload selection and configuration
- Direct integration with Node Templates and Evictor settings
- Support for custom node selectors
The feature benefits organizations managing complex environments by reducing configuration complexity and enabling more efficient resource utilization. It is available in both the console UI and through infrastructure as code.
Head to our docs to learn more about pod mutations.
Reworked Workload Autoscaler Annotations
The Workload Autoscaler now features a simplified annotation structure, consolidating all configuration options under a single workloads.cast.ai/configuration key. This new format:
- Combines vertical and horizontal scaling settings in one clear structure
- Removes dependency on explicit autoscaling flags
- Supports more flexible policy overrides
While the previous annotation format remains supported, new features will be developed exclusively for the new structure. For migration guidance, refer to our updated documentation.
Custom Workload Autoscaling
The Workload Autoscaler now supports custom and programmatically created workloads through label-based selection. This enhancement enables autoscaling for:
- Bare pods and programmatically created pods
- Jobs without parent controllers
- Custom controller workloads
Workloads tagged with the workloads.cast.ai/custom-workload label in their pod template specification can now receive resource recommendations and participate in autoscaling. See guidance in our documentation.
Cloud Provider Integrations
Enhanced Spot Instance Availability Map
The spot instance availability map now includes GPU-specific data points, offering better visibility into GPU instance availability across cloud providers.
EKS: Support for Prefix Delegation
Native support was added for EKS prefix delegation. When this feature is enabled, the autoscaler now handles subnet calculations, ensuring accurate node provisioning within available subnet space. See our documentation for more information.
EKS: IPv6 Support Added
Extended EKS node configuration to support IPv6.
GCP: Updated C4A Instance Specifications
Updated instance metadata for Google Cloud's C4A machine type series to include accurate CPU architectures, manufacturers, and supported disk configurations.
GCP: Load Balancer Configuration Support
Added load balancer configuration options for GCP nodes through API and Terraform. The feature enables direct management of load balancer associations when provisioning GCP nodes.
Check out the updated endpoint or visit our Terraform module docs.
AKS: Support for Multiple Subnet Prefixes
Extended subnet management for AKS clusters to support multiple IPv4 address prefixes within a single subnet. The autoscaler now properly recognizes and utilizes subnets configured with multiple prefixes, enabling more flexible network address management.
AKS: Improved CNI Overlay Network Calculations
The autoscaler now accounts for pod CIDR limitations in AKS clusters using CNI overlay networking. This prevents scaling issues by accurately calculating available IP space when each node requires a /24 network allocation from the pod CIDR range.
AKS: Support for CNI Overlay with Pod CIDR
Added native support for Azure CNI Overlay networking with Pod CIDR configuration. The autoscaler now correctly calculates node capacity based on the available Pod CIDR range, ensuring proper IP address allocation.
Optimization and Cost Management
Phased Rebalancing for Blue/Green Deployments
A new API-driven phased rebalancing capability gives you precise control over cluster node transitions. This feature enables blue/green deployments by pausing the rebalancing process after node cordoning, allowing for custom application migration strategies before final cleanup.
The phased approach includes:
- Initial rebalancing plan creation with node filtering options
- Automated new node provisioning and cordoning of old nodes
- Configurable pause point before drain/deletion phase
This change benefits teams running workloads or applications requiring custom migration procedures.
Improved Startup Handling in Workload Autoscaler
Our Workload Autoscaler now differentiates between startup resource spikes and runtime surges, preventing unnecessary restarts during application initialization. Surge protection automatically extends to cover the specified startup duration for workloads with configured startup settings. Applications without explicit startup configurations receive a default 2-minute grace period.
Global Resource Constraints for Workload Autoscaling
We've introduced global resource constraints in workload autoscaling policies, allowing you to set default minimum and maximum limits for CPU and memory across all containers managed by a policy. These global constraints serve as guardrails while allowing individual workload-level settings to take precedence when specified.
For more information on configuring global constraints, see our Workload Autoscaler documentation.
Enhanced Problematic Node Detection
The rebalancer now identifies nodes that cannot be safely rebalanced, regardless of their workload status, including specific blockers like unknown instance types or removal restrictions. The UI clearly marks these nodes and prevents their selection during rebalancing plan creation, while backend safeguards ensure they remain protected from unintended modifications.
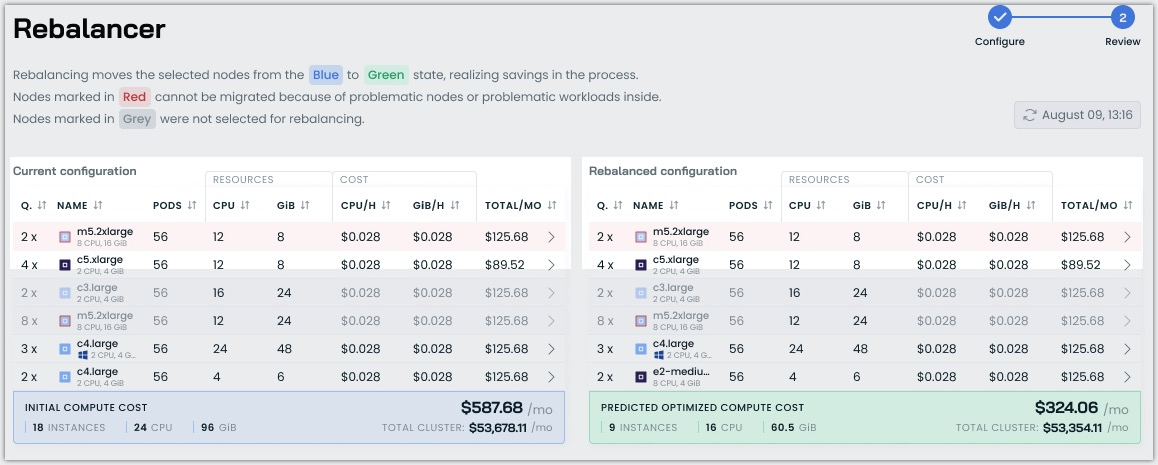
Improved GPU Commitment Handling
The autoscaler now reserves GPU commitment capacity exclusively for GPU workloads, preventing non-GPU workloads from being scheduled on GPU-enabled nodes. This optimization ensures GPU resources remain available for intended workloads and eliminates potential provisioning errors.
Enhanced Rebalancing Plan Visibility
Manual rebalancing now displays full plan details regardless of potential cost impact. Previously hidden negative-savings configurations are now visible, allowing users to evaluate all rebalancing options and make informed decisions based on their specific needs.
Node Configuration
Load Balancer Configuration for AKS
We've added load balancer configuration support for the node configuration API. Users can now specify and manage load balancers and their associated backend pools directly through API, with UI support coming soon. Such configuration is now available for AKS and EKS clusters, which were the first to get this functionality.
Standardized Node Labeling
We began adding a scheduling.cast.ai/on-demand label to nodes provisioned with on-demand instances, completing the set of scheduling labels alongside existing spot labels that we’ve been using so far. This helps improve label-based tracking across systems.
Enhanced Maximum Pods Configuration
We've updated the Maximum Pods formula configuration for custom pod number entries. Users can now directly input their desired maximum pod value instead of using a preset selection, providing greater flexibility in node configuration.

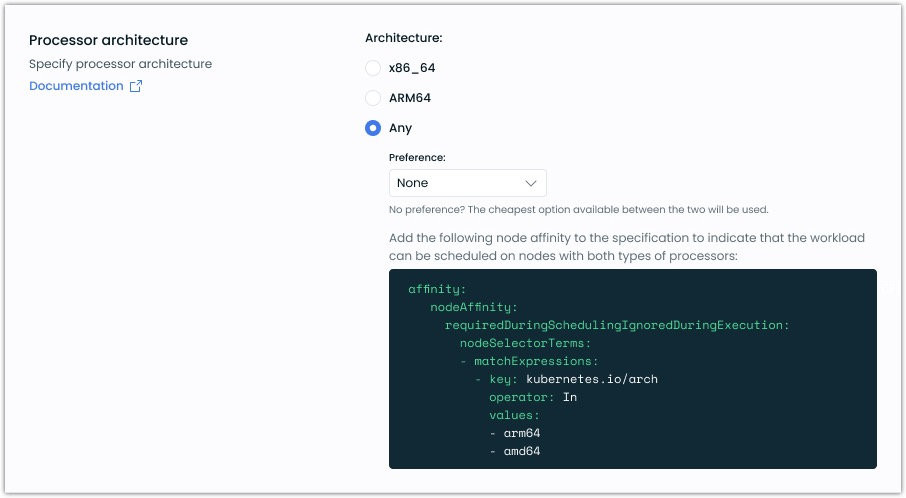
Architecture Prioritization in Node Templates
Node templates now support prioritized CPU architecture selection. When both ARM and x86_64 architectures are enabled, users can specify their preferred order:
- Primary architecture receives priority in node selection
- Secondary architecture serves as a fallback
- Leaving both unprioritized selects the most cost-effective option
Default node templates maintain x86_64 as the preferred architecture for backward compatibility.
Kubernetes Security Posture Management
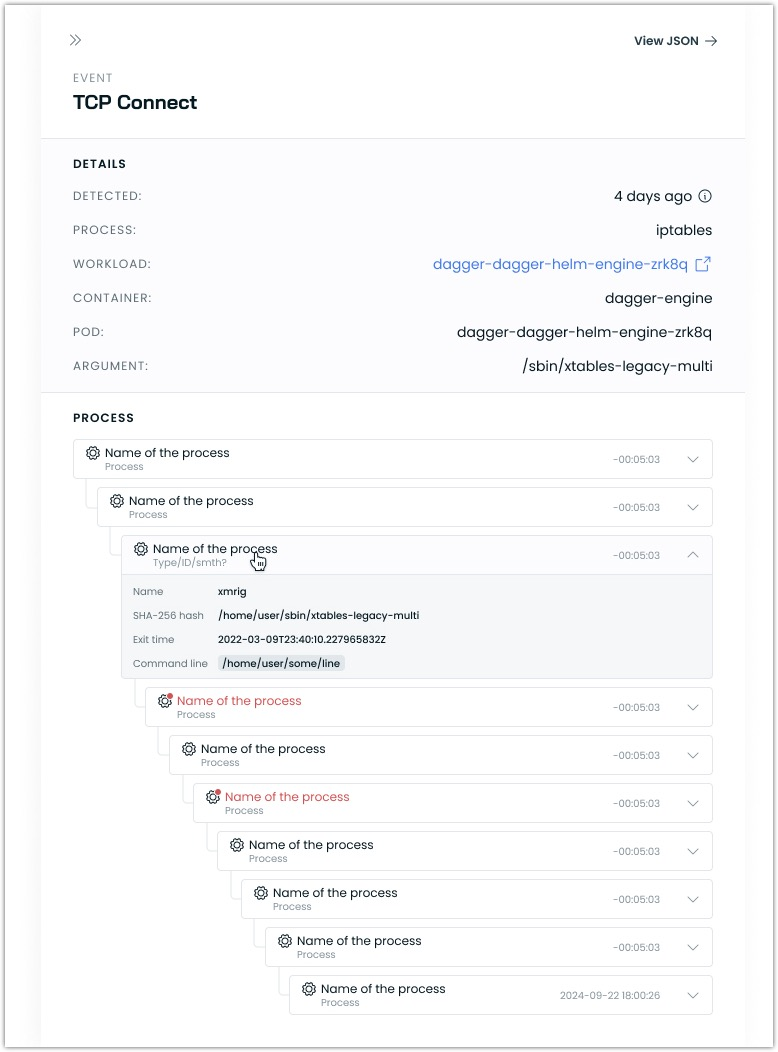
Enhanced Runtime Security Event Details
Runtime security events now include a detailed process tree visualization, providing a better context for security anomalies. This hierarchical view helps trace the relationship between processes involved in security events.
AI Enabler
Streaming Support Added
We've added streaming response support to the AI Enabler LLM Proxy. Enable streaming by setting "stream": true in your request body to receive responses in a streaming format compatible with OpenAI's streaming response structure. See our documentation for guidance.
Support for Llama 3.1 and 3.2 Models
Model deployment options now include Llama 3.1 and Llama 3.2, expanding the available choices for AI workloads.
API Path Update
The proxy-component API endpoint has been updated to a different path and now returns component status for multiple clusters in a single call. Previous single-cluster responses have been updated to return a list format.
See the updated endpoint in the documentation.
Model Cleanup API Endpoint Added
The new endpoint enables the programmatic removal of deployed hosted models and their associated providers. The cleanup process preserves any automatically created node templates for future use.
Configurable Router Quality Settings
Router quality weights can now be configured at both organization and request levels. This setting balances model quality against cost when routing requests:
- Organization-wide default configuration option
- Per-request override capability through the routerQualityWeight parameter
- Scale from 0 (cost-focused) to 1 (quality-focused), defaulting to 0.5
Check out the updated endpoint documentation.
User Interface Improvements
Expanded Workload Autoscaler Event Logs
The Workload Autoscaler event log now includes detailed Horizontal Pod Autoscaling and Vertical Pod Autoscaling-related events, providing better visibility into automated scaling decisions and their impacts.
Standardized Search in Workload Autoscaler Logs
The Workload Autoscaler event log search now includes autocomplete functionality for names and IDs, matching the behavior found in other reporting sections of the platform.
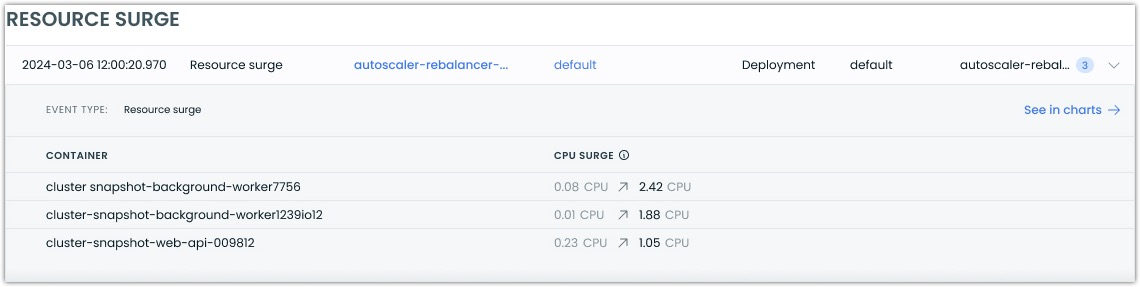
Enhanced Resource Surge Event Details
Resource surge events now display both the original recommendation value and the usage value that triggered the surge, providing a clearer context for scaling decisions.
More Focus on Critical Notifications in the UI
We have listened to customer feedback and updated our console UI to better inform you about any critical notifications you might have missed before. Critical notifications will appear and persist in your cluster list until you actively dismiss them.

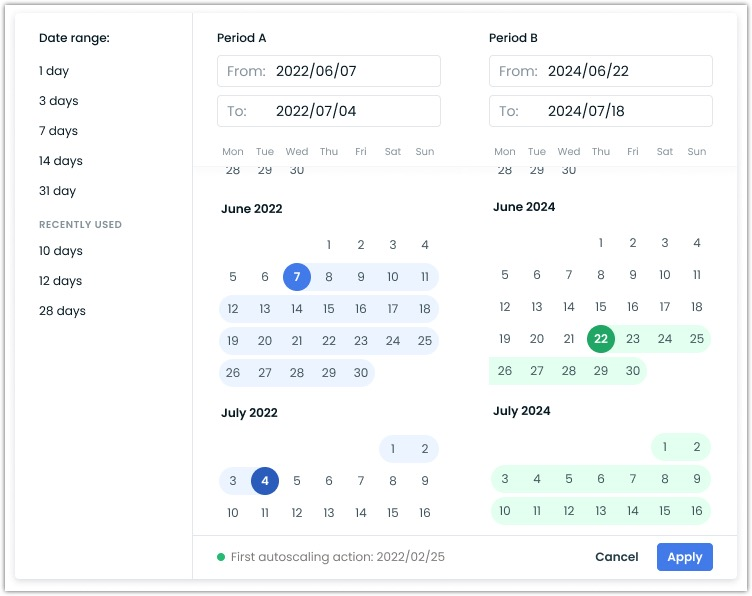
Improved Date Selection across the UI
The Cast AI console interface now features an improved date picker with a more granular time selection. The update enables more precise period analysis and clearer data representation.
API and Metrics Improvements
Resource Usage API Update
We've updated the /v1/cost-reports/clusters/{clusterId}/resource-usage endpoint to support a smaller minimum aggregation interval of 5 minutes for the stepSeconds parameter.
Infrastructure as Code
New Terraform Data Source for Rebalancing Schedules
Added a Terraform data source for rebalancing schedules, enabling better separation between organization-wide and cluster-level configurations. This allows teams to:
- Define rebalancing schedules in organization-level workspaces
- Reference these schedules in cluster-level workspaces
- Avoid naming conflicts across multiple Terraform configurations
See the pull request for more details and updated documentation.
Improved Terraform Credentials Management
The Terraform provider (v7.23.0) introduces credential synchronization between the Terraform state and Cast AI. Key improvements include:
- Automatic drift detection for credential mismatches
- Forced re-application when credentials are reset
These changes prevent state inconsistencies and enable more reliable credential management through infrastructure as code.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the CAST AI agent. The complete list of changes is here.