
August 2025
Enterprise Security Expansion, Commitment-Aware Optimization, and Ever-Improving Workload Autoscaling
We're back with another update featuring numerous significant improvements across security, workload optimization, and cloud provider integrations. This month, we're bringing expanded commitment-aware optimization, most-desired enterprise security features, and what seems like non-stop improvements to our workload autoscaling capabilities here at Cast.
Major Features and Improvements
SSO Group Synchronization
Automated user group synchronization is now available for SSO integrations. This feature enables Identity Provider (IdP) groups to automatically sync with Cast AI user groups, ensuring consistent permission management between your organization's identity system and Cast AI.
Key capabilities include:
- Automated group provisioning: IdP groups are automatically created and maintained in Cast AI, with users inheriting roles and permissions based on their group memberships
- Real-time user management: User additions and removals in your IdP are reflected in Cast AI, ensuring access remains current without manual intervention
- SCIM support: Compatible with all major identity providers
When enabled, the IdP becomes the single source of truth for group membership and user access, automatically handling user lifecycle management and maintaining security compliance.
NoteSSO group synchronization is supported for Okta and Azure AD identity providers and is available for organizations upon request. For setup and guidance, contact your Cast AI Account Manager.
Security and Compliance
Watchdog (Early Access)
Watchdog is a new fallback mechanism for Cast AI-managed GKE clusters that ensures critical workload availability during potential Cast AI outages. It automatically provisions emergency compute capacity when the Cast AI control plane becomes unavailable due to network issues, platform downtime, or misconfigurations.
When Cast AI cannot provision nodes during an outage, Watchdog detects the situation and provisions On-Demand nodes through GCP APIs, bypassing normal placement preferences to prioritize availability over cost optimization. The system works independently of the Cast AI SaaS control plane, ensuring workloads can recover even when Cast AI services are unreachable.
This feature is currently available in Early Access for GKE clusters. Contact Cast AI to enable Watchdog for your organization. Learn more about the feature in our Watchdog documentation.
IP-Based Access Control
Cast AI now supports IP-based access restrictions for security compliance. This feature enables organizations to control access to the Cast platform, API endpoints, and cluster components based on source IP addresses or IP ranges.
Organizations can configure allowlists for specific IP addresses, ensuring that only designated network locations can access Cast services.
IP-based access control is currently available as a managed feature through Cast. Contact your Cast Account Manager to discuss implementation requirements and configuration options for your organization.
Cloud Provider Integrations
AWS
Organization-Level Resource Discovery
Cloud Connect for AWS now supports organization-scope asset synchronization, allowing discovery and monitoring of resources across all member accounts within an AWS Organization. Previously, Cloud Connect required individual account-level setup for each AWS account.
The organization-scope sync automatically provisions the necessary IAM roles across accounts, streamlining the onboarding process for enterprises with multiple AWS accounts under a single organization structure.
Enhanced Default IAM Permissions
Cast AI onboarding scripts and Terraform modules now include additional default IAM policies for improved AWS integration. The instance profile role automatically includes AmazonEBSCSIDriverPolicy for EBS volume provisioning and AmazonSSMManagedInstanceCore for AWS Systems Manager Session Manager access.
These policies enable EBS CSI driver functionality out of the box and support secure node access through Session Manager. Both policies can be disabled if they are not needed in your environment.
This change eliminates manual permission configuration steps that were previously required for full EBS and Session Manager functionality on Cast AI-managed nodes.
GCP
GPU Support for Sole Tenant Node Groups
The Autoscaler now supports GPU-enabled instances within GCP sole tenant node groups. Previously, due to technical limitations, GPU instances were filtered out from sole tenant configurations.
See our documentation on GKE Sole Tenant Node Support.
Azure
Premium Storage Volume Support
The Autoscaler and Evictor now correctly handle pods requiring Azure Premium Storage volumes by ensuring they are scheduled on compatible instance types. Previously, pods with Premium Storage requirements could be placed on instances that don't support Premium Storage (such as A, B, F, or Av2 series), causing volume binding failures.
Cast AI now detects Premium Storage requirements from persistent volume claims and ensures workloads are placed only on instance families that support Premium Storage. This prevents scheduling conflicts and ensures reliable volume attachment for workloads with high-performance storage needs.
Node Configuration
Multiple Pod Subnet Support for Azure AKS
Node configurations for Azure AKS clusters now support specifying individual Pod subnets per node configuration. Previously, all Cast AI-managed nodes used the cluster's default Pod subnet.
This enables more granular control over Pod networking by allowing different node groups to place their Pods in separate subnets.
The Pod subnet configuration is available through both the Cast AI API and Terraform provider, providing consistency with existing GKE multi-subnet capabilities. See our Node Configuration documentation.
Cluster Onboarding
Pod Mutator Default Installation
The Cast AI onboarding script now installs the Pod Mutator component by default during Phase 2 cluster connection. This change ensures all newly onboarded clusters have the necessary components for the complete Cast AI optimization experience without requiring additional manual installation steps.
See our Pod mutations documentation for guidance and examples on how it can benefit your workflow.
Cluster Optimization
Commitment-Aware Rebalancing
The rebalancer now incorporates actual commitment pricing when evaluating rebalancing decisions across all cloud providers. For AWS Savings Plans, Reserved Instances, GCP Committed Use Discounts (CUDs), and Azure Reserved Instances, cost calculations during rebalancing operations now reflect the actual discounted rates rather than list prices, leading to more accurate cost optimization decisions.
This corrects previous behavior, where commitment-covered instances were incorrectly treated as zero-cost. It ensures that rebalancing decisions are based on real-world pricing scenarios where commitments are in use.
Enhanced Drain-Failed Node Management
Scheduled rebalancing now excludes nodes marked with rebalancing.cast.ai/status=drain-failed from rebalancing plans, matching the behavior of manual rebalancing. This prevents repeated attempts to rebalance nodes that have already failed to drain properly, reducing plan failures and timeouts.
Additionally, the cluster dashboard and node list now display warnings when drain-failed nodes are present, alerting users that cluster costs may be increased due to these problematic nodes.
Workload Optimization
Extended Analysis Period for Job-Like Workloads
Workload Autoscaler can now use an extended 30-day lookback period when analyzing job-like custom workloads such as Spark executors, GitLab runners, Tekton TaskRuns, and Argo Workflows. This would provide more accurate rightsizing recommendations for sporadically running workloads that may not have sufficient recent usage data under the standard analysis window.
This capability is currently available as a preview feature. Contact Cast AI support to enable it for your organization.
Improved System Policy Defaults
System scaling policies now feature improved default settings for better optimization performance. Per customer feedback, the lookback period has been adjusted to 3 days, and startup metrics are ignored for 2 minutes by default across all system policies.
Additionally, job-like workloads in newly onboarded clusters now automatically receive assignment to the "Burstable" scaling policy through assignment rules. This default configuration includes a 7-day lookback period optimized for the sporadic execution patterns typical of these types of workloads.
LimitRange Integration
The Workload Autoscaler now respects Kubernetes LimitRanges when generating resource recommendations, ensuring workloads remain compliant with namespace-level resource policies. This prevents pod creation failures that would occur when autoscaler recommendations conflict with LimitRange constraints.
The integration handles default limits, minimum and maximum resource constraints, and limit-to-request ratios defined in LimitRanges. When conflicts arise between autoscaler settings and LimitRange policies, the most restrictive constraint is applied to maintain workload schedulability.
See Workload Autoscaler documentation for more information.
Memory-Based HPA Coordination
Workload Autoscaler now automatically coordinates with memory-based Horizontal Pod Autoscalers (HPAs) to prevent conflicts between vertical and horizontal scaling decisions. When workloads use both vertical scaling and memory-based HPA, the system automatically adjusts memory requests to keep typical usage below the HPA's scaling threshold.
This prevents scenarios where vertical scaling optimizations could inadvertently trigger premature HPA scaling events, ensuring both scaling mechanisms work together smoothly. The coordination happens automatically in the background without requiring changes to existing HPA configurations or vertical scaling policies.
For more information, see Workload Autoscaler documentation.
Keep Existing Resource Limits Option
Workload resource limit settings now include a "Keep existing resource limits" option for both CPU and memory configurations. This setting preserves any existing resource limits defined in workload manifests while still allowing the Workload Autoscaler to optimize resource requests.
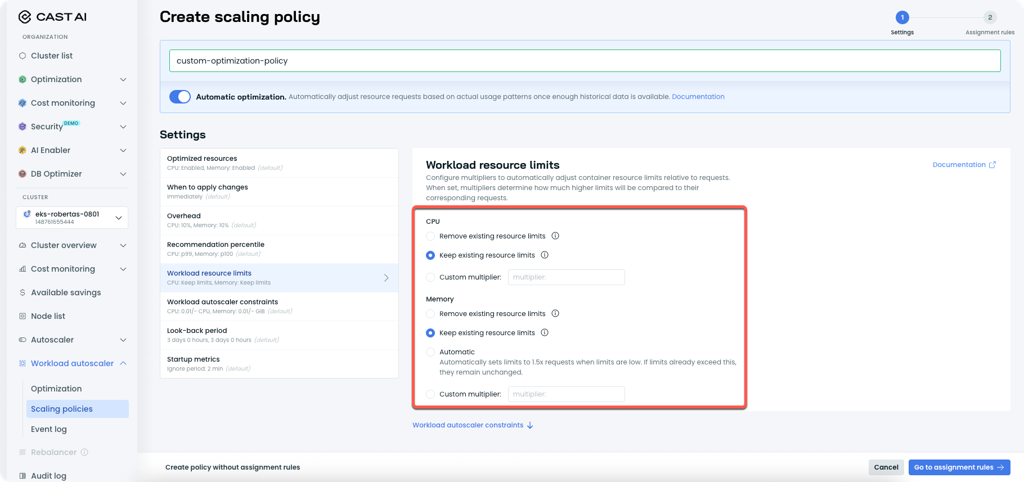
"Keep existing resource limits" in scaling policy settings
See the updated Workload Autoscaler documentation for details.
Terraform Scaling Policy Deletion
The Terraform provider now allows the deletion of Workload Autoscaler scaling policies currently assigned to workloads. Previously, attempting to delete a scaling policy through Terraform would fail if any workloads were using that policy, requiring manual workload reassignment before cleanup could proceed.
User Interface Improvements
Enhanced Commitments UI
The Commitments page now features tabs that organize commitment types for easier navigation. The updated design separates Reserved Instances, Savings Plans, and Resource-based commitments into dedicated tabs, each displaying relevant utilization metrics and commitment details.
This reorganization improves the ability to analyze different commitment types independently while maintaining a comprehensive overview of total utilization across all commitment categories.
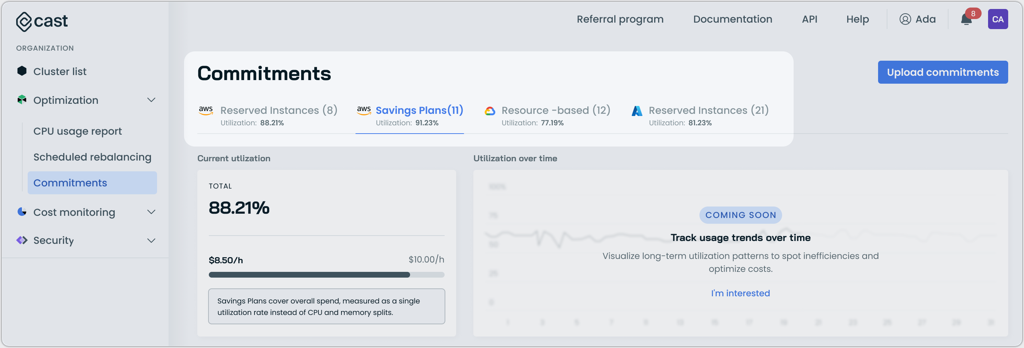
Updated "Commitments" interface with tabbed commitment separation
Workload Autoscaler Resource Summary Uplift
The Workload Autoscaler’s Optimization page now displays an improved resource summary section with visual enhancements for tracking CPU and memory optimization. The updated interface includes historical resource charts showing recommendations, requests, original requests, and actual usage data alongside summary bars displaying the latest metrics.
The resource summary provides multiple time range options from 15 minutes to 30 days, allowing teams to analyze workload optimization trends across different periods and better understand the impact of autoscaling recommendations on their applications.
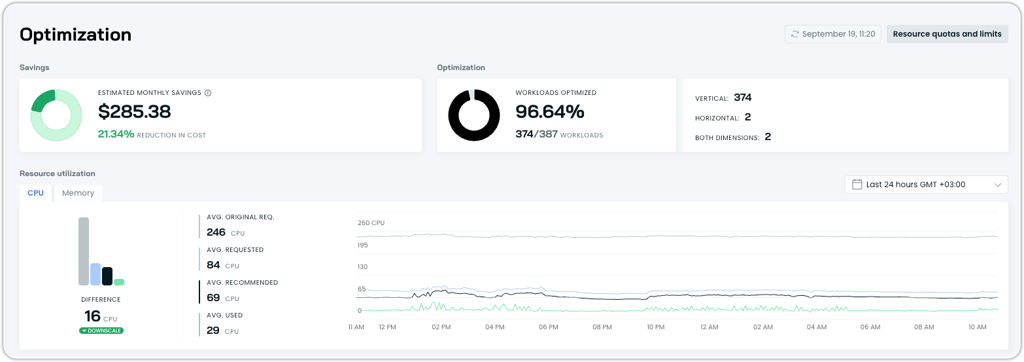
Uplifted "Resource utilization" visuals in the Optimization page
Native HPA Configuration Display
The Workload Autoscaler interface now displays the actual configuration values from native Kubernetes Horizontal Pod Autoscaler (HPA) when detected on workloads. The interface shows HPA settings such as minimum and maximum pod counts, CPU utilization targets, and other scaling parameters directly within the workload details.
This provides visibility into existing HPA configurations without requiring users to check Kubernetes manifests separately, making it easier to understand and coordinate between native HPA policies and Cast AI's optimization recommendations, which are shown side-by-side.
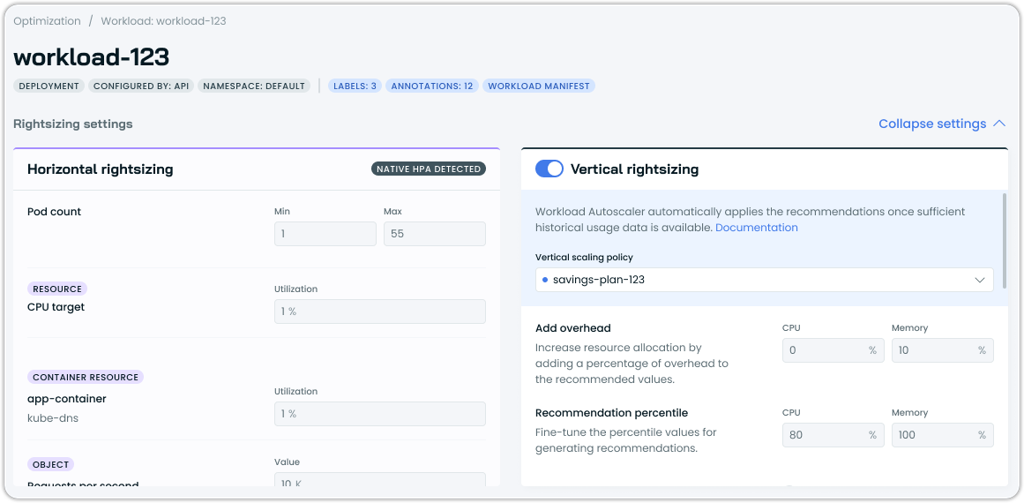
Updated workload interface showing configured HPA values
Enhanced Audit Log Error Clarity
The audit log now provides clearer context for node provisioning failures by distinguishing between general provisioning errors and insufficient capacity errors. When node addition fails due to cloud provider capacity constraints, the audit log displays specific messaging to indicate these are expected operational events rather than system failures.
Scaling Policy Deletion with Workload Reassignment
The console now allows deletion of custom scaling policies that have assigned workloads through an updated deletion workflow. When deleting a policy with active workloads, the system automatically reassigns those workloads to appropriate policies based on assignment rules or to the default policy if no rules match.
Workload Manifest in the UI
The workload page now includes a manifest viewer that displays the complete YAML configuration for any workload. Users can access this by clicking the "Manifest" chip in the workload interface for immediate access to the full Kubernetes resource definition.
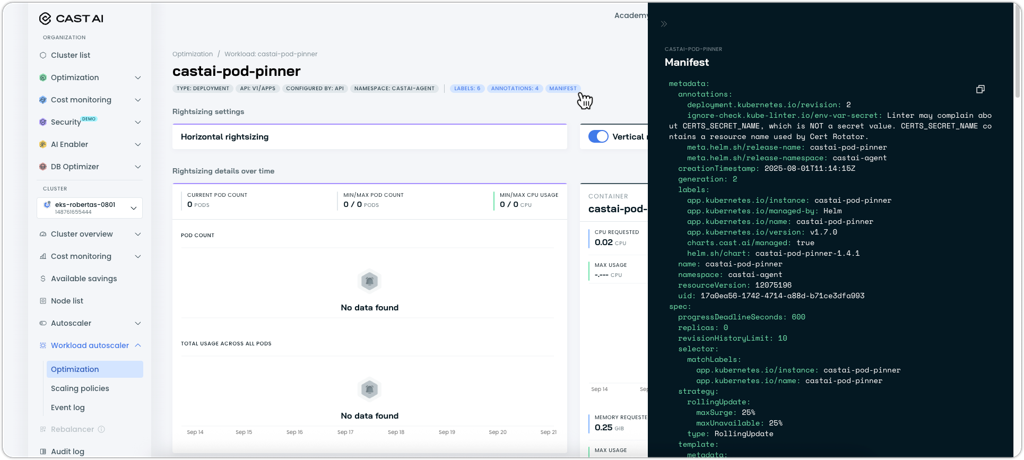
Updated workload view showing the new "Manifest" chip and resulting YAML drawer
Enterprise Management Interface Refinements
The Enterprise management UI received several usability improvements for navigating child organizations and managing enterprise-wide resources. Updates include improved navigation flow for child organization overview pages, refined billing chart behavior for smoother data visualization transitions, and updated user group creation dialogs with better organization sorting and external link handling.
Cost Monitoring
Anywhere Clusters in Billing Report
Cast AI Anywhere clusters now appear in the billing report, providing complete cost visibility across all cluster types in your organization.
Database Optimization
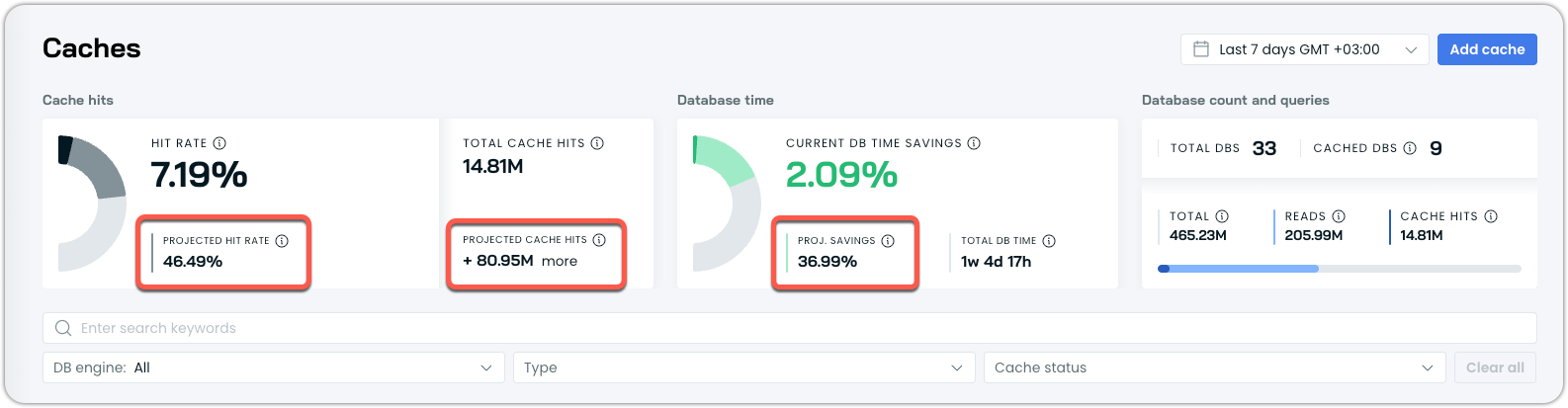
Enhanced Passthrough Mode
Passthrough mode was enhanced to calculate a projected cache hit rate, which is now available even before the cache is deployed. In addition, the system also estimates projected time savings. This data is available both per database and at the individual query level, allowing customers to gain deeper insights into which queries are considered cacheable and what savings enabling DBO would bring.
AI Enabler
Embedding Models Support
AI Enabler now supports the deployment and serving of embedding models, expanding beyond traditional language models to include vector representation capabilities. The platform supports multiple embedding model architectures.
The models are accessible through the standard OpenAI-compatible /v1/embeddings endpoint, maintaining compatibility with existing embedding workflows and toolchains.
The model catalog has been updated to clearly display embedding model capabilities alongside traditional language models, allowing users to select the appropriate model type for their specific use cases.
Multi-Modal Model Support with Image Input
AI Enabler now supports multi-modal models that can process both text and image inputs within the same request. The platform currently supports Facebook Chameleon-7B, Microsoft Phi-3.5-vision-instruct, gemma-3-4b-it, and gemma-3-27b-it models.
Multi-modal requests use the same chat completion endpoints as text-only models, maintaining compatibility with existing API workflows. This capability enables applications such as document analysis, visual question answering, and content generation that incorporate both visual and textual context.
The multi-modal models are accessible through the standard model catalog and can be deployed with the same autoscaling and resource management features as traditional language models.
Model Catalog Updates
This month, additional model variants were added to the catalog, including quantized versions such as FP8-quantized Llama 3.1 8B Instruct and other optimized configurations based on customer requirements. For the complete list of available models, see the AI Enabler documentation, which includes instructions for querying the API endpoint with the most up-to-date model catalog.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.