
Vertical & horizontal workload autoscaling
In Kubernetes, running workloads with both Vertical Pod Autoscaling (VPA) and Horizontal Pod Autoscaling (HPA) turned on at the same time can be challenging. VPA adjusts the resources allocated to individual pods while HPA changes the number of pod replicas – when operating independently, these mechanisms can work against each other. For example, VPA might increase resources per pod while HPA tries to scale down the number of pods, or vice versa, leading to sub-optimal resource allocation and potential issues.
Cast AI has developed a unique approach to ensure these scaling mechanisms work together harmoniously for CPU scaling. Rather than letting them potentially conflict, our Workload Autoscaler automatically adjusts its behavior in the background to optimize resource allocation of workloads that are being scaled horizontally and vertically at the same time.
How it works
Workload Autoscaler recognizes two distinct workload patterns and applies different optimization strategies for each. This works when combining both Kubernetes native HPA or Cast AI's proprietary horizontal workload autoscaling with Cast AI's vertical workload scaling.
When Workload Autoscaler detects that a workload's resource allocation is significantly different from optimal targets, it makes direct adjustments to reach the optimal allocation immediately.
Replica target correction for stable workloads
For workloads with consistent CPU usage patterns, Workload Autoscaler dynamically balances vertical and horizontal scaling to maintain optimal performance. The system calculates an ideal target replica count from your configured horizontal scaling range, aiming to run at roughly 10% of the available replica budget + minReplicas count during normal operation. This target serves as a baseline for making vertical scaling decisions.
To maintain this balance, Workload Autoscaler continuously monitors pod counts averaged over recent hours. When it observes the workload running with more replicas than the target, it increases vertical resource recommendations to consolidate the workload onto fewer, better-resourced pods. When running below target, it reduces vertical CPU resources to encourage horizontal scaling. This approach ensures both optimal resource allocation and maintains enough capacity for handling sudden load increases.
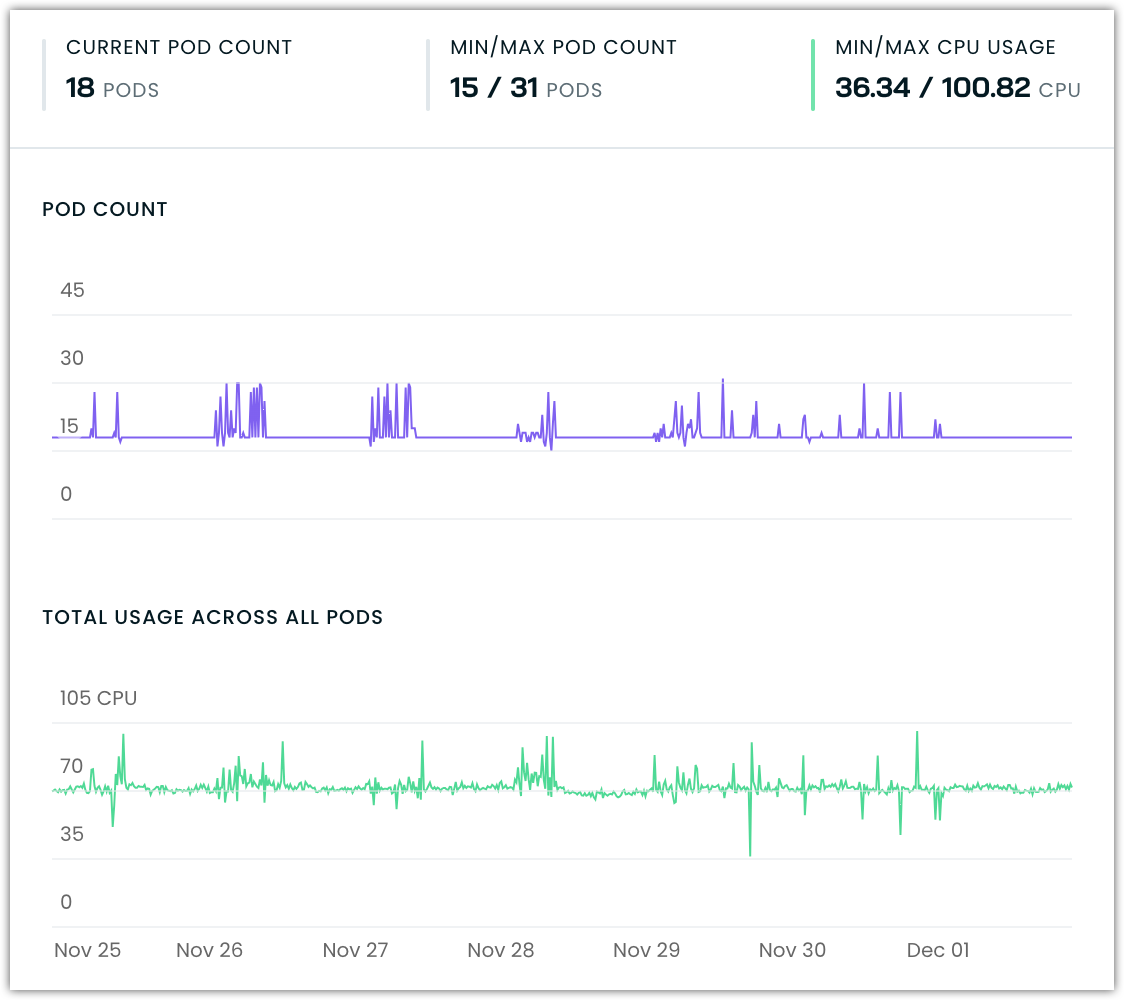
Example of a stable workload
Example
Consider a horizontal scaling configuration allowing 1-11 replicas. This gives Workload Autoscaler a replica budget of 10 pods to work with. The system targets running about 2 replicas during normal operation (~10% of the range + minReplicas of 1 in this example). If the average pod count over recent hours rises above 2, vertical resources are increased to encourage consolidation. If it falls below 2, vertical resources are decreased to promote running more pods.
Seasonal workload optimization
For workloads with predictable patterns or significant load variations, Workload Autoscaler employs a three-tier optimization algorithm.
-
Minimum load distribution
Workload Autoscaler calculates the minimum CPU requirements by dividing the lowest observed total load by minimum replicas:minRequests = minLoad / minReplicas
It then verifies if these minimum requests could handle peak load when scaled to maximum replicas:minRequest * maxReplicas >= maxLoad
If this validation passes, it uses these values for issuing vertical recommendations. -
Current recommendation validation
If minimum load distribution isn't suitable, checks if current per-pod vertical recommendations can handle maximum load when scaled to maximum replicas, maintaining current recommendations if they prove sufficient. -
Maximum load distribution
If neither of the above strategies work, Workload Autoscaler spreads the maximum observed load across maximum replicas. This allows Workload Autoscaler to scale freely between minimum and maximum replicas based on current demand.
This last approach works as a reliable catch-all solution for highly variable workloads.
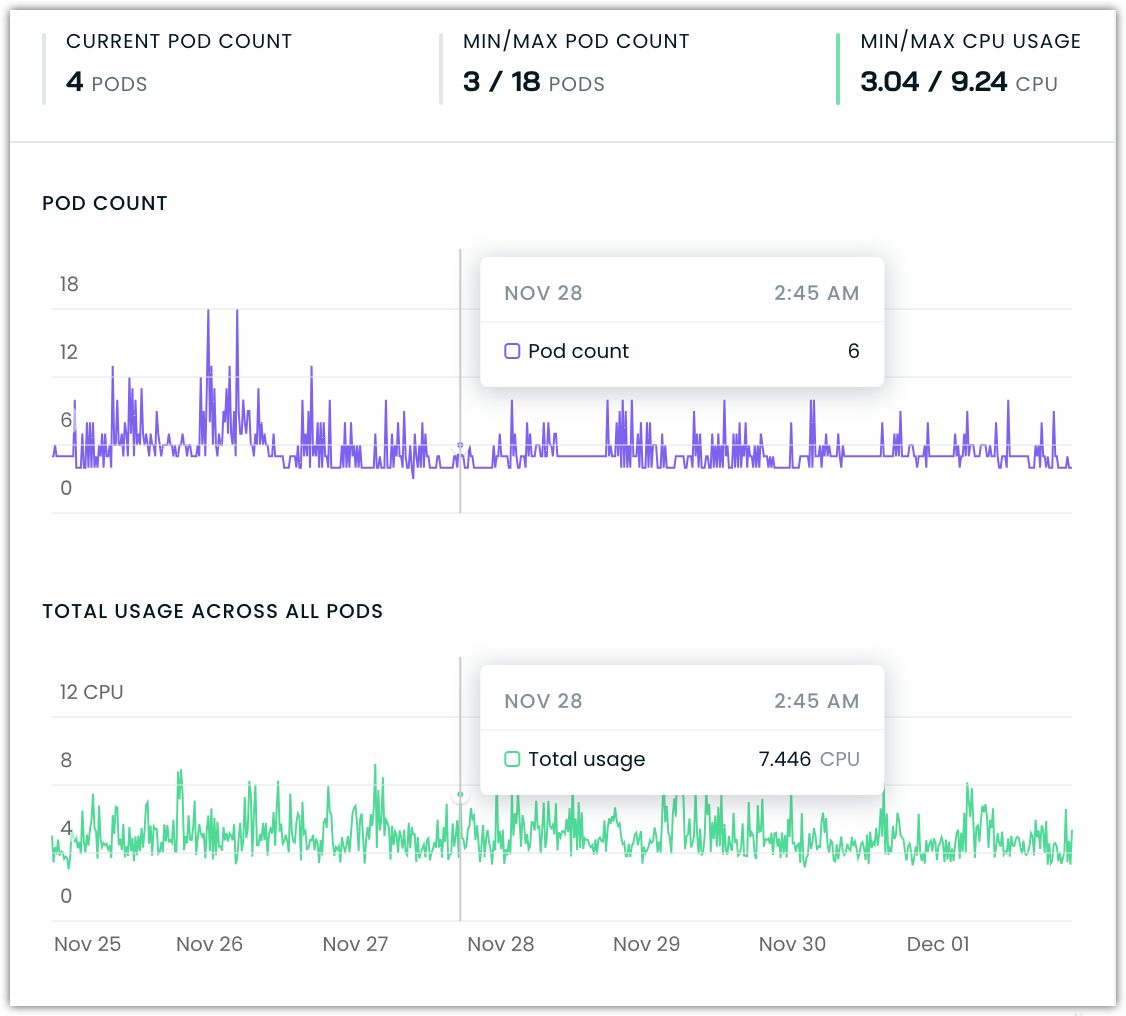
Example of a workload with a cyclical usage pattern
Example
Consider a user-facing service that experiences consistent daily traffic patterns - low usage during nighttime hours and high usage during business hours. During off-peak hours, the service might need only 0.5 CPU cores total across all pods. During peak hours, usage might spike to 10 CPU cores. Workload Autoscaler recognizes this pattern and ensures the workload can scale efficiently across its full operating range while maintaining optimal CPU allocation at both low and high usage periods.
The technical details of how the system calculates CPU distribution - such as validating if minRequests * maxReplicas >= maxLoad - ensure the workload always has sufficient capacity to handle its expected load patterns, whether operating at minimum or maximum scale.
Native CPU overhead
When both vertical and horizontal scaling are enabled for workloads using CPU or memory metrics, Workload Autoscaler automatically applies native CPU overhead calculations to ensure workloads maintain appropriate headroom below HPA scaling thresholds. This overhead is calculated and applied automatically, completely replacing any user-configured CPU overhead settings for workloads with both scaling dimensions active.
Unlike memory-based HPA coordination described below, which builds upon existing user overhead settings, the native CPU overhead calculation operates independently to ensure proper HPA scaling. This prevents workloads from scaling unnecessarily to their maximum replica limits.
How the calculation works:
For HPA targets, the system calculates:
target_cpu ÷ hpa_target_percentage × 110Here, target_cpu is the CPU requests recommended by Cast AI, and hpa_target_percentage is the utilization percentage defined in the HPA.
For example, if Cast AI recommends 100m CPU and your HPA targets 70% utilization, the calculation is:
100 ÷ 70 × 110 = 157mIn this case, the workload runs at roughly 64% utilization instead of exactly 70%, giving the HPA enough headroom to trigger scaling when needed.
This automatic overhead calculation ensures HPA scaling behavior remains predictable while preventing unnecessary scaling to maximum replica counts.
Custom metrics
When workloads use HPAs (including KEDA-generated HPAs) that combine CPU metrics with custom metrics, the Workload Autoscaler applies a different optimization strategy:
- Native CPU overhead calculations are still applied to maintain appropriate headroom
- Replica target corrections and seasonality adjustments are not applied when external metrics are detected
This prevents conflicts when custom metrics primarily drive scaling decisions and CPU increases don't proportionally increase throughput.
For workloads scaled purely by CPU or memory metrics, the full optimization algorithms (including replica target corrections and seasonality handling) are applied as described in the sections above.
Memory-based horizontal scaling
When vertical scaling changes the memory requests for a workload, it can affect how a memory-based Horizontal Pod Autoscaler (HPA) interprets utilization. In some cases, this can make HPA trigger earlier than intended, causing unnecessary scaling events.
The Workload Autoscaler prevents this by automatically adjusting memory requests to keep typical usage below the HPA's scaling threshold, even after vertical optimizations. This coordination works with your existing memory overhead settings, applying additional adjustments on top of any configured overhead to prevent frequent scale-up events. These corrections happen automatically in the background, without requiring any changes to your HPA or vertical scaling configurations.
Limitations
When using vertical and horizontal autoscaling together in Cast AI's Workload Autoscaler, the aforementioned algorithmic optimizations happen automatically in the background with no manual configuration needed or, in fact, available. There is no way to toggle this behavior on or off. Therefore, it is important to note that there are certain limitations that need to be understood.
Custom metrics
When HPAs or KEDA ScaledObjects combine CPU metrics with custom metrics, Workload Autoscaler applies limited optimization. While native CPU overhead is still calculated to maintain headroom, replica target corrections and seasonality adjustments are disabled. This recognizes that for workloads primarily driven by these custom metrics, CPU-based scaling corrections may not align with actual throughput.
For more information, see KEDA compatibility.
CPU or memory metrics requirement
Workload Autoscaler's vertical and horizontal autoscaling coordination algorithms are triggered only when horizontal scaling includes CPU or memory metrics. When HPAs use only custom metrics (without CPU or memory), the automatic optimization between vertical and horizontal scaling will not occur.
Custom metrics and third-party autoscalersFor detailed information about how Cast AI works with custom metrics and third-party autoscaling solutions like KEDA, see KEDA compatibility.
VPA setting availability
Several vertical workload scaling settings available for the Workload Autoscaler become irrelevant as the system handles CPU allocation dynamically and balances between the two optimization strategies. Even if their values are set in the vertical scaling policy, they will be ignored.
Recommendation percentile:
When both vertical and horizontal scaling are enabled for a workload, instead of respecting the CPU values manually set by the user, the system will rely on its aforementioned algorithms to issue CPU recommendations. For Memory, the figure below can still be configured.

Resource overhead:
When both vertical and horizontal scaling are enabled for a workload, CPU overhead is handled automatically through native overhead calculations that completely replace any user-configured CPU overhead settings. This automatic overhead ensures workloads maintain appropriate headroom below HPA scaling thresholds without requiring user intervention. Memory overhead can still be configured manually as that resource coordination works with existing user settings rather than replacing them.
