
Paused drain configuration
NoteThe Paused Drain feature currently does not support scheduled rebalancing.
Overview
Paused Drain configuration is an advanced rebalancing option that temporarily pauses the rebalancing process after new nodes are created but before existing nodes are drained and deleted. This allows you to integrate cluster rebalancing with your application deployment workflow, such as when you need to update application versions on the new nodes before removing the original infrastructure.
Use cases
The Paused Drain feature is useful when:
- Deploying new application versions that should only run on newly provisioned nodes
- Performing controlled migrations of workloads to new infrastructure
- Validating new node configurations before removing original nodes
- Implementing blue-green deployment strategies at the infrastructure level
How it works
The Paused Drain process follows these steps:
- Node Creation: The rebalancer provisions new optimized nodes (Green nodes)
- Process Pauses: Instead of proceeding immediately to drain old nodes, the process pauses
- Cordoning: Original nodes (Blue nodes) are cordoned to prevent new pod scheduling
- Wait Period: The system waits for the specified duration while you perform application updates
- Auto-Uncordoning: After the timeout period, original nodes are automatically uncordoned
Step-by-step using the API
Step 1: Generate a rebalancing plan with Paused Drain
Call the Rebalancing Plan Generation API with the pausedDrainConfig parameter:
{
"pausedDrainConfig": {
"enabled": true,
"timeoutSeconds": 600
}
}The timeoutSeconds parameter specifies how long (in seconds) the original nodes should remain cordoned.
Step 2: Execute the rebalancing plan
Trigger the plan by calling the Execute Rebalancing Plan API. Use the rebalancingPlanId generated in the previous step.
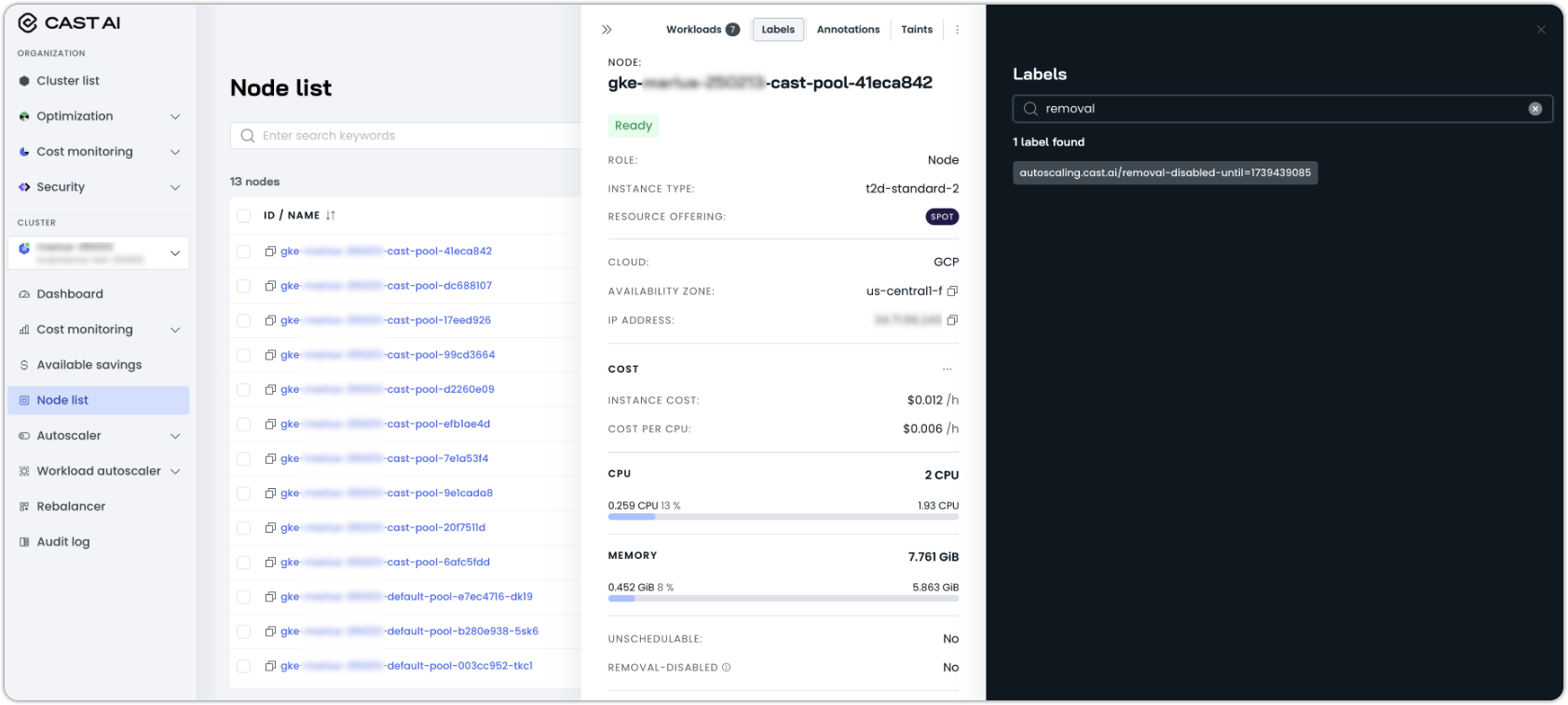
Step 3: Node labels and annotations
During the paused drain process:
-
New (Green) nodes receive the label
autoscaling.cast.ai/removal-disabled-untilwith a UNIX timestamp value-
This timestamp equals the specified pause duration plus 1800 seconds
-
These nodes are protected from deletion until this timestamp is reached
-
-
Original (Blue) nodes are:
- Cordoned to prevent new pod scheduling
- Labeled with
autoscaling.cast.ai/draining=rebalancing - Annotated with
autoscaling.cast.ai/paused-draining-untilcontaining the timestamp when the drain process will resume
Step 4: Deploy updated applications
During the pause period, you can:
- Deploy updated application versions to the cluster
- Verify that pods schedule onto the new nodes
- Perform tests on the new infrastructure
Step 5: Automatic process completion
Once the specified timeout period elapses:
- Original nodes are automatically uncordoned
- The regular Kubernetes scheduling process resumes
Limitations
- The system manages node labels and annotations and should not be manually modified during the process.