
Spot Instances
Autoscaling using Spot Instances
The Cast AI Autoscaler allows you to run your workloads on Spot Instances. To utilize Spot Instances in your cluster, choose a Node template and enable Spot Instances within the Select resource offering section. You can configure a template as either Spot-only or Spot-optional.
If only the Spot resource offering is selected, the Autoscaler will exclusively use Spot Nodes to scale the cluster with that template, regardless of whether unscheduled Pods have Spot toleration or a Spot nodeSelector.
If both offerings, Spot and On-Demand, are selected, Spot Nodes become optional, and the behavior of the Autoscaler will be influenced by the configuration of the workload.
The supported configurations for workloads are outlined below in the document.
Understanding Spot interruptions
Spot Instances offer significant cost savings but can be interrupted by cloud providers with limited notice, typically 30 seconds on GCP and Azure, and up to 2 minutes on AWS. Cast AI provides multiple layers of protection against these interruptions, from monitoring to proactive prediction and mitigation.
Monitoring with Spot Handler
Spot Handler runs as a DaemonSet on your nodes, monitoring for interruption signals from your cloud provider. When an interruption is detected, Spot Handler reports the event to Cast AI's platform. This data feeds into Cast AI's machine learning models to improve interruption predictions and Spot reliability recommendations.
Spot Handler is monitoring-only—it does not drain nodes, reschedule pods, or take any action on your workloads. When an interruption occurs, Kubernetes handles pod termination using standard mechanisms, and Cast AI's Autoscaler provisions replacement capacity.
Proactive mitigation
Cast AI offers these features that work before interruptions occur:
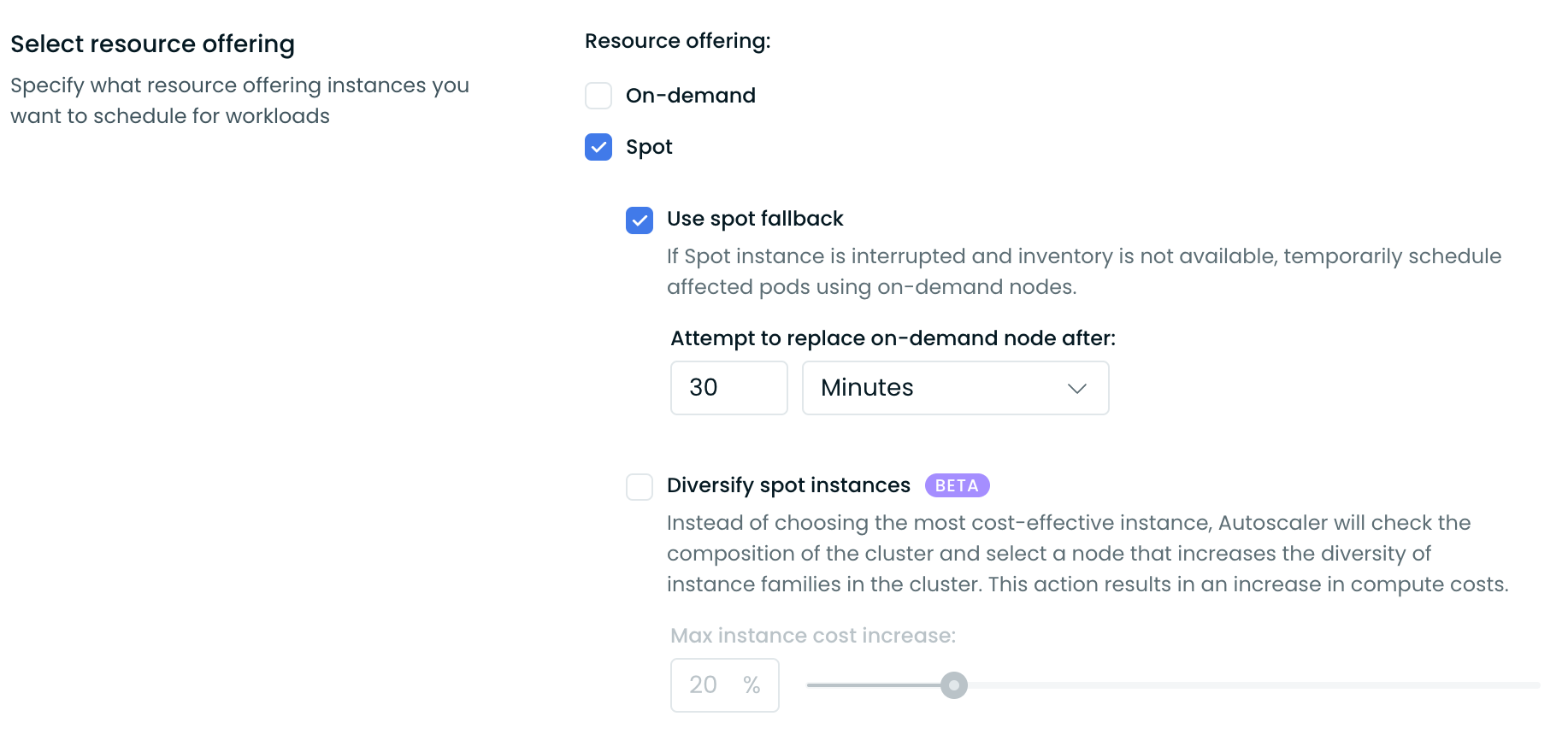
Spot reliability uses machine learning to select instance types with longer average runtimes. You configure a maximum cost increase percentage, and Cast AI balances reliability against your cost tolerance.
Interruption prediction model identifies nodes likely to be interrupted and proactively rebalances them before the cloud provider sends termination signals. This provides far more time for graceful workload migration than the 30-second to 2-minute windows that cloud providers offer during actual interruptions. The prediction models cover different time horizons depending on the provider: 1 hour for AWS, 3 hours for GCP.
Best practices
To minimize the interruption impact on your workloads:
- Run multiple replicas of each application to maintain availability during node replacements
- Use Pod Disruption Budgets to enforce minimum availability requirements
- Configure preStop lifecycle hooks to handle graceful shutdown within the limited notice window
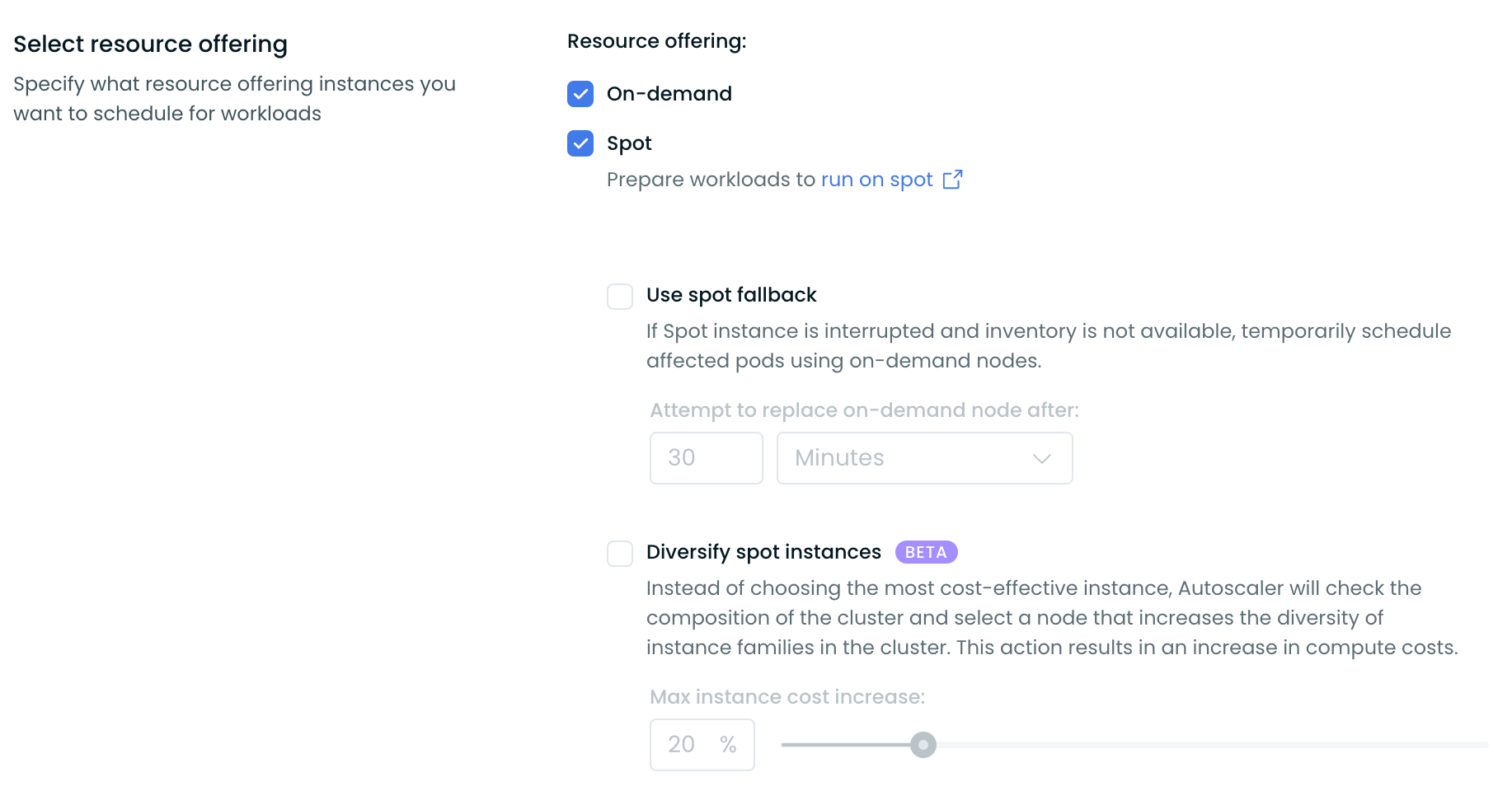
- Enable Spot fallback in your node templates so workloads can temporarily run on On-Demand nodes when Spot capacity is unavailable
For workloads that cannot tolerate any interruption risk, use On-Demand Instances or configure them to prefer Spot Instances with fallback to On-Demand capacity.
Supported workload configurations
Tolerations
When to use: Spot Instances are optional
When a pod is marked only with tolerations, the Kubernetes scheduler could place such a pod/pods on regular nodes as well.
tolerations:
- key: scheduling.cast.ai/spot
operator: ExistsNode Selectors
When to use: only use Spot Instances
If you want to make sure that a pod is scheduled on Spot Instances only, add nodeSelector as well as per the example below.
The Autoscaler will then ensure that only a Spot Instance is picked whenever your pod requires additional workload in the cluster.
tolerations:
- key: scheduling.cast.ai/spot
operator: Exists
nodeSelector:
scheduling.cast.ai/spot: "true"Node Affinity
When to use: Spot Instances are preferred - if not available, use on-demand nodes
In the case where a workload with the following affinity is running on a Spot Instance and the instance gets interrupted, the workload will be scheduled on another existing Spot node. Otherwise, if there is only On-Demand capacity available in the cluster, it will be scheduled on an On-Demand node.
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: scheduling.cast.ai/spot
operator: Exists
tolerations:
- key: "scheduling.cast.ai/spot"
operator: "Exists"
effect: "NoSchedule"
Applying spot configuration at scaleIf you need to configure many workloads for Spot Instances without editing each deployment manifest, use Pod mutations. Pod mutations automatically inject tolerations, node selectors, or spot configuration into pods at admission time. The
spotConfigfield supportsonly-spot,preferred-spot, andoptional-spotmodes, anddistributionPercentagelets you run a chosen fraction of a workload's replicas on Spot Instances while the rest stay on On-Demand. See Spot configuration in the Pod mutations reference.
Spot Fallback
When to use: You want to maximize workload uptime and mitigate low Spot Instance availability.
Cast AI supports the fallback of Spot Instances to on-demand nodes in case there is no Spot Instance availability. Our Autoscaler will temporarily add an on-demand node for your Spot-only workloads to run on. Once an inventory of Spot Instances is again available, on-demand nodes used for the fallback will be replaced with actual Spot Instances.
Fallback on-demand instances will be labeled with scheduling.cast.ai/spot-fallback:"true" label.
To enable this feature, select a Node template, enable Spot Instances in the Select resource offering section, and then choose Use spot fallback. Finally, set a time interval for Cast AI to review the inventory and attempt to replace an on-demand node back to a Spot Instance.
Spot Instance Reliability
Cast AI offers Spot Reliability, an advanced feature that uses machine learning (ML) to select more reliable Spot Instances, reducing interruption frequency for your workloads.
Key Improvements Over Traditional Spot Usage
- Intelligent Instance Selection: ML models identify Spot Instances with longer average runtime
- Configurable Cost Trade-offs: Set maximum price increase tolerance for reliability gains
- Workload Stability: Particularly beneficial for long-running tasks and stability-critical workloads
When to Use Spot Reliability
Consider enabling Spot Reliability when:
- Workloads take significant time to complete (hours rather than minutes)
- You can tolerate modest cost increases for improved stability
- Traditional Spot Instances experience high interruption rates in your region
Configuration
Spot Reliability is currently configured through UI or the API by enabling it on node templates:
{
"constraints": {
"enableSpotReliability": true,
"spotReliabilityPriceIncreaseLimitPercent": 20
}
}Interruption prediction model
Cast AI can proactively rebalance spot nodes that are at risk of interruption by the cloud provider. The system's response to these potential interruptions varies based on the selected interruption prediction model.
Unlike reactive interruption handling (which waits for cloud provider signals), the interruption prediction model uses machine learning to predict interruptions before they occur. This provides more time for graceful workload migration and reduces disruption impact.
To enable this feature, first select a Node template, then turn on Spot Instances in the Select resource offering, and finally turn on Interruption prediction model.
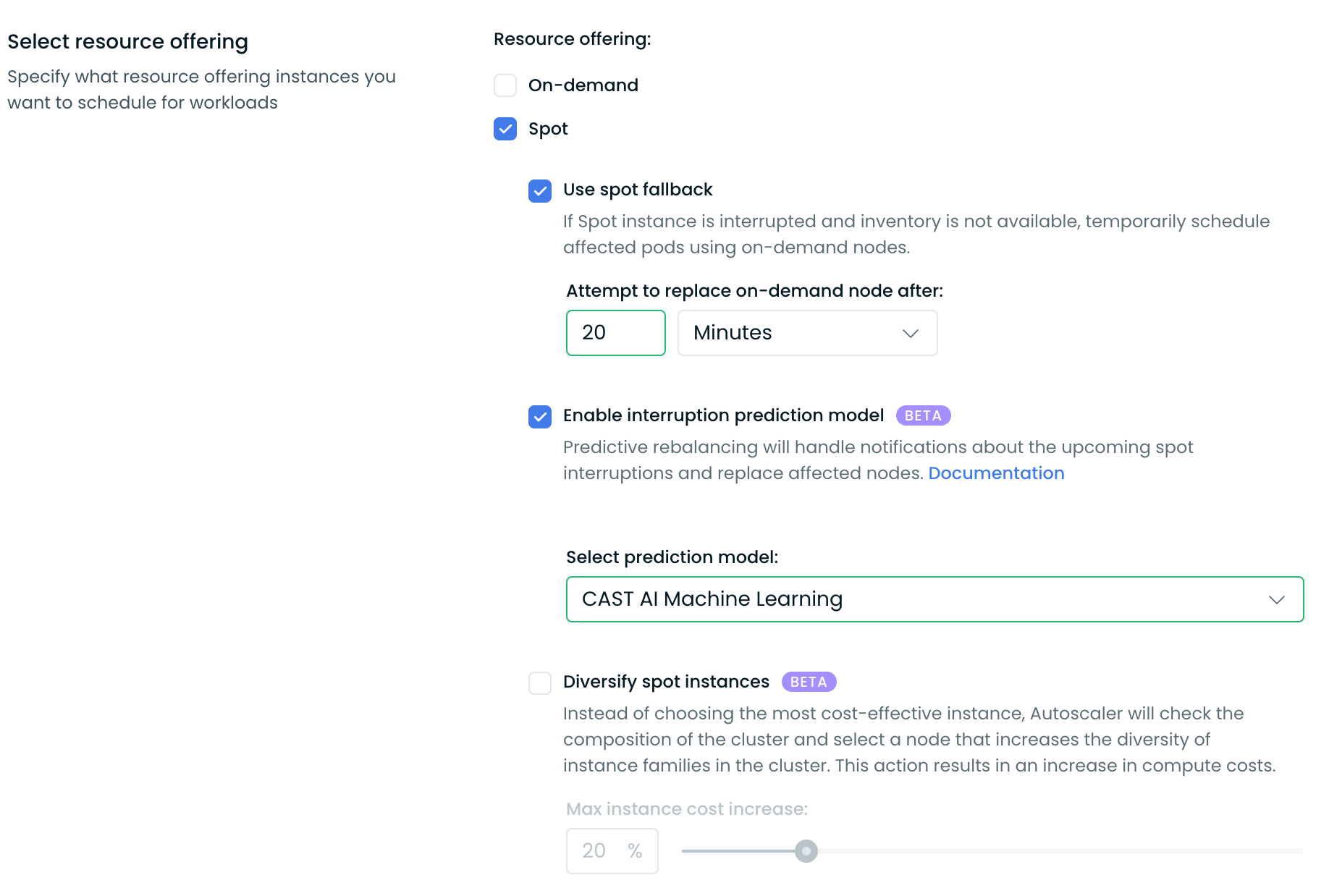
The supported interruption prediction models are outlined below.
AWS Rebalance Recommendations
DeprecatedAs of July 8, 2026, the AWS Rebalance Recommendations are deprecated. All existing Node Templates configured to
AWS Rebalance Recommendations now use Cast AI Machine Learning prediction model.
AWS's native method informs users of an upcoming spot interruption event that will affect a node of a particular instance type. However, not all instances of the same type might receive a rebalance recommendation, and the exact time of interruption can vary significantly.
When such a rebalance recommendation is received, Cast AI marks all instances of the same type currently in the cluster for rebalancing. Concurrently, the system places this instance type on a gray list, ensuring it is not utilized during an upscaling event (unless it's the only available option). Following this, Cast AI can rebalance up to 30% of the affected nodes in the cluster (or template), doing so sequentially.
Cast AI Machine Learning
Cast AI's machine learning model can predict that a specific instance will be interrupted within the next 180 minutes. Once a prediction is issued by the model, only the affected instance is cordoned and rebalanced.
Node retention during prediction validationCast AI continuously validates its Spot interruption predictions against real-world outcomes. When a node is predicted to be interrupted, there's a 2% chance it will be retained and cordoned for up to 3 hours (the exact window depends on the cloud provider) while a replacement node is added to the cluster. Observing what happens during that window feeds back into the model, improving prediction accuracy over time. The cost impact averages around 0.1% of total cluster Spot spend.
Labeling and Tainting of Nodes During Spot Interruptions
During the management of spot interruption events (actual or predicted), Cast AI applies the following labels to the impacted nodes:
| Label | Description |
|---|---|
autoscaling.cast.ai/draining=spot-prediction | This label indicates that the node is being replaced because Cast AI predicted its interruption. |
autoscaling.cast.ai/draining=rebalancing | This label signifies that the node is being replaced as part of the Cast AI rebalancing process. |
autoscaling.cast.ai/draining=spot-fallback | This label is used when the node is being replaced due to a spot interruption notice from a cloud provider, but replacement capacity is unavailable. The node will be replaced with a temporary fallback (on-demand) node. |
autoscaling.cast.ai/draining=aws-rebalance-recommendation | |
autoscaling.cast.ai/draining=spot-interruption | This label is applied when the node is being replaced due to a spot interruption notice received from a cloud provider. |
autoscaling.cast.ai/draining=manual | This label is applied to nodes deleted through the Console's user interface. |
In addition to one of these labels, Cast AI will also apply the taint autoscaling.cast.ai/draining=true to the impacted node.
Step-by-step guide to deploying on Spot Instances
In this step-by-step guide, we demonstrate how to use Spot Instances with your Cast AI clusters.
To do that, we will use an example NGINX deployment configured to run only on Spot Instances.
1. Enable the Unscheduled pods policy and configure the Node template
To start using Spot Instances, go to the Autoscaler menu and enable the Unscheduled pods policy.
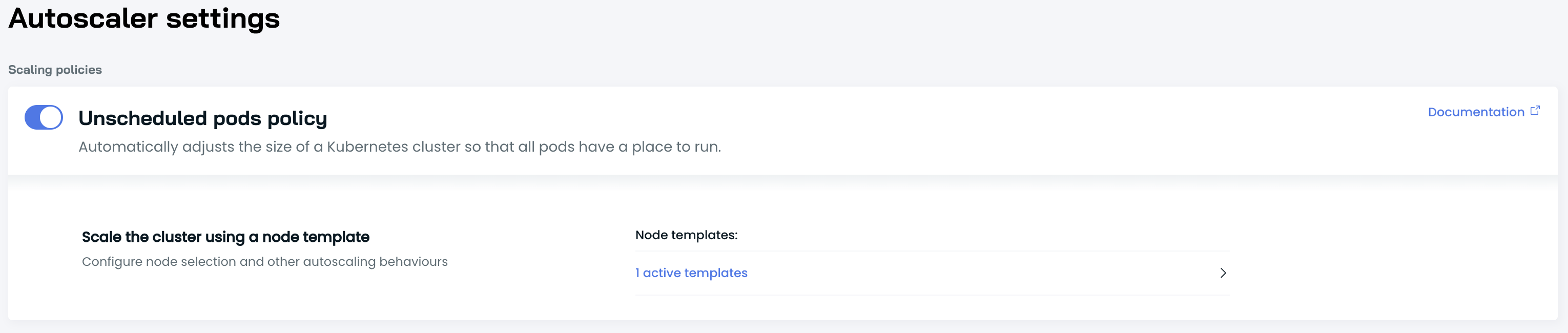
Next, configure a Node template to utilize Spot Instances by selecting Spot in the Select resource offering section.
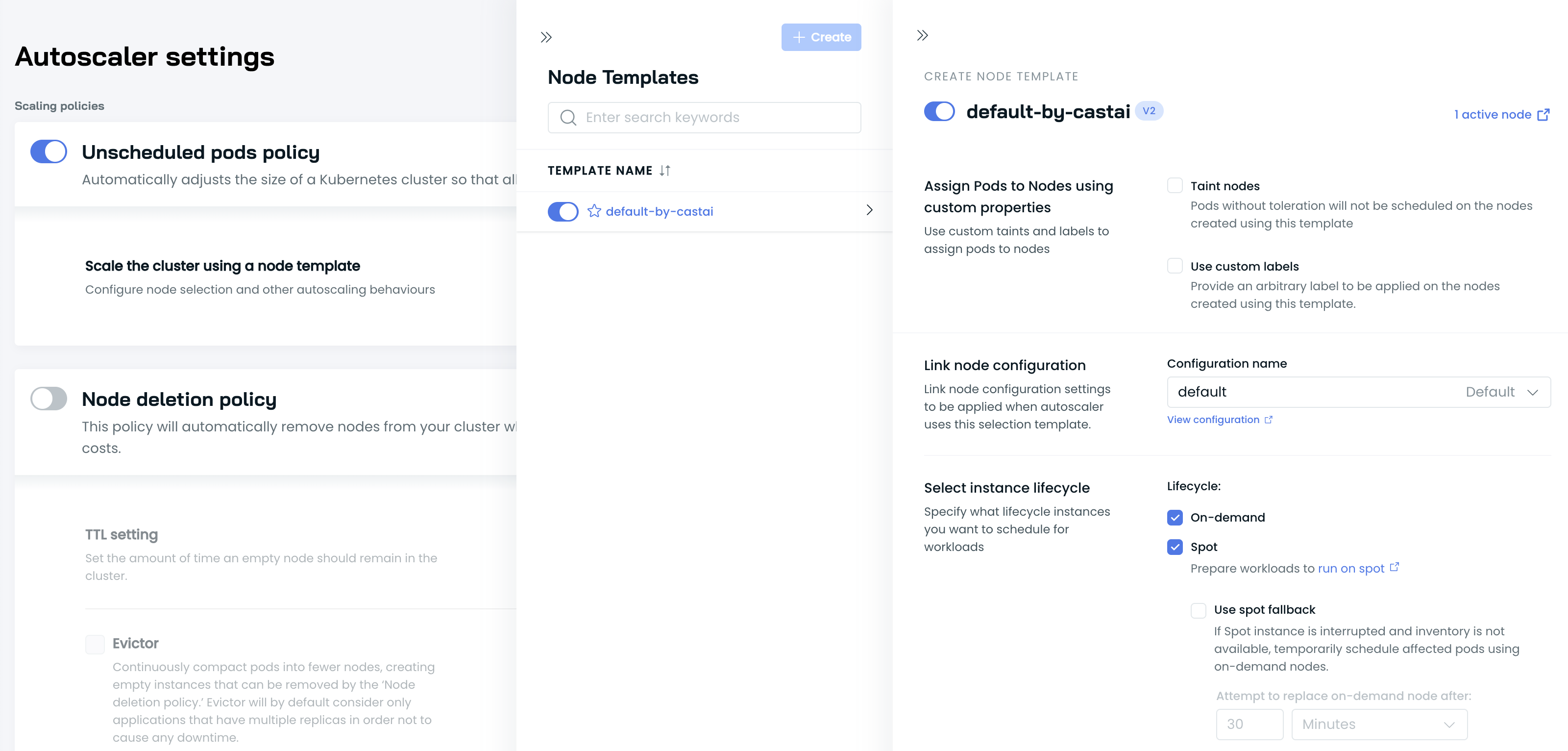
2. Example deployment
Save the following yaml file, and name it: nginx.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
nodeSelector:
scheduling.cast.ai/spot: "true"
tolerations:
- key: scheduling.cast.ai/spot
operator: Exists
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
resources:
requests:
cpu: '2'
limits:
cpu: '3'2.1. Apply the example deployment
With kubeconfig set in your current shell session, you can execute the following (or use other means of applying deployment files):
kubectl apply -f nginx.yaml2.2. Wait several minutes
Once the deployment is created, it will take up to several minutes for the Autoscaler to pick up the information about your pending deployment and schedule the relevant workloads in order to satisfy the deployment needs, such as:
- This deployment tolerates Spot Instances
- This deployment must run only on Spot Instances
3. Spot Instance added
- You can see your newly added Spot Instance in the Node list.
FAQ
Why didn't the platform pick a cheaper Spot Instance?
Situations may occur where Cast AI doesn't pick the cheapest Spot Instance available in your cloud environment. The reasons for that can be one or more of the following:
General
- The cloud provider-specific quotas didn't allow Cast AI to pick that particular instance type. The usual mitigation for such issues is to increase quotas.
- The specific Spot Instance type could have been interrupted recently. Cast AI puts such instance types on a cooling-off period and prefers other availability zones for the time being.
- Blacklisted API was previously used to disable instance types in the whole organization or specific cluster.
- As Spot Instance availability fluctuates constantly, during the time of instance creation, the particular instance type might not have been available, and Cast AI automatically picked the next cheapest instance.
Zone Constraints
If the added Spot Instance was in a different availability zone than the cheapest instance, the following could be the reasons why:
- Node Configuration (custom or the default one) being used has specific subnets defined, which prevent Cast AI from picking Spot Instances in other availability zones.
- Node Template has a specific list of instance types configured, which prevents picking something cheaper.
- The subnet for that Availability Zone was full (no IPs left).
- The specific workload has a zone affinity for a particular zone. This can be achieved in a variety of ways:
- The pod has
nodeSelectorornodeAffinityfor a particular zone. Examples:... spec: nodeSelector: topology.kubernetes.io/zone: "eu-central-1" ...... spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - eu-central-1 ... - The pod has zone-bound volumes (the pod cannot be scheduled in any other zone than the volume). Example:
apiVersion: v1 kind: PersistentVolume metadata: name: zone-volume spec: capacity: storage: 10Gi accessModes: - ReadWriteOnce storageClassName: zone-storage nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: topology.kubernetes.io/zone operator: In values: - eu-central-1 --- apiVersion: v1 kind: Pod metadata: name: zone-pod spec: containers: - name: my-container image: my-image volumeMounts: - name: data mountPath: /data volumes: - name: data persistentVolumeClaim: claimName: zone-pvc - The pod has pod affinity with the zone topology key, and the pod that matches the affinity is not in the cheapest zone. Example:
apiVersion: v1 kind: Pod metadata: name: affinity-pod spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - topologyKey: topology.kubernetes.io/zone labelSelector: matchExpressions: - key: app operator: In values: - my-app containers: - name: my-container image: my-image - The pod has topology spread on zone and adding a new instance in the cheapest zone would not satisfy the skew. Example:
apiVersion: apps/v1 kind: Deployment metadata: name: spread-deployment spec: replicas: 3 strategy: type: RollingUpdate rollingUpdate: maxSurge: 1 maxUnavailable: 1 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: my-app containers: - name: my-container image: my-image
- The pod has
What is considered a Spot-friendly workload?
In the Available savings report, Cast AI provides recommendations to run workloads on spot nodes in the following scenarios:
- The workload is already running on a Spot Instance
- The workload can tolerate Spot taints
- The workload is not marked as critical for a cluster or instance
How often does the interruption prediction model run?
The Cast AI ML interruption prediction model generates predictions every 10 minutes for each Spot node in a cluster. Because predictions are evaluated on this cycle, a node that has just joined the cluster can receive a prediction — and be cordoned and rebalanced — within minutes of becoming ready.
Unlike the Evictor, there is no configurable cycle interval for the prediction model.
Is there a minimum node age before the interruption prediction model acts on a node?
No. The interruption prediction model has no minimum node age requirement. A Spot node can be targeted for proactive rebalancing immediately after it joins the cluster if the model predicts imminent interruption.
Node age and lifecycle events are inputs to the ML model — they influence the prediction score — but they do not gate whether the model evaluates or acts on a node.
When a node is replaced due to an interruption prediction, is the new node created before the old one is drained?
Yes. Cast AI always creates the replacement node first, then cordons and drains the predicted node. The old node is deleted only after it has been fully drained. This ensures workloads have capacity to reschedule onto before the original node is taken out of service.
How many nodes can be cordoned at once due to interruption predictions?
Cast AI limits the number of nodes cordoned for prediction validation to keep the cost impact negligible. The total cost of cordoned nodes is capped so it never exceeds 10% of the cluster's total Spot node cost.
This cap applies only to the small fraction of nodes retained for model validation (the 2% sampling described in the Cast AI Machine Learning section above). Nodes cordoned during active rebalancing are subject to separate rebalancing limits.
I disabled the interruption prediction model in my node template, but I still see nodes being rebalanced. Why?
Disabling the interruption prediction model prevents Cast AI from proactively rebalancing nodes based on ML-predicted interruptions. It does not disable rebalancing triggered by other sources.
Nodes in your cluster can still be rebalanced for reasons unrelated to spot prediction, including:
- Scheduled rebalancing — if a rebalancing schedule is configured, Cast AI rebalances nodes on that schedule to optimize cost and performance.
- Manual rebalancing — a rebalancing operation was triggered from the console or API.
- Spot fallback fall-forward — a fallback on-demand node is replaced back to Spot once Spot capacity becomes available again.
To identify the reason a specific node was rebalanced, check the autoscaling.cast.ai/draining label on the node or review the cluster audit events. The label value indicates which signal triggered the drain: spot-prediction, rebalancing, spot-fallback, spot-interruption or aws-rebalance-recommendation (deprecated July 2026).
Updated 17 days ago