
Rebalancing
Rebalancing is a Cast AI feature that allows your cluster to reach its most optimal and up-to-date state. During this process, suboptimal Nodes are automatically replaced with new ones that are more cost-efficient and run the most up-to-date Node Configuration settings.
Rebalancing works by taking all the workloads in your cluster and finding the most optimal ways to distribute them among the cheapest Nodes.
Rebalancing utilizes the same algorithms that drive Cast AI Node autoscaling to determine optimal Node configurations for your workloads. The only difference is that all workloads are run through them rather than just unschedulable Pods.
Prerequisites
Rebalancing requires the Unscheduled pods policy to be enabled in your cluster's autoscaler settings. Because the Rebalancer uses the same scheduling algorithms as the autoscaler, it depends on this policy being active to generate and execute rebalancing plans.
If the Unscheduled pods policy is disabled or not configured, attempting to trigger a rebalance returns an "Autoscaler is disabled" error, even if the top-level autoscaler setting is enabled.
To enable the Unscheduled pods policy:
- In the Cast AI console, navigate to Autoscaler > Settings and toggle the Unscheduled pods policy on.
- If you manage autoscaler policies through Terraform, ensure your
castai_autoscalerresource includes theunschedulable_podsblock:
resource "castai_autoscaler" "castai_autoscaler_policy" {
cluster_id = castai_eks_cluster.my_castai_cluster.id
autoscaler_settings {
enabled = true
unschedulable_pods {
enabled = true
}
# ... other settings
}
}The
unschedulable_podsblock defaults tofalsewhen omitted. You must explicitly setenabled = truefor rebalancing to work.
Purpose
The rebalancing process has multiple purposes:
-
Rebalance the cluster during the initial onboarding to immediately achieve cost savings. The rebalancer makes it easy to start using Cast AI by running your cluster through the Cast AI algorithms and reshaping your cluster into an optimal state during onboarding.
-
Remove fragmentation, which is a normal byproduct of everyday cluster execution. Autoscaling is a reactive process that aims to satisfy unschedulable Pods. As these reactive decisions accumulate, your cluster might become too fragmented.
Consider this example: you are upscaling your workloads by one replica every hour. That replica is requesting 6 CPUs. The cluster will end up with 24 new nodes with 8 CPU capacities each after a day. This means that you will have 48 unused, fragmented CPUs. The rebalancer aims to solve this by consolidating the workloads into fewer, cheaper Nodes, reducing waste.
-
Replace specific Nodes due to cost inefficiency or outdated Node Configuration. During the rebalancing operation, targeted Nodes will be replaced with the most optimal set of Nodes running the latest Node Configuration settings.
Scope
You can rebalance the entire cluster or only a specific set of Nodes.
- To rebalance the whole cluster, choose Cluster > Rebalance.
- To rebalance a subset of Nodes, select them using Cluster > Node list and then choose Actions > Rebalance nodes.
After assessing the operation's scope, generate a Rebalancing plan to review planned changes and their effect on the cluster composition and costs. Only Nodes without problematic workloads will be considered for rebalancing.
To reduce the number of problematic workloads and avoid service disruption, check the Preparation for the rebalancing guide.
Rebalancing plan statuses
When you create a rebalancing plan in the Cast AI console, the plan passes through several states. Each state reflects where the rebalancer and Kubernetes are in the lifecycle of that plan.
| Status | Meaning |
|---|---|
| Generating | The rebalancer is computing the optimal node configuration and migration plan for the selected nodes. |
| Ready | Plan generation is complete. The plan is available for preview. Review planned nodes, costs, and impact before choosing to execute. |
| In progress | The plan is actively running. This phase includes creating new nodes, preparing them, draining old nodes, and deleting them one by one. |
| Completed | The plan executed successfully. All targeted nodes have been replaced with optimal ones. |
| Partial | The plan executed, but some nodes could not be fully rebalanced, for example, nodes that failed to drain during graceful rebalancing. Successfully replaced nodes remain, while failed nodes are typically annotated with rebalancing.cast.ai/status=drain-failed. |
| Failed | The plan could not be completed, likely due to a blocking condition such as Pod Disruption Budgets, insufficient capacity, or a timeout. |
| Obsolete | The plan is stale and can no longer be executed. See the explanation below. |
NoteAn Obsolete plan is one that is no longer current and cannot be executed. This typically happens when another rebalancing plan has since started or finished, or when the original plan has been sitting for more than an hour.
You can still open an obsolete plan to review what it planned to do, but you will need to generate a fresh plan if you want to run it.
For details on the phases that make up the In progress status, see Execution. For guidance on what happens when nodes fail to drain, see Handling failed Node drains. To avoid conditions that cause a plan to fail, review Preparation.
Execution
Rebalancing consists of three distinct phases:
- Create new optimal Nodes.
- Drain old, suboptimal Nodes.
- Delete old, suboptimal Nodes. Nodes are deleted one by one as soon as they have been drained.
Understanding Node deletion behavior
The way Cast AI removes Nodes depends on whether they contain workloads:
- Empty Nodes are deleted immediately by the autoscaler without draining. These are Nodes that have no Pods scheduled on them.
- Nodes with workloads go through a complete rebalancing cycle: Cast AI first creates new optimal Nodes, then drains the old Nodes (allowing Pods to reschedule gracefully), and finally deletes them one by one. This approach ensures workload availability throughout the rebalancing process.
Spot fallback Node handling
Rebalancing intentionally does not honor removal-disabled labels or annotations for spot-fallback Nodes. This design prevents clusters from remaining on expensive fallback instances due to operational issues.
Since workloads with Spot Instance selectors can tolerate interruptions by design, Cast AI assumes they can be safely migrated during rebalancing. To prevent prolonged reliance on fallback instances, adjust the fallback interval in your Spot Instance configuration to introduce a quiet period before attempting to move back to Spot Instances.
Rebalancing with Workload Autoscaler recommendations
Cast AI's rebalancing takes into account Workload Autoscaler recommendations in the rebalancing decision-making process. This enables your rebalancing operations to consider resource optimizations recommended by Workload Autoscaler, creating a more comprehensive approach to cluster optimization.
How it works
The rebalancing process considers both Node optimization factors and workload-level resource requirements:
- The system retrieves the current Workload Autoscaler recommendations for all workloads (pending and applied)
- These recommendations are integrated into the rebalancing plan calculation
- New Nodes are provisioned with capacity that matches both optimal Node types and the recommended resource requirements
- Workloads are rescheduled accordingly, with all previously deferred resource recommendations now applied
Considerations
Integrating Workload Autoscaler with rebalancing optimizes both Nodes and workloads simultaneously. This unified approach often leads to greater cost savings, especially when workloads are recommended for downsizing. Your cluster can also proactively adjust resources before pending Pods trigger reactive autoscaling.
Keep in mind the following:
- Potential cost increases: If Workload Autoscaler recommends resource increases, rebalancing may increase costs while improving performance and stability
- Savings threshold: When using a savings threshold with scheduled rebalancing, operations that would increase costs due to workload optimization won't execute. See scheduled rebalancing documentation.
- Version requirements: For optimal results, this integration works best with Workload Autoscaler version
0.31.0or higher. See upgrading your Workload Autoscaler version.
Configuration
You can verify the effectiveness of a rebalancing operation's taking into account of resource recommendations by monitoring your cluster's resource utilization trends after it is complete. You should see visible changes in your resource metrics, typically a reduction in provisioned and requested resources, as shown in the example below:
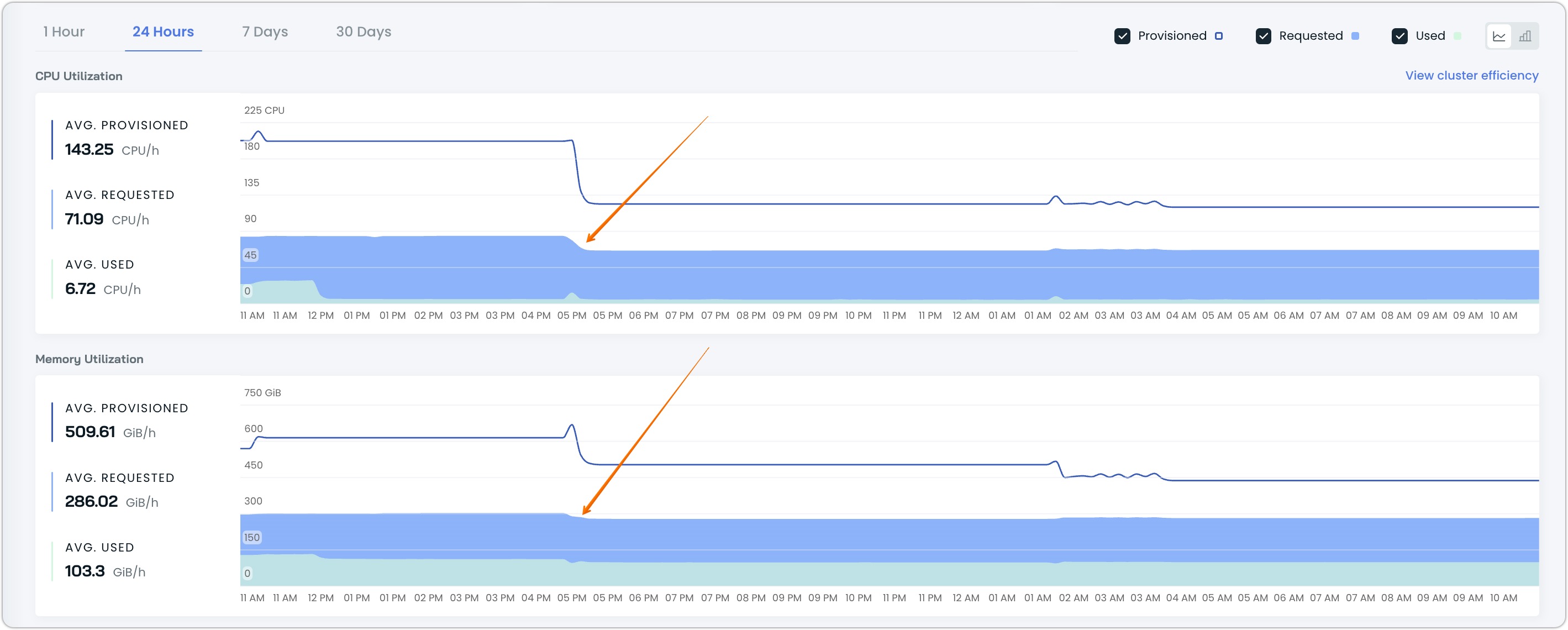
In this example, the rebalancing with Workload Autoscaler recommendations was executed at the point indicated by the arrows, resulting in:
- A decrease in provisioned CPUs from ~180 to ~120 CPU cores
- A reduction in provisioned memory from ~600 to ~450 GiB
These changes should persist over time rather than triggering immediate autoscaling events, indicating that the new resource allocation suits your workload requirements served by the Workload Autoscaler.
Please contact Cast AI support for assistance with enabling or configuring this feature.
Rebalancing timeout behavior
During rebalancing, Cast AI enforces a per-phase timeout to ensure each stage of the operation completes within the allotted time. The following phases apply to rebalancing plan execution:
| Phase | Timeout |
|---|---|
| Node creation | 80 minutes |
| Node preparation | 80 minutes |
| Node draining | Configured drain timeout + 20-minute buffer |
| Node deletion | 80 minutes |
All timeouts are non-configurable, except the draining phase, which tracks the configured drain timeout.
By default, rebalancing performs forceful draining. If a node fails to drain within the draining phase timeout, it will be forcefully drained and deleted from the cluster.
When graceful rebalancing is enabled, Nodes that fail to drain within the timeout period will be marked with the annotation rebalancing.cast.ai/status=drain-failed and cordoned. By default, Cast AI automatically uncordons these Nodes after 3 hours, returning capacity to the cluster. The uncordon timestamp is recorded in the rebalancing.cast.ai/uncordon-after annotation on the Node.
To disable automatic uncordoning and retain the previous behavior where Nodes remain cordoned until manually remediated, set drainFailureConfig.disableUncordon=true in your rebalancing plan or schedule configuration via the API.
To enable graceful rebalancing, do the following:
For manual rebalancing:
- Go to Rebalancer > Prepare new plan
- Enable the Evict nodes gracefully toggle in rebalancing settings
- Generate and execute your plan
For scheduled rebalancing:
- Go to Rebalancer > Schedule rebalancing
- Enable the Evict nodes gracefully option in settings
- Configure and save your schedule
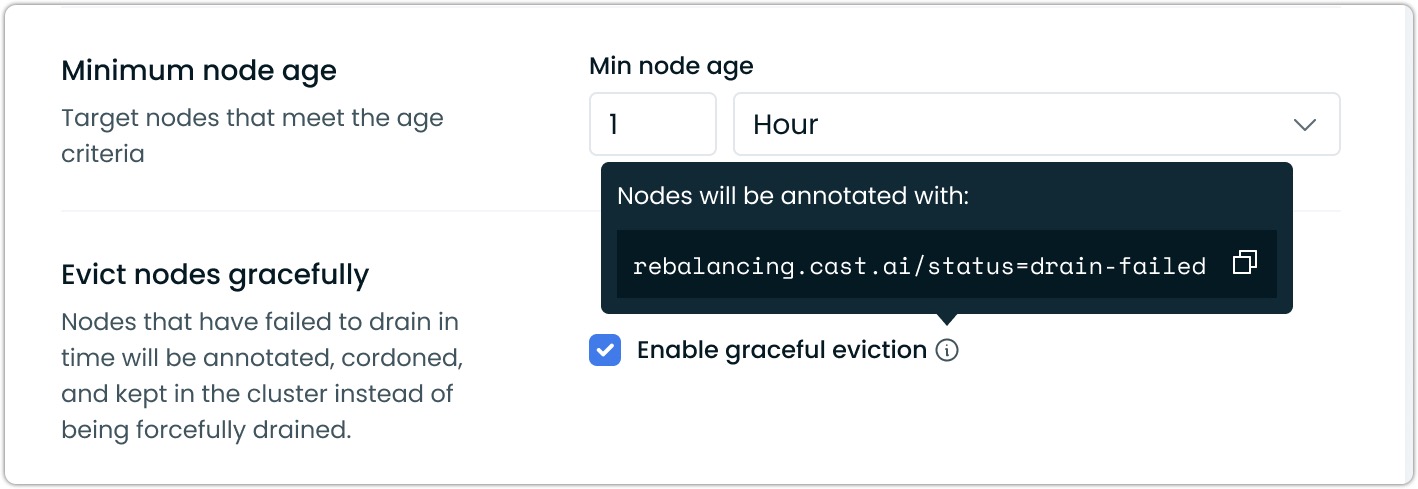
Graceful Node eviction enabled in a rebalancing schedule
Handling failed Node drains
When graceful eviction is enabled, Nodes that fail to drain within the timeout are cordoned and annotated with rebalancing.cast.ai/status=drain-failed. By default, Cast AI automatically uncordons these Nodes after 3 hours. The scheduled uncordon time is recorded in the rebalancing.cast.ai/uncordon-after annotation on the Node.
To find all drain-failed Nodes in your cluster, query for the annotation:
kubectl get nodes -o json | jq -r '.items[] | select(.metadata.annotations["rebalancing.cast.ai/status"] == "drain-failed") | .metadata.name'To check when a specific Node is scheduled to be uncordoned:
kubectl get node <NODE_NAME> -o jsonpath='{.metadata.annotations.rebalancing\.cast\.ai/uncordon-after}'You can also identify these Nodes in the Cast AI console by their Cordoned status.
If a Node becomes stuck in the draining state during rebalancing:
-
Check for blockers:
- Review Pod Disruption Budgets (PDBs) that might prevent Pod eviction
- Look for Pods that cannot be rescheduled due to resource or other constraints
- Check for Pods with local storage or Node affinity requirements
-
Recovery options:
- Wait for automatic uncordoning (default: 3 hours after the drain failure)
- Manually uncordon the Node immediately if you want it back in service sooner
- Manually drain and delete the Node if you still want to remove it
To manually uncordon a drain-failed Node before the scheduled time:
kubectl annotate node <NODE_NAME> rebalancing.cast.ai/status-
kubectl uncordon <NODE_NAME>To remove a drain-failed Node from the cluster:
kubectl drain <NODE_NAME> --ignore-daemonsets --delete-emptydir-data --force
kubectl delete node <NODE_NAME>Pod Disruption Budget (PDB) handling
During rebalancing, Cast AI respects Kubernetes Pod Disruption Budgets to maintain application availability. However, to prevent rebalancing operations from stalling indefinitely, Cast AI enforces a per-node drain timeout.
How PDBs are handled
When draining a node during rebalancing:
- Cast AI attempts to evict pods while respecting their PDBs
- If a pod cannot be evicted due to a PDB constraint, Cast AI waits up to the configured drain timeout (default: 20 minutes, maximum: 180 minutes) for the constraint to be satisfied
- After the timeout expires, the behavior depends on your graceful eviction setting:
| Graceful eviction setting | Behavior after timeout |
|---|---|
| Disabled (default) | Node is forcefully drained and deleted. PDBs may be violated to complete the rebalancing operation. |
| Enabled | Node is annotated with rebalancing.cast.ai/status=drain-failed, cordoned, and kept in the cluster. PDBs are strictly respected. The Node is automatically uncordoned after 3 hours (configurable via API). |
Updated 5 days ago