
Using ARM nodes with Cast AI
ARM instances
ARM-based instances, like those including AWS Graviton processors, can provide significant cost savings and performance improvements for your Kubernetes workloads. Cast AI supports ARM instances across major cloud providers and helps you optimize your cluster architecture for both cost and performance.
Prerequisites
Before enabling ARM instances in your Cast AI-connected clusters, ensure your environment meets the requirements detailed below.
Application compatibility
Your applications must be built for ARM64 architecture. The recommended approach is to build applications with multi-architecture support, allowing them to run on both ARM and x86 architectures. This gives Cast AI the flexibility to select the most cost-effective instance type regardless of architecture.
Most modern applications work well with ARM when properly built for multi-architecture support. However, you should test your applications after enabling ARM support before deploying to production environments.
DaemonSet compatibility
Verify that any DaemonSets in your cluster support the ARM architecture you plan to use. Ideally, these should have multi-architecture support. Since ARM has been available for some time, most commonly used applications already provide multi-architecture images.
Configuration
Cast AI supports different processor architectures across cloud providers:
| Cloud Provider | x86-64 (AMD64) | ARM64 | Notes |
|---|---|---|---|
| AWS EKS | ✓ | ✓ | ARM instances use AWS Graviton processors |
| GCP GKE | ✓ | ✓ | ARM support available through T2A instances |
| Azure AKS | ✓ | ✓* | *ARM support requires additional configuration |
Choose your configuration approach based on your workload compatibility.
Mixed architecture clusters
Use this approach when you have some workloads that can only run on ARM and others that can only run on x86.
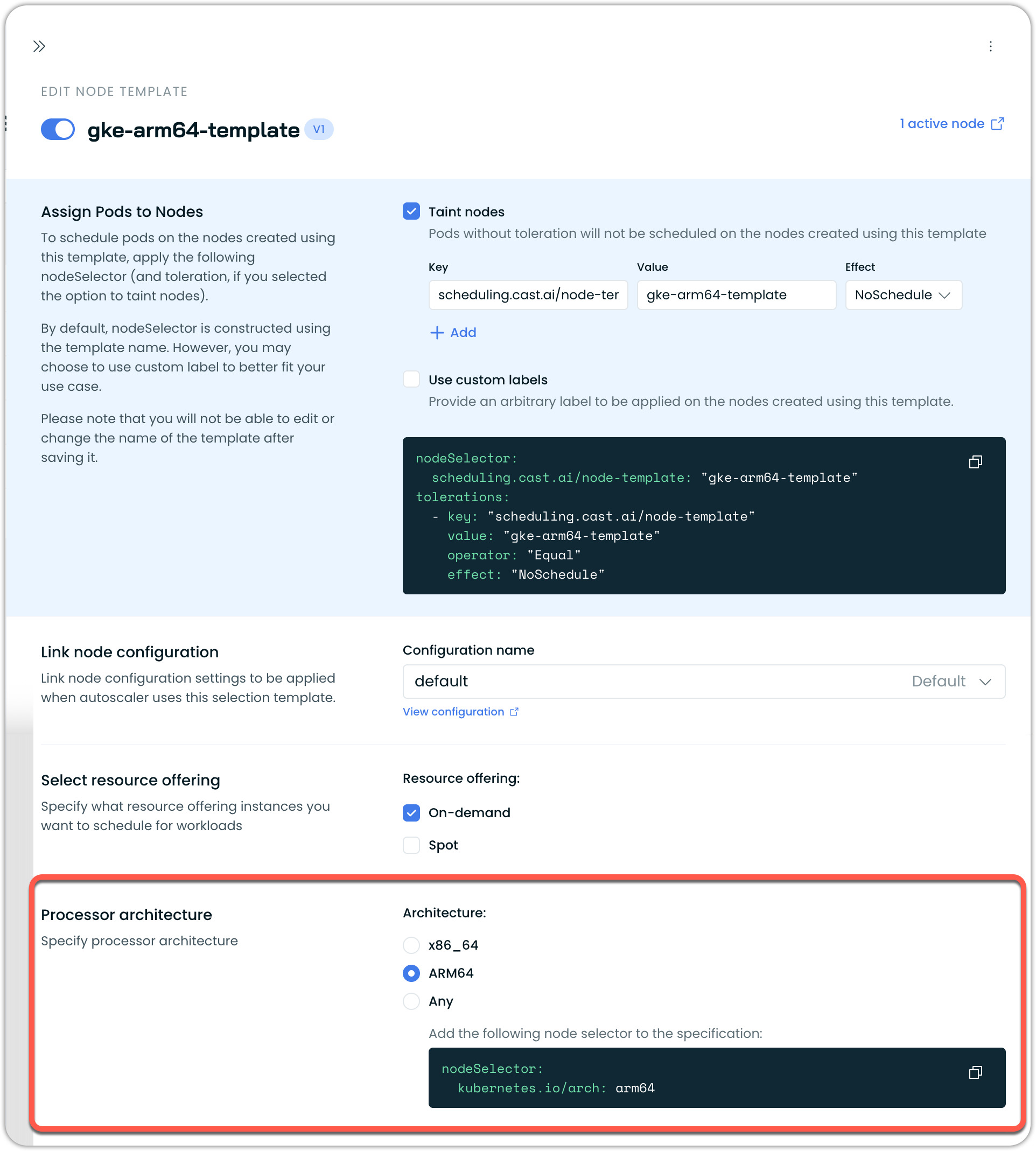
Step 1: Create an ARM-specific node template
- Navigate to Cluster → Autoscaler → Node templates in the Cast AI console
- Create a new node template for ARM workloads
- Set the processor architecture to ARM
- Configure a taint to separate ARM and x86 workloads (recommended)
Step 2: Configure your ARM workloads
Add nodeSelector and tolerations to workloads that should run on ARM nodes:
nodeSelector:
kubernetes.io/arch: arm64
tolerations:
# For node template taint (if configured)
- key: "scheduling.cast.ai/node-template"
value: "your-arm-template-name"
operator: "Equal"
effect: "NoSchedule"
# For GKE (required)
- key: "kubernetes.io/arch"
value: "arm64"
operator: "Equal"
effect: "NoSchedule"Your x86-only workloads will continue using the x86 node template without changes.
Multi-architecture clusters
Use this approach when your workloads are built with multi-architecture support and can run on both ARM and x86.
Custom image limitationIf you use custom images in your node configuration, you cannot use the Any architecture selection. Node configurations can only specify one custom image, but ARM and x86 architectures require different images. For custom images, you must create separate node templates with architecture-specific node configurations.
Step 1: Configure your node template
- Navigate to Cluster → Autoscaler → Node templates in the Cast AI console
- Modify your existing node template or create a new one
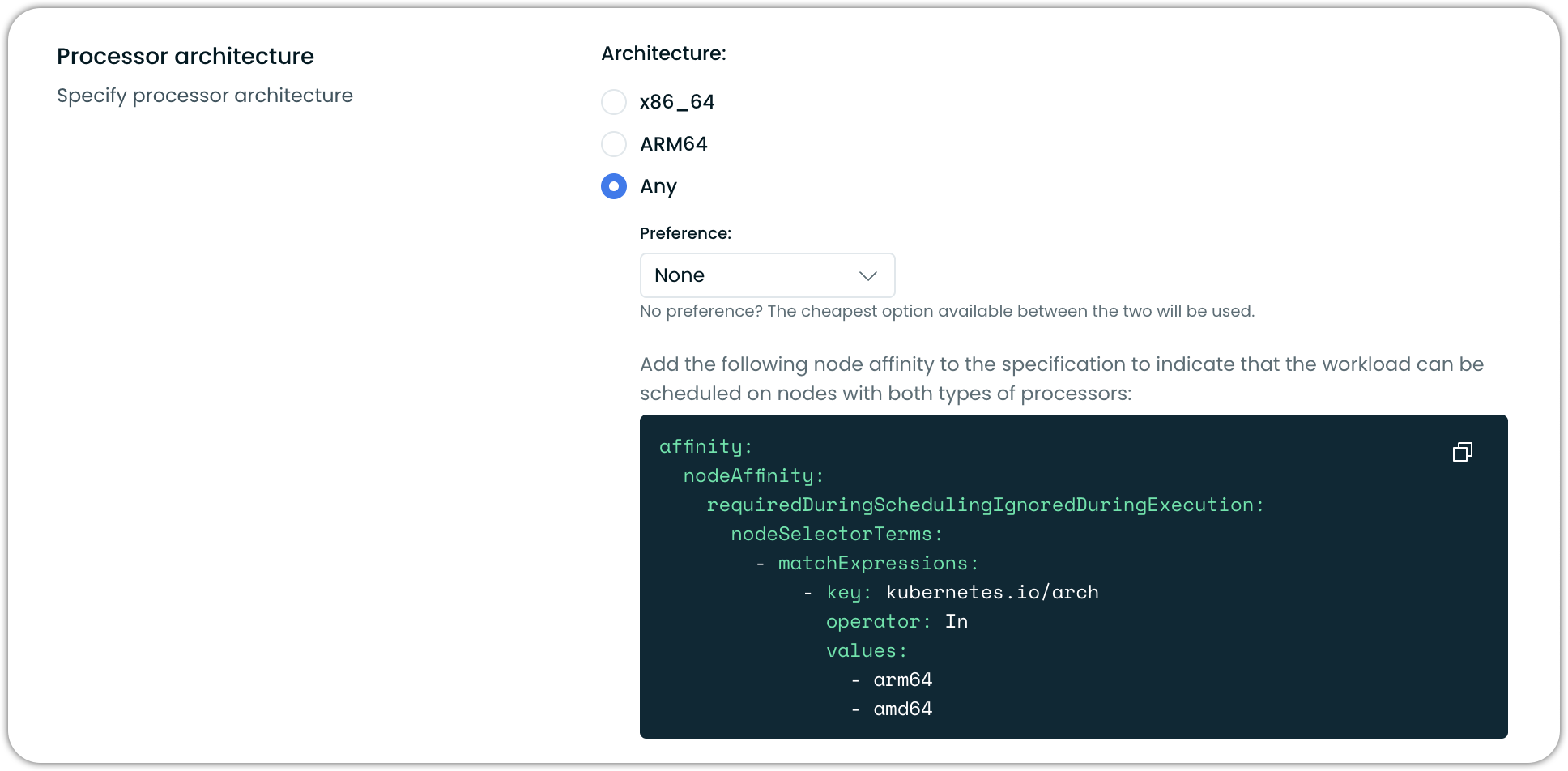
- Set the processor architecture to Any
Cast AI will present the nodeAffinity configuration in the UI when you select Any processor architecture:
Step 2: Configure your workloads
Add nodeAffinity to workloads to specify that they can run on both architectures:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- arm64
- amd64Architecture scheduling behavior
When using multi-architecture configurations, Cast AI determines node selection based on:
- User preference: You can set a preference for ARM or x86_64 (AMD64)
- Cost optimization: If no preference is set, Cast AI selects the most cost-effective option
- Workload constraints: nodeSelector, nodeAffinity, and tolerations guide scheduling decisions
Estimating cost savings
Use the Cast AI console to estimate potential savings from ARM adoption:
- Go to the Cast AI console and select your cluster
- Click on the Available Savings panel
- Enable the ARM support toggle
- Set the percentage of CPUs you plan to run on ARM
- Review the estimated savings percentage
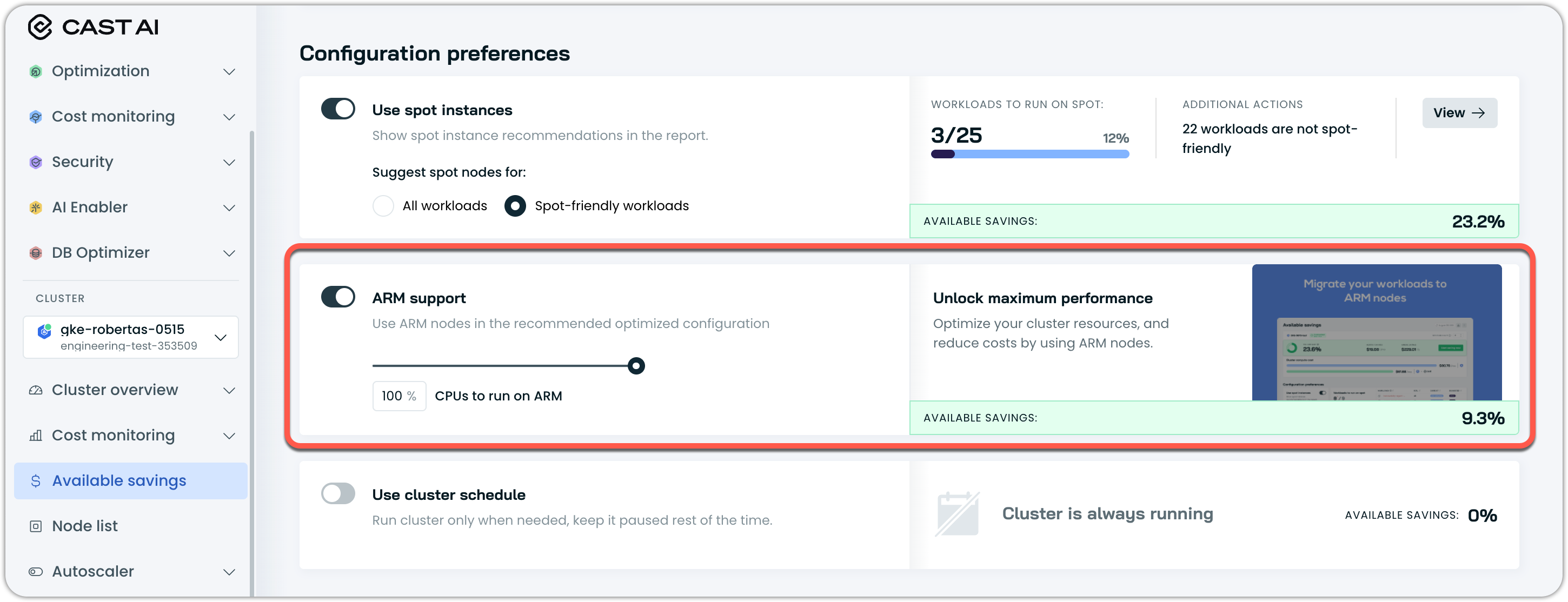
Actual savings will vary depending on factors like spot pricing and workload characteristics.
Risks and considerations
Architecture compatibility risks
The primary risk involves workload scheduling conflicts:
- x86-only workloads will fail if scheduled on ARM nodes
- ARM-only workloads will fail if scheduled on x86 nodes
Mitigate this by using proper node template taints and workload nodeSelectors/tolerations.
Troubleshooting
Cast AI component compatibility
Cast AI components support ARM nodes and can run on ARM-based infrastructure.
Namespace-specific ARM deployment
To provision ARM instances for specific namespaces:
- Create dedicated node templates for ARM workloads
- Apply nodeSelector or tolerations to all workloads in the target namespace
- Use the node template taint configuration to ensure proper workload placement
Cast AI architecture preference
If workloads have no nodeSelectors or affinities, and your node template allows both architectures, Cast AI will:
- Check for user-defined architecture preferences
- Default to the most cost-effective option if no preference is set
Remember that proper configuration of node template taints, architecture settings, and workload nodeSelectors/tolerations is essential for ensuring applications are scheduled on the correct architecture based on their compatibility requirements.