
Hosted model deployment
Model deployments
The Model deployments feature allows you to deploy and manage AI models directly in your Cast AI-connected Kubernetes cluster. This guide explains how to set up and use model deployments with Cast AI.
NoteCurrently, Cast AI supports deploying a subset of Ollama models. The available models depend on your cluster's region and GPU availability.
Prerequisites
Before deploying models, ensure your cluster meets these requirements:
-
Cluster connectivity: The cluster must be connected to Cast AI and running in automated optimization mode (Phase 2)
-
GPU drivers installation: GPU drivers must be installed on your cluster with the correct tolerations:
- Follow the GPU driver installation guide to check if your CSP provides drivers or if you need to set them up (if they are not installed).
Important for Bottlerocket usersBottlerocket AMIs come with pre-installed NVIDIA drivers. Do not install additional NVIDIA device plugins, as they may conflict with the pre-installed drivers. For more information, see the Bottlerocket documentation.
-
GPU daemonset tolerations: Your GPU
daemonsetmust include this required toleration:tolerations: - key: "scheduling.cast.ai/node-template" operator: "Exists"You can apply the GPU daemonset toleration using the following command:
kubectl patch daemonset <daemonset-name> -n <daemonset-namespace> --type=json -p='[{"op": "add", "path": "/spec/template/spec/tolerations", "value": [{"key": "scheduling.cast.ai/node-template", "operator": "Exists"}]}]' -
ARM node GPU compatibility: If using ARM-based nodes (such as AWS Graviton), ensure that any GPUs attached to those nodes have NVIDIA Compute Capability 8.0 or higher. Self-hosted models will not be placed on ARM nodes with GPUs below this threshold.
Compatible ARM GPU examples:
- NVIDIA A100, A30 (Ampere architecture)
- NVIDIA H100, H200 (Hopper architecture)
- NVIDIA B200, GB200 (Blackwell architecture)
Critical for GKE usersCast AI requires container-optimized images for GPU nodes on GKE. Ubuntu-based node images are not supported for GPU workloads and will cause deployment failures. See GKE GPU troubleshooting below for detailed instructions.
Setting up a cluster for model deployments
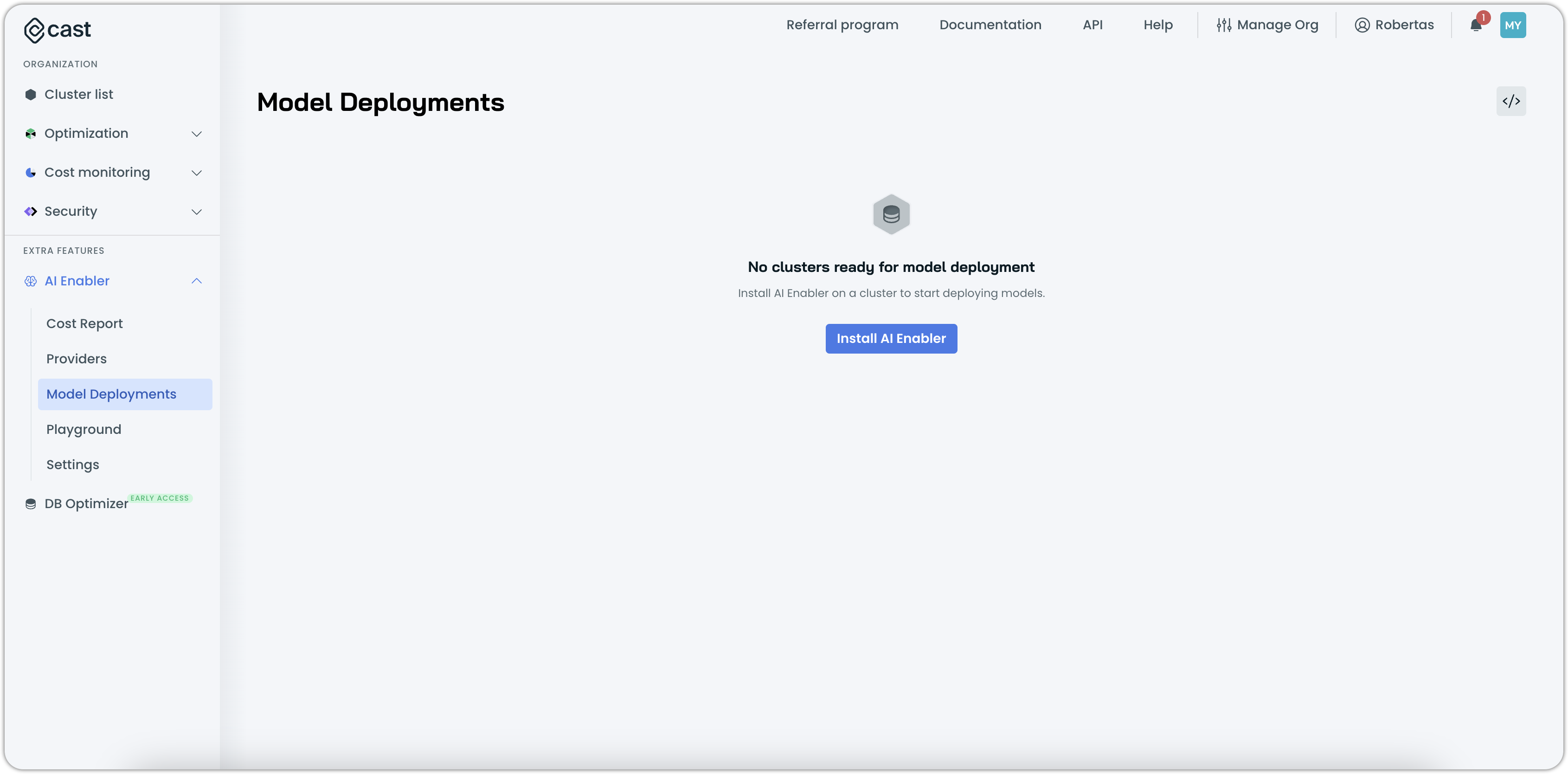
- Navigate to AI Enabler > Model Deployments in the Cast AI console.
- Click Install AI Enabler.
- Select your cluster from the list.
NoteOnly eligible clusters will appear in this list.
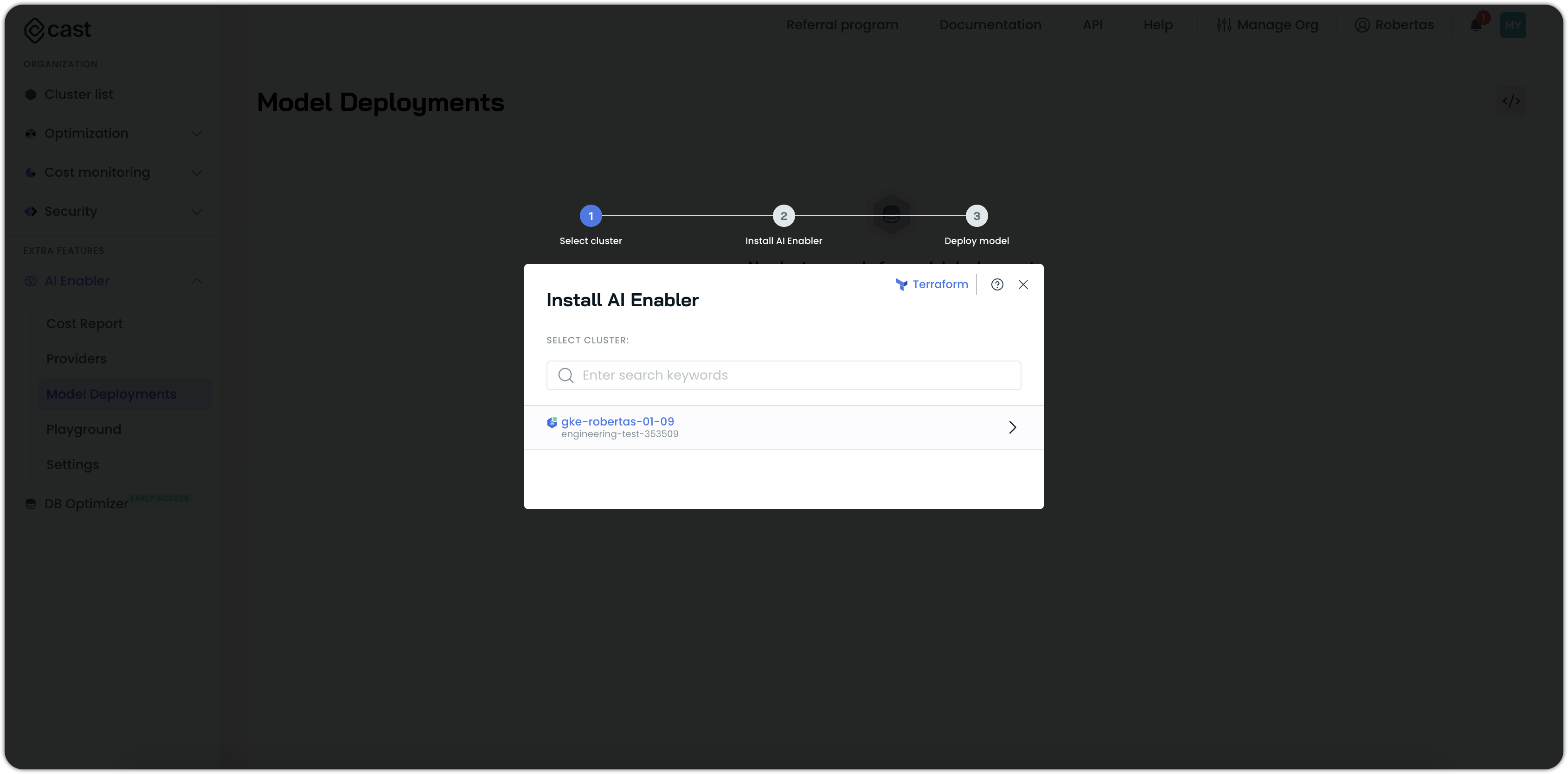
- Run the provided script in your terminal or cloud shell.
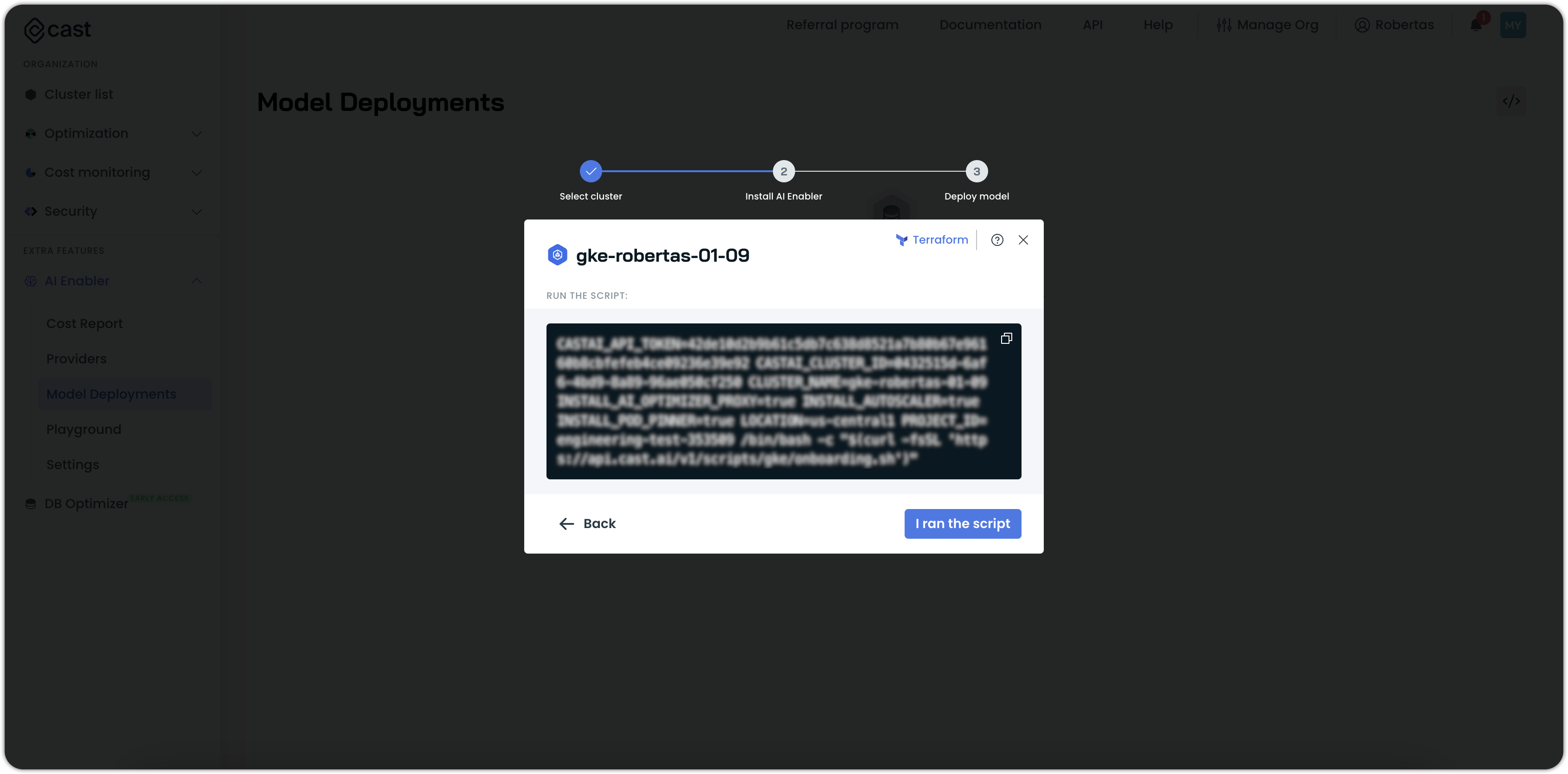
- Wait for the installation to complete.
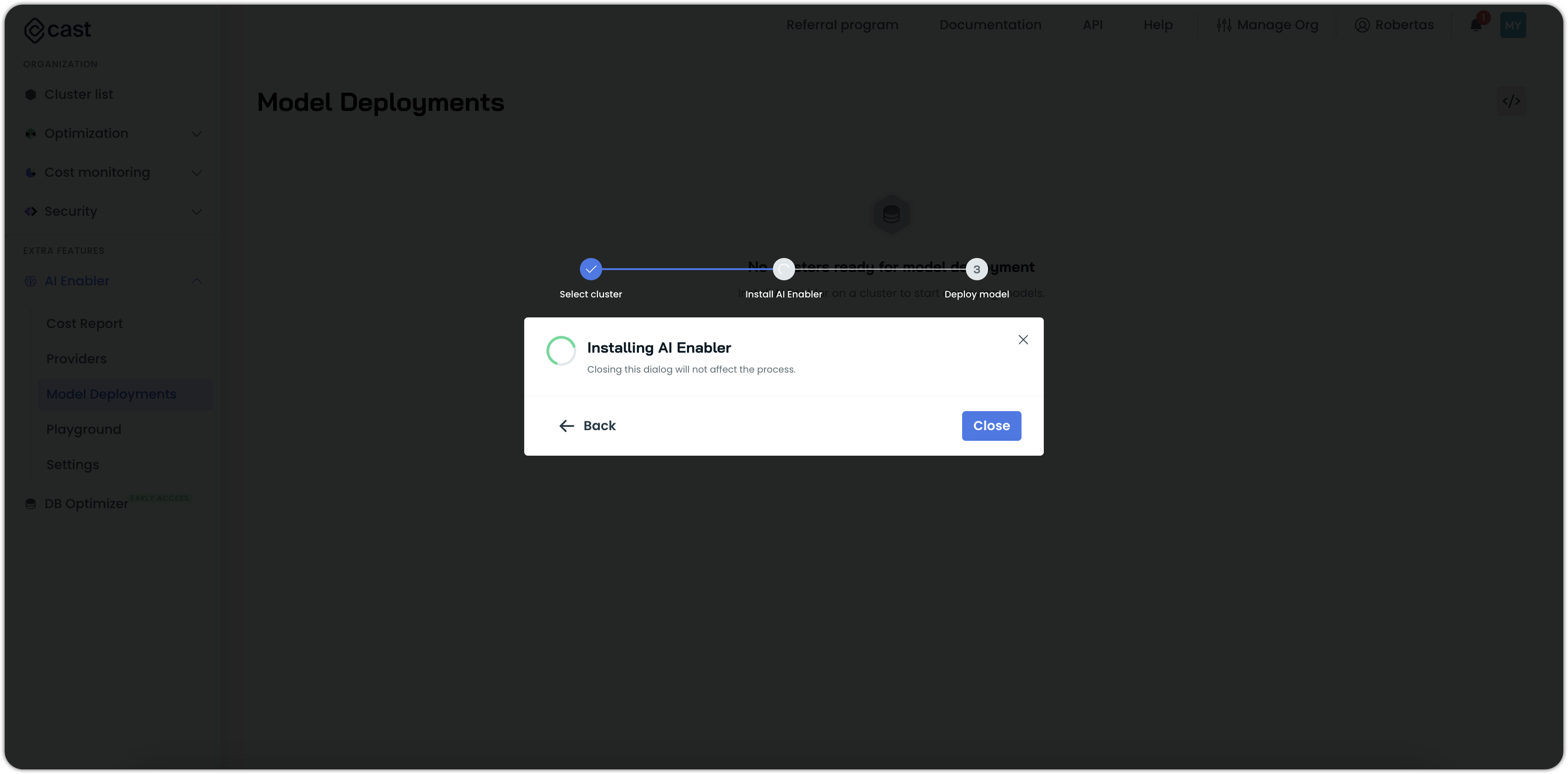
Deploying a model
Once the AI Enabler is installed, you can deploy models to your cluster:
NoteWhen you deploy a model, Cast AI automatically enables the Unscheduled pods policy if it is currently disabled. The policy will only affect model deployments since Cast AI activates just the node template for hosted models while keeping all other templates disabled.
- Select your cluster.
- Choose a supported model from the list.
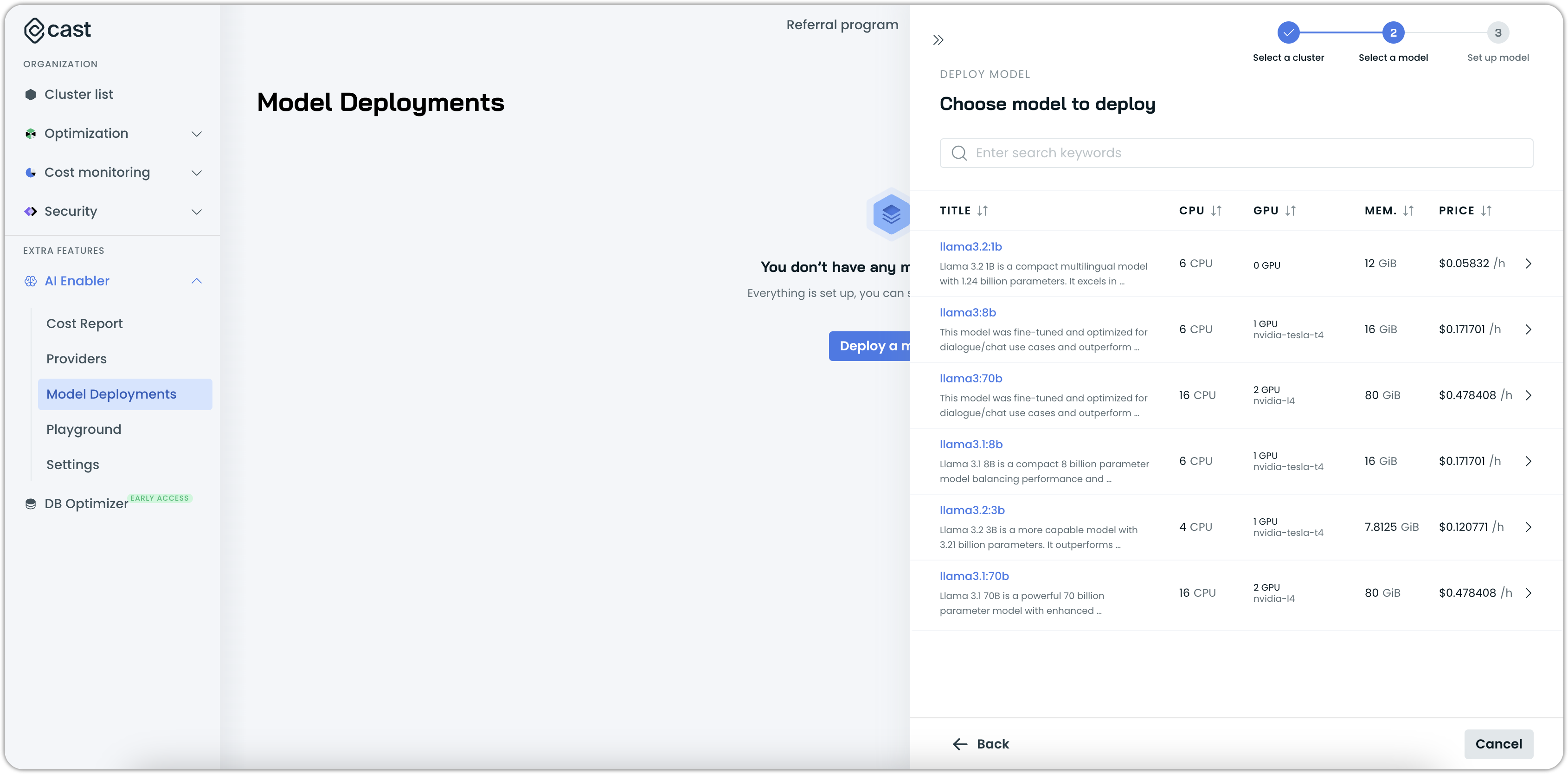
Note about GPU availabilitySome models require specific GPU types. For example, 70b models need A100 GPUs. If the required GPU type is not available in your cluster's region, the model won't be shown as an available option.
- Configure the deployment:
- Specify a service name and port for accessing the deployed model within the cluster.
- Select an existing node template or let Cast AI create a custom template with the recommended configuration.
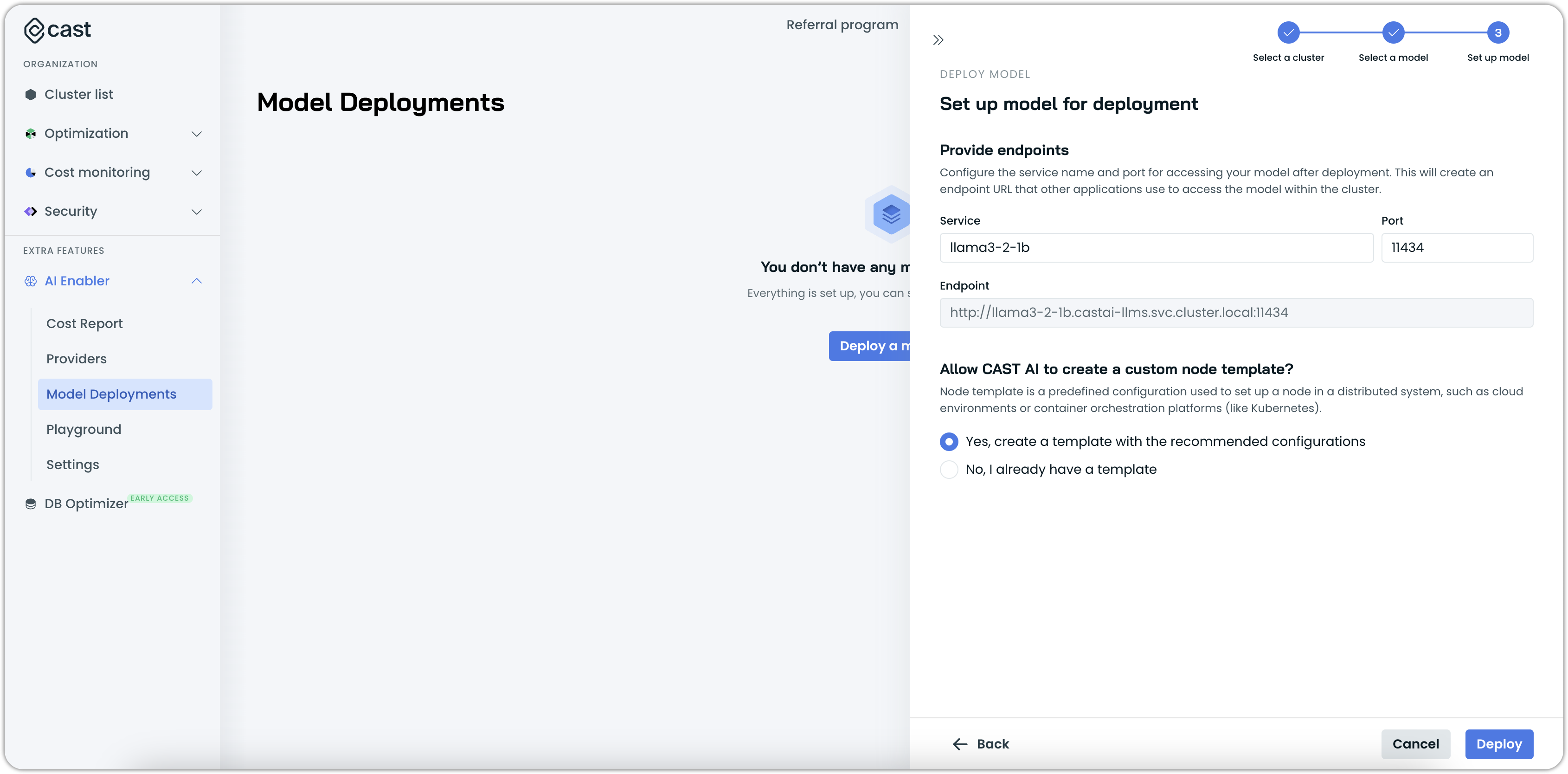
- Click Deploy to start the deployment.
The model will be deployed in the castai-llms namespace. You can monitor the deployment progress on the Model Deployments page. Once the deployment is finished, the model status will change from Deploying to Running.
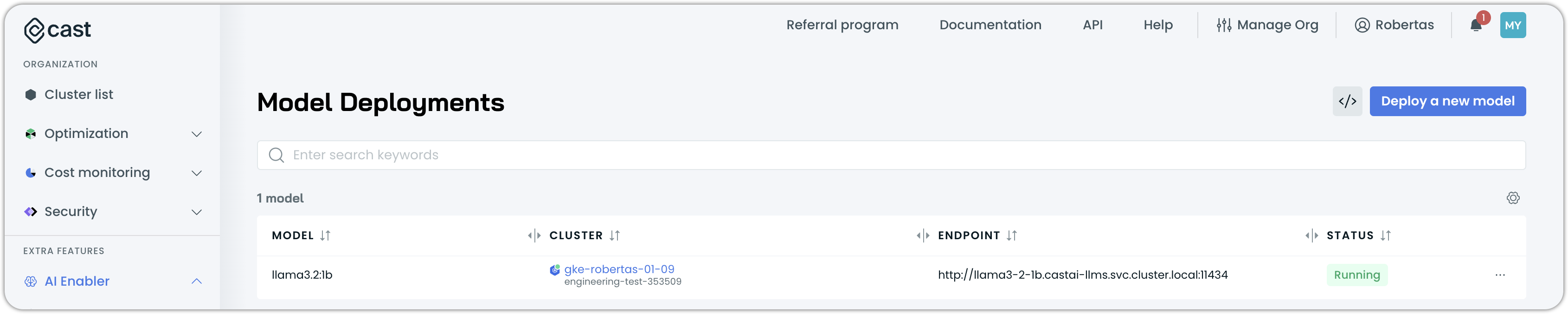
Alternatively, you can monitor the deployment progress using the following command in your cloud shell or terminal:
kubectl get pod -n castai-llms
NoteModel deployment may take up to 25 minutes.
Supported models
Cast AI supports various hosted models. The available models depend on several factors:
- Your cluster's region
- Available GPU types in that region
To get a current list of supported models and their specifications, including pricing and GPU requirements use the List hosted model specs API endpoint:
GET /ai-optimizer/v1beta/organizations/{organizationId}/clusters/{clusterId}/hosted-modelsUsing deployed models
The deployed models are accessible through the AI Enabler Proxy, which runs in the castai-agent namespace as the castai-ai-optimizer-proxy component. You can access the proxy in several ways, detailed below.
From within the cluster
Use the following endpoint:
http://castai-ai-optimizer-proxy.castai-agent.svc.cluster.local:443/openai/v1Example request:
curl http://castai-ai-optimizer-proxy.castai-agent.svc.cluster.local:443/openai/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'X-API-Key: {CASTAI_API_KEY}' \
-X POST -d '{
"model": "deepseek-r1:14b",
"messages": [
{
"role": "user",
"content": "What kind of instance types to use in GCP for running an AI training model?"
}
]
}'From your local machine
You can access the models by port forwarding to the service, for example:
# Port forward to the proxy service
kubectl port-forward svc/castai-ai-optimizer-proxy 8080:443 -n castai-agent
# Make requests to the forwarded port
curl http://localhost:8080/openai/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'X-API-Key: {CASTAI_API_KEY}' \
-X POST -d '{
"model": "deepseek-r1:14b",
"messages": [
{
"role": "user",
"content": "What kind of instance types to use in GCP for running an AI training model?"
}
]
}'Troubleshooting
GKE GPU provisioning issues
Ubuntu image compatibility error
Issue: GPU nodes fail to provision on GKE clusters using Ubuntu node pools.
Cause: Cast AI requires container-optimized images for GPU nodes. Ubuntu-based images are not supported for GPU workloads.
Solution: Configure a node template with container-optimized images:
- Create a node configuration with a container-optimized image in the Image field
- Create or update the
llms-by-castainode template and link it to this configuration - Use this template for model deployment
Custom GPU image naming error
Error: "finding GPU attached instance image for "cluster-api-ubuntu-2204-v1-27.*nvda"
Cause: Cast AI only supports GCP default GPU images. Custom images must follow GCP NVIDIA image naming patterns.
Solution: If using custom images, ensure they follow the GCP NVIDIA naming convention:
// Images with version in name:
gke-1259-gke2300-cos-101-17162-210-12-v230516-c-nvda
// Images without version in name:
gke-12510-gke1200-cos-101-17162-210-18-c-cgpv1-nvdaFor additional assistance, contact Cast AI Customer Success or visit our community Slack channel.