
How-to: Create a scaling policy
Creating scaling policies
Creating custom scaling policies allows you to define specific optimization strategies tailored to your workload requirements. The policy creation process involves configuring settings and defining assignment rules to automatically assign workloads in your cluster to the appropriate policies.
Create a new scaling policy
To create a new scaling policy:
- From the Scaling policies page, click Create scaling policy
- Enter a unique name for your policy
- Configure your policy settings
- Configure assignment rules
- Review and save your configuration
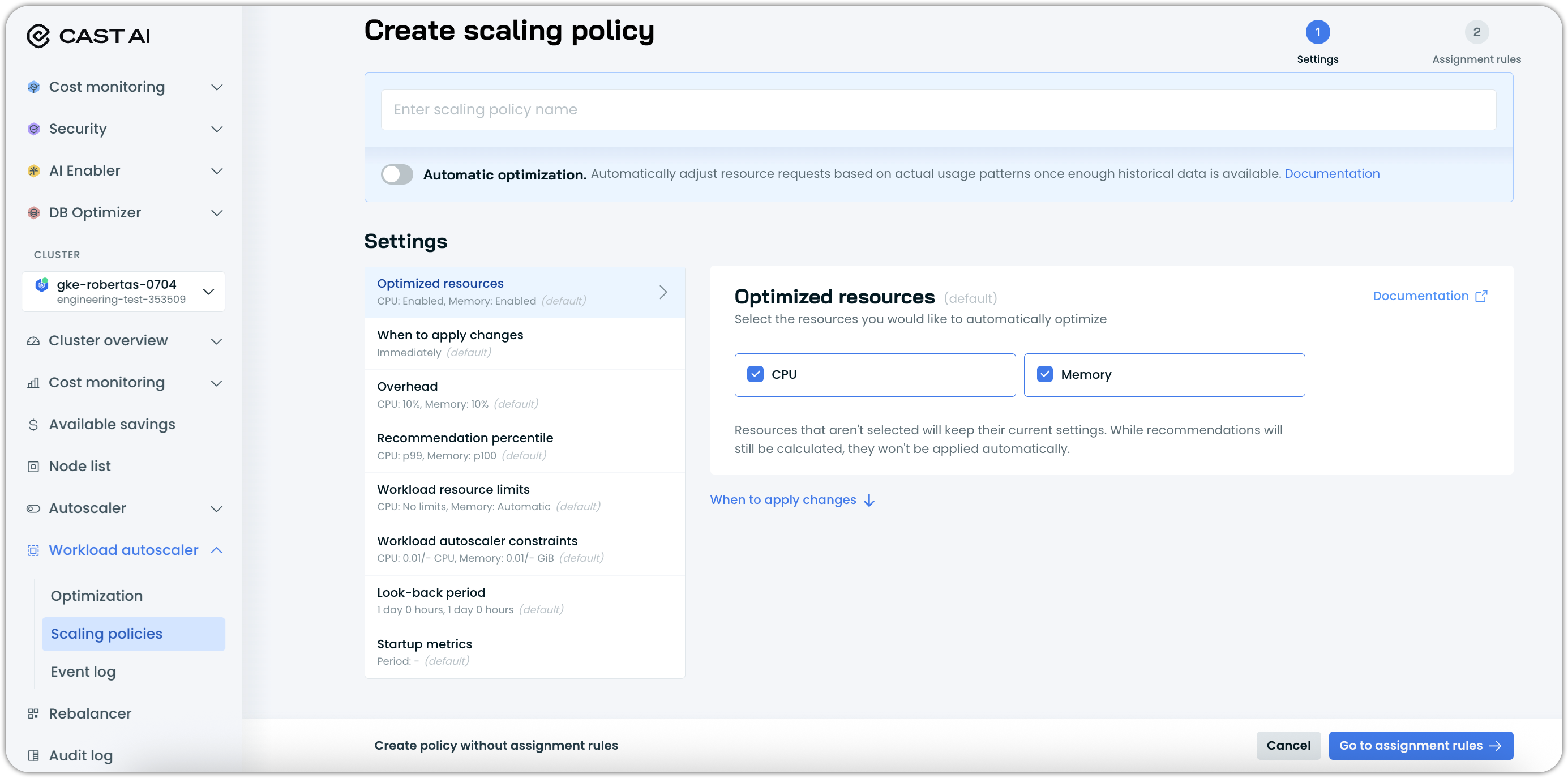
Configure policy settings
The Settings step allows you to define how the policy will optimize workloads. Key configuration options include:
- Automatic optimization – Whether to automatically apply recommendations to workloads assigned to this policy
- Optimized resources – Which resources (CPU and/or Memory) to optimize
- Container exclusions – Which specific containers to exclude from optimization (e.g., service mesh sidecars)
- When to apply changes – Whether to use immediate or deferred scaling mode
- Recommendation percentile – Which usage percentile to target for optimization
- Overhead settings – Additional resource buffer to add to recommendations
- Resource constraints – Minimum and maximum limits for scaled resources
- Look-back period – Historical data window for generating recommendations
- Startup metrics – Whether to ignore initial resource usage spikes
- Stall detection – CPU stall and pod thresholds for PSI-aware scaling that detects hidden CPU contention
- HPA converter – Converts percentage-based HPA utilization targets to fixed absolute values when vertical optimization adjusts resource requests, preventing HPA scaling drift. See HPA converter for details.
- Horizontal autoscaling (optional) – Pod count range, utilization triggers (CPU/memory), autoscaling behavior (stabilization windows, scaling policies), and HPA ownership settings. See Horizontal autoscaling in scaling policies for a dedicated guide.
For detailed information about vertical scaling configuration options and their impact on workload optimization, see Workload autoscaling settings.
JVM workload optimization
Java workloads manage memory through the JVM heap, which standard container memory metrics do not reflect. Cast AI provides JVM-specific optimization using actual heap data and can automatically instrument Java containers to collect these metrics — no application changes required.
For details on how JVM optimization works, how to enable it, configuration reference, known limitations, and troubleshooting, see JVM workload optimization.
Configure assignment rules
Assignment rules define which workloads are automatically assigned to your scaling policy. This feature allows you to create intelligent assignment criteria based on workload characteristics.
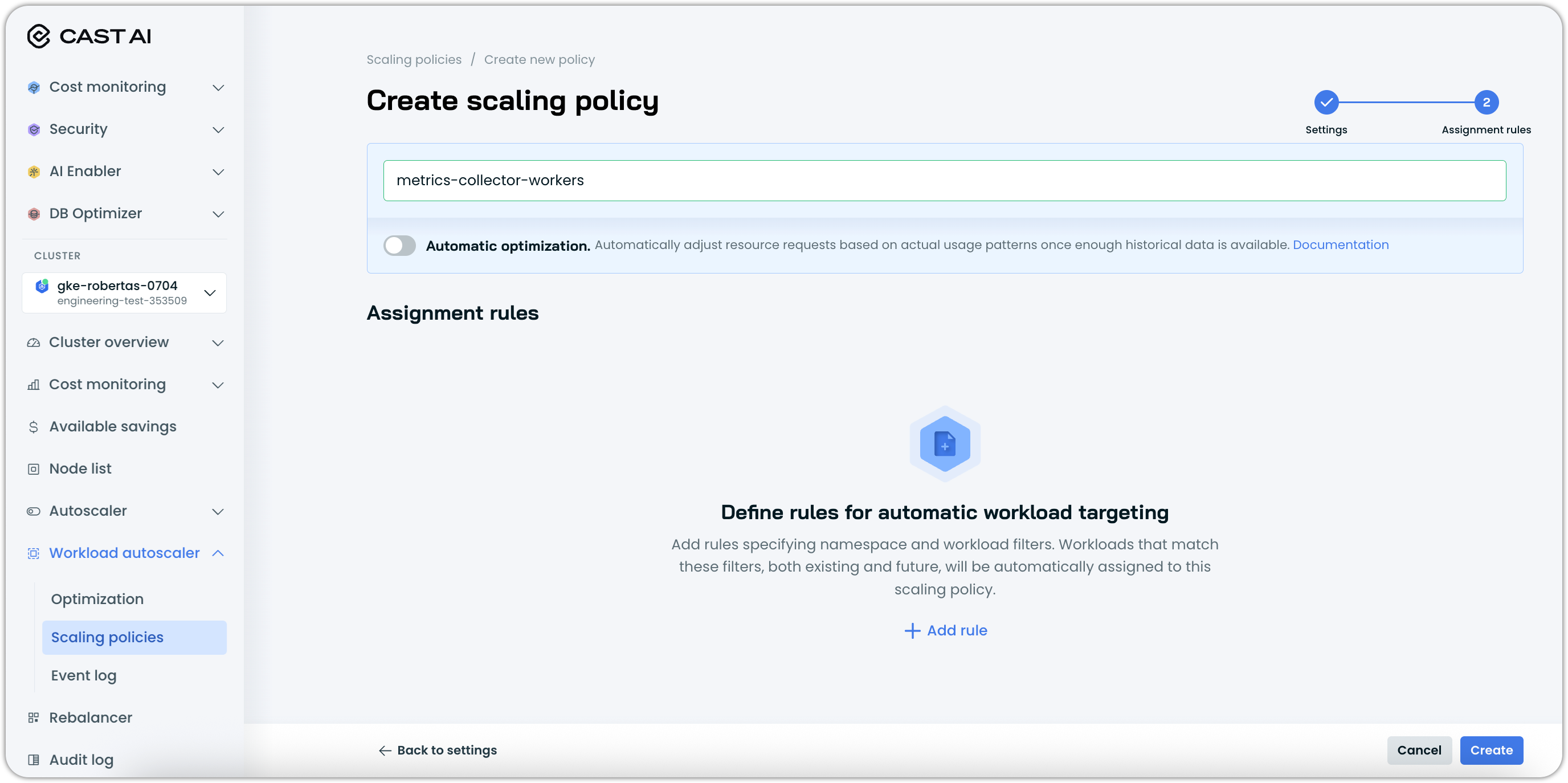
To configure assignment rules:
- In the Assignment rules step, click Add rule
- Define your assignment criteria using the available filters:
- Namespaces - Target workloads in specific namespaces
Cast AI supports regex for namespace matching, allowing flexible namespace targeting:
Examples:["production", "kube-system"]- Matches exact namespace names["dev-.*", "test-.*"]- Matches any namespace starting with "dev-" or "test-"["(test|sandbox)"]- Matches either "test" or "sandbox" namespaces["^app-[0-9]+$"]- Matches namespaces like "app-1", "app-42", etc.Regex syntaxCast AI uses Go regex syntax (RE2).
- Workload type - Filter by workload kinds (Deployment, StatefulSet, DaemonSet, Job, CronJob)
- Workload labels - Use label key-value pairs to identify workloads
For more details on configuring complex rules, see below.
- Namespaces - Target workloads in specific namespaces
- Add multiple rules if needed to capture different workload patterns
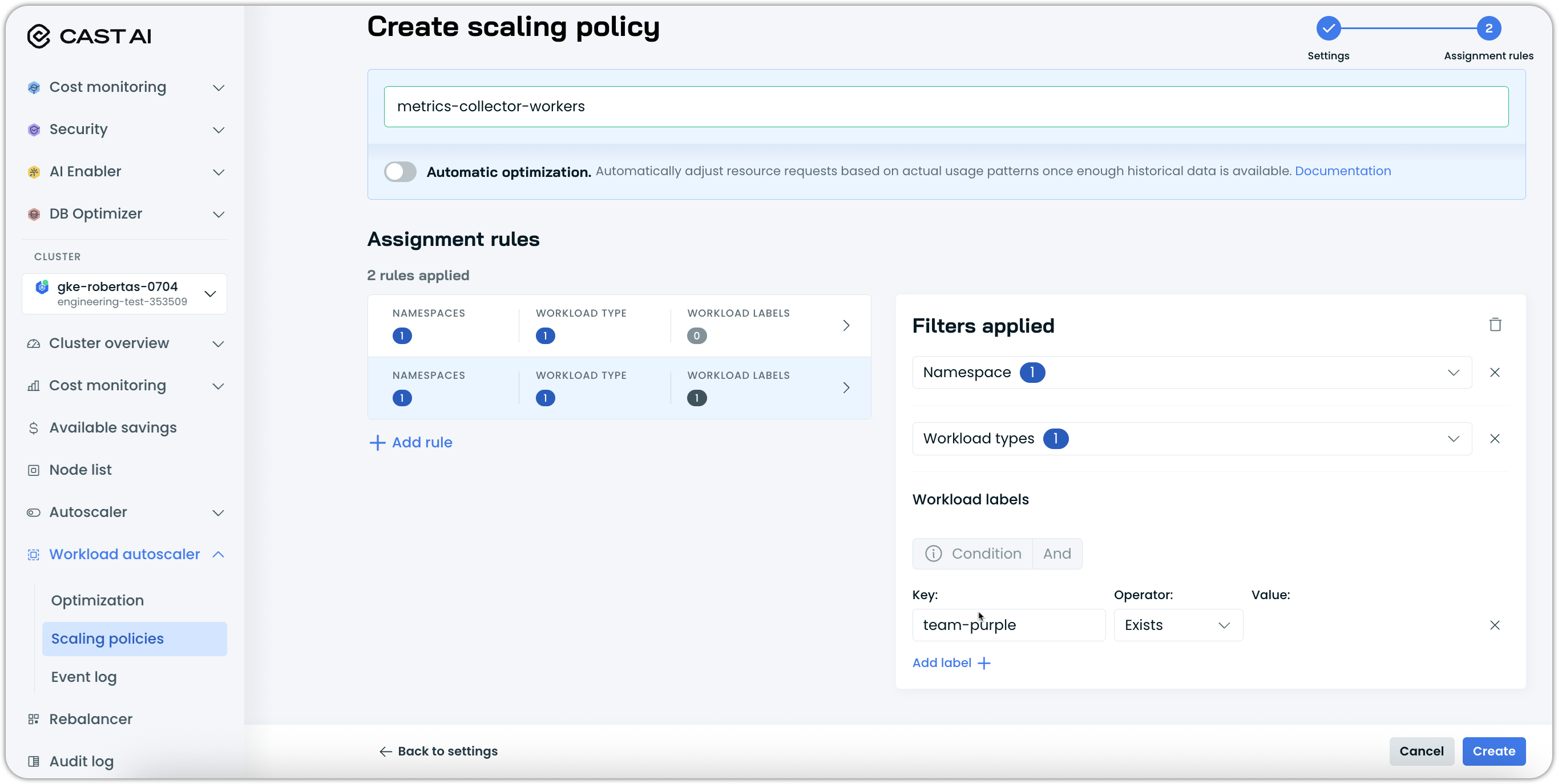
Policy assignment priority hierarchy
When multiple assignment rules could apply to the same workload, Workload Autoscaler follows a strict priority hierarchy, which is outlined below.
Assignment priority order
Workload Autoscaler evaluates workload assignments in the following priority order:
-
Manual/Explicit Assignment
- API assignments – Policies assigned via the Cast AI API
- Annotation assignments – Policies specified using
workloads.cast.ai/configurationwithscalingPolicyName. If the specified policy name does not match any existing policy, the workload falls back to system defaults (resiliencyfor StatefulSets,balancedfor others). - Direct UI assignments – Policies manually assigned through the Optimization page in the Cast AI Console
-
Assignment Rules
- Evaluated based on policy priority order (as configured in the policies table)
- The first matching policy wins
- Within each rule, all conditions must match (
ANDlogic) - A workload matching any rule in a policy is assigned to that policy (
ORlogic between rules)
-
System Defaults
If workloads have not been manually assigned to policies, and if no assignment rules match them, they will be moved to default system scaling policies:- StatefulSets:
resiliency - All other workloads:
balanced
- StatefulSets:
How assignment rules are evaluated
When multiple policies have assignment rules that could match the same workload:
- Rules are evaluated in policy priority order (as arranged in the policies table)
- The first matching rule assigns the workload to that policy
- Workloads that don't match any rules fall back to system defaults if they are not manually assigned to a policy
Understanding rule logic:
-
Within a single rule (
ANDlogic): All conditions in a rule must match. If a rule specifies namespaceproduction, workload typeDeployment, and labelapp=frontend, a workload must satisfy all three conditions to match that rule. -
Between rules in a policy (
ORlogic): A workload needs to match only one rule to be assigned. If a policy has Rule 1 and Rule 2, matching either rule assigns the workload to that policy.
To require multiple criteria, combine them into a single rule. To match workloads meeting different criteria, use separate rules.
Important considerations
Assignment rule overrides:
Even if you have carefully configured assignment rules, workloads may not follow them if they have been manually assigned via API, annotations, or the UI. Manual assignments always take precedence over assignment rules.
Asynchronous propagation:
For large clusters, when you update policy order or assignment rules, changes may take several seconds or more to propagate since the reassignment process is handled asynchronously. After making such changes, refresh the Console to see them take effect; only then make additional changes.
Duplicate a system policy
If you want to use a system policy as a starting point but need to customize it or create a modified version of any of your existing policies, do the following:
- Navigate to Workload Autoscaler > Scaling policies
- Find the policy you wish to duplicate in the policies table
- Click the duplicate option for that policy
- The system creates a fully editable copy with all the original settings
- Modify any settings as needed in the configuration interface
- Configure assignment rules to define workload assignment criteria
- Save your customized policy
NoteThe
readonlypolicy cannot be duplicated as it is reserved for Cast AI components.
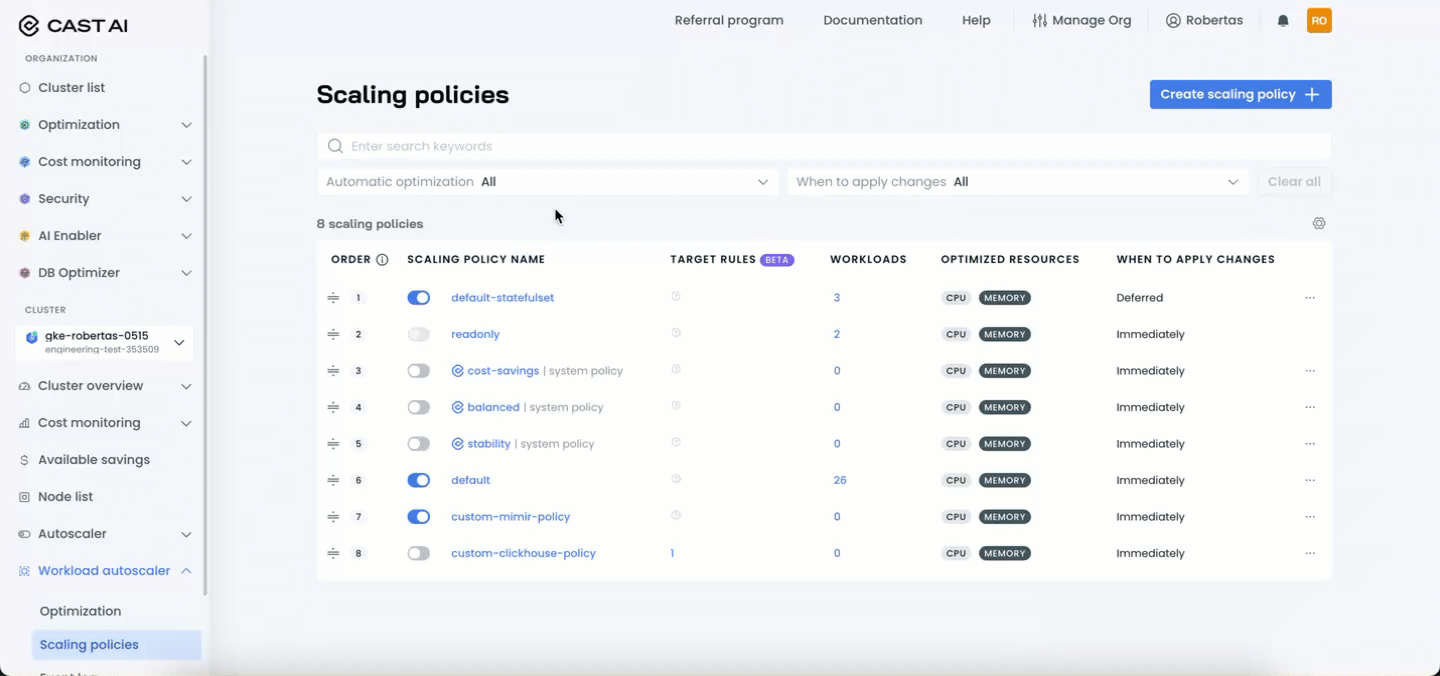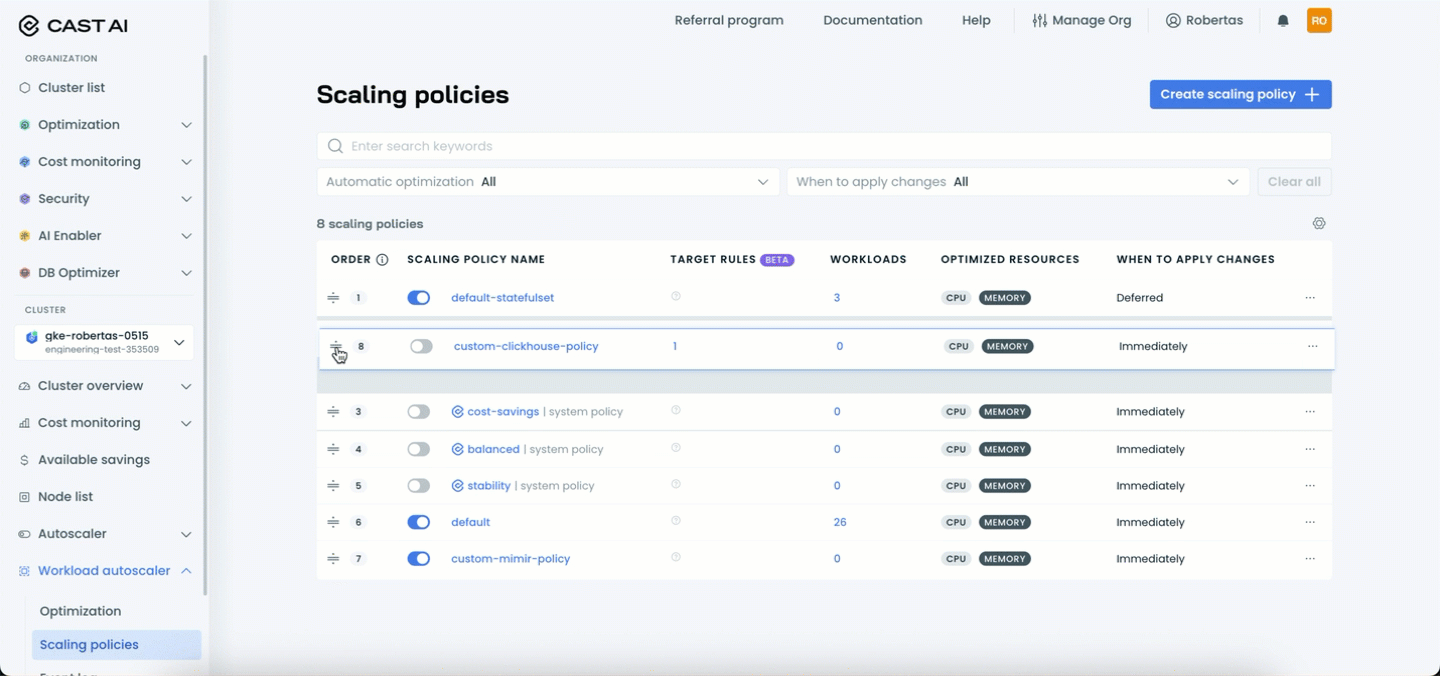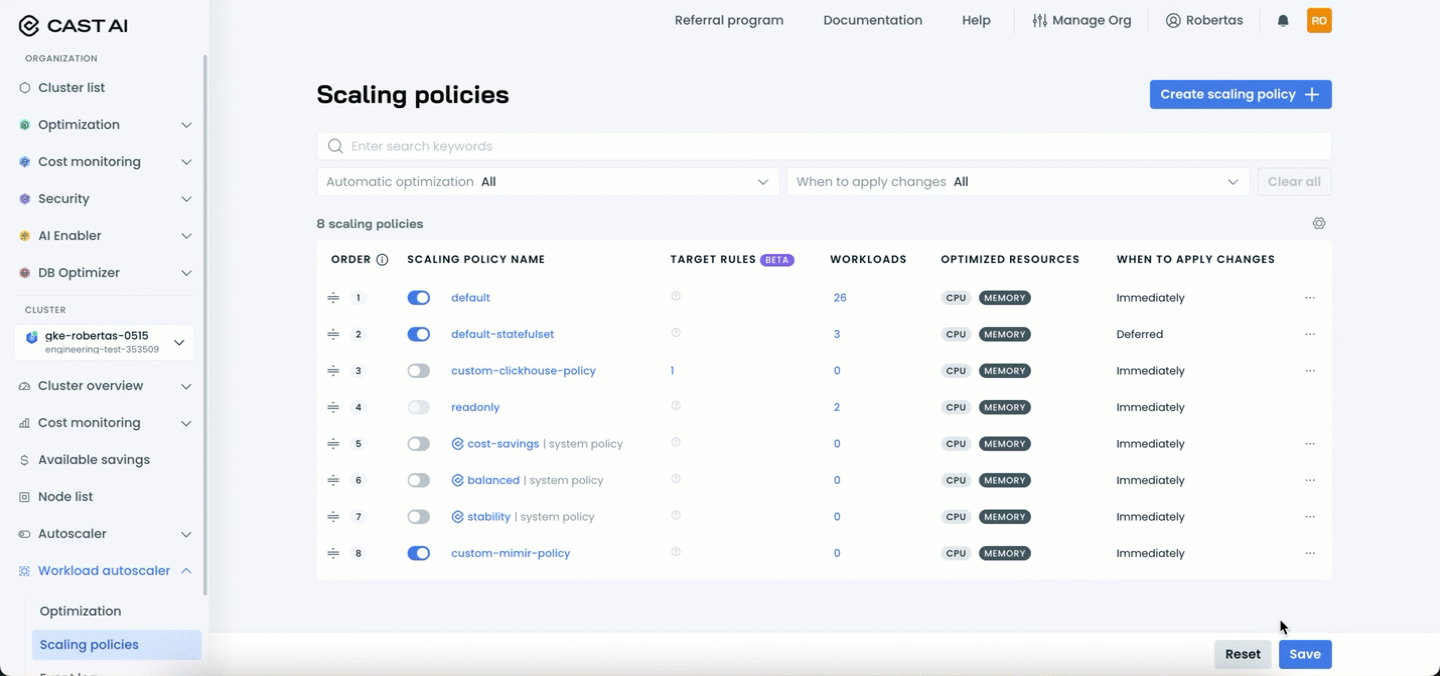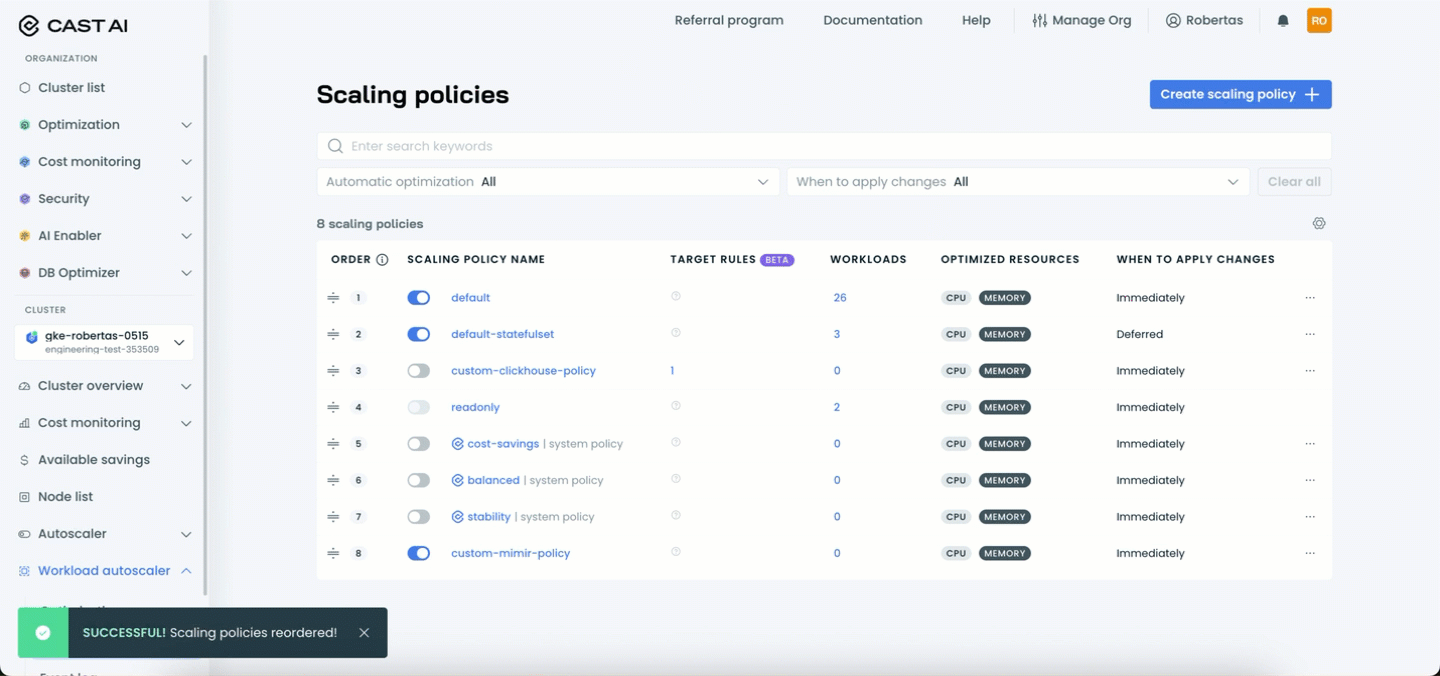
Managing policy priority
You can adjust the priority order of your scaling policies by rearranging them in the policies table. Policy priority determines which policy a workload is assigned to when multiple policies have assignment rules that could match the same workload.
To change policy priority:
- Navigate to the Scaling policies page
- Use the drag handle (≡) on the left side of each policy row
- Drag and drop policies to reorder them according to your desired priority
- Click Save to apply the new priority order
NoteThis change is propagated asynchronously, so it may take some time to be reflected in the system. Workloads will be gradually reassigned to the newly ordered matching policy.
Policies higher in the list (lower order numbers) have higher priority and will be evaluated first when determining workload assignments. This allows you to create a hierarchy where more specific policies take precedence over general ones.
Alternative creation methods
While the Cast AI console provides a user-friendly interface for creating scaling policies, you can also create and manage policies programmatically using the Cast AI API or Terraform.
API integration
You can create scaling policies with assignment rules using the Workload Optimization API.
Basic API policy creation example
When creating a scaling policy via API, you define both the optimization settings and the assignment rules that determine which workloads the policy applies to. Here's a complete example:
{
"name": "production-frontend-policy",
"applyType": "IMMEDIATE",
"managementPolicy": "MANAGED",
"cpu": {
"target": "p95",
"overhead": 0.05
},
"memory": {
"target": "max",
"overhead": 0.10
},
"assignmentRules": [
{
"workload": {
"gvk": ["Deployment", "StatefulSet"],
"labelsExpressions": [
{
"key": "tier",
"operator": "KUBERNETES_LABEL_SELECTOR_OP_IN",
"values": ["frontend", "web"]
}
]
}
},
{
"namespace": {
"names": ["production", "prod-frontend"]
}
}
]
}This example creates a scaling policy that:
- Applies immediate scaling (recommendations applied as soon as thresholds are met)
- Targets the 95th percentile for CPU usage with 5% overhead
- Uses maximum observed memory usage with 10% overhead
- Automatically assigns to Deployments or StatefulSets with
tier=frontendortier=weblabels - OR assigns to any workloads in
productionorprod-frontendnamespaces
Assignment rule structure in API
Assignment rules in the API follow a specific structure that allows for complex workload matching. Each policy can contain multiple assignment rules, and each rule can match based on workload characteristics, namespace properties, or both.
Rule composition:
- Each
assignmentRulecan contain aworkloadmatcher, anamespacematcher, or both - Multiple matchers within a single rule are combined with AND logic
- Multiple rules within a policy are combined with OR logic
Workload matching capabilities:
| Field | Type | Description | Example |
|---|---|---|---|
gvk | Array | Kubernetes workload types to match | ["Deployment", "StatefulSet"] |
labelsExpressions | Array | Label-based matching conditions | See label operators table below |
Namespace matching:
| Field | Type | Description | Example |
|---|---|---|---|
names | Array | Specific namespace names to match | ["production", "staging"] |
Advanced assignment rules for policy creation
When creating scaling policies via API, you have access to sophisticated assignment rule matching capabilities. These capabilities allow you to create highly specific policies that automatically assign workloads based on complex criteria.
Label operators for workload matching:
| Operator | Requires values field | Description |
|---|---|---|
KUBERNETES_LABEL_SELECTOR_OP_CONTAINS | Yes | Label value contains the specified substring. If no key is specified, checks all workload labels |
KUBERNETES_LABEL_SELECTOR_OP_REGEX | Yes | Label value matches the specified regex pattern. If no key is specified, checks all workload labels |
KUBERNETES_LABEL_SELECTOR_OP_IN | Yes | Label value must be in the specified list |
KUBERNETES_LABEL_SELECTOR_OP_NOT_IN | Yes | Label value must not be in the specified list |
KUBERNETES_LABEL_SELECTOR_OP_EXISTS | No | Label key must exist (regardless of value) |
KUBERNETES_LABEL_SELECTOR_OP_DOES_NOT_EXIST | No | Label key must not exist |
Workload type matching with GVK format
When defining which workload types your scaling policy should target, you can specify them using the GVK (Group, Version, Kind) format. The gvk field uses Kubernetes' Group/Version/Kind format, following the same pattern as kubectl get commands.
GVK format options:
| Format | Syntax | Use case | Example |
|---|---|---|---|
| Kind only | kind | Match any version of the workload type | "Deployment" matches all Deployments |
| Group + Kind | kind.group | Match specific API group | "Deployment.apps" for apps/v1 Deployments |
| Full GVK | kind.version.group | Match exact API version | "Deployment.v1.apps" for specific version |
GVK follows exactly the same naming pattern as kubectl get. Everything that works with kubectl get command on your cluster can be used as the gvk value.
Label expressions for precise workload targeting
Label expressions provide powerful filtering capabilities when creating scaling policies. They use Kubernetes label selector operators to match workloads based on their labels.
Complete label expression structure:
{
"key": "environment",
"operator": "KUBERNETES_LABEL_SELECTOR_OP_IN",
"values": ["production", "staging"]
}Complex assignment rule example
This example demonstrates how to create a scaling policy with sophisticated assignment rules:
{
"assignmentRules": [
{
"workload": {
"gvk": ["Deployment", "CronJob"],
"labelsExpressions": [
{
"key": "environment",
"operator": "KUBERNETES_LABEL_SELECTOR_OP_IN",
"values": ["production", "staging"]
},
{
"key": "managed-by",
"operator": "KUBERNETES_LABEL_SELECTOR_OP_EXISTS"
},
{
"key": "experimental",
"operator": "KUBERNETES_LABEL_SELECTOR_OP_DOES_NOT_EXIST"
}
]
}
}
]
}This example creates a scaling policy that targets Deployments and CronJobs that are in production or staging environments, have a managed-by label, and don't have an experimental label.
Regex pattern namespace matching example
{
"assignmentRules": [
{
"namespace": {
"names": ["dev-.*", "(test|sandbox)", "prod-frontend-[0-9]+"]
}
}
]
}Assignment rule evaluation in policy creation
Understanding how assignment rules are evaluated is crucial when creating policies with multiple assignment rules:
| Evaluation type | Logic | Description |
|---|---|---|
| Within a rule | AND | All conditions in a single rule (namespace, workload type, labels) must match for that rule to apply |
| Between rules | OR | If a policy has multiple rules, a workload matching any one rule is assigned to that policy |
| Policy priority | First match wins | When multiple policies could match the same workload, the highest-priority policy (first in the table) is applied |
Example: A policy with two rules:
- Rule 1 targeting label
app=api - Rule 2 targeting namespace
staging
matches workloads with the app=api label OR workloads in the staging namespace. To target workloads that have app=api AND are in staging, combine both conditions into a single rule.
Policy priority can be changed via the UI or Terraform. This change is propagated asynchronously, so it may take some time to be reflected in the system. Workloads will be gradually reassigned to the newly ordered matching policy.
Terraform provider
Use the Cast AI Terraform provider to define scaling policies as infrastructure-as-code. This approach is ideal for managing policies consistently across multiple clusters or environments.
For complete documentation and examples, see the Cast AI Terraform provider documentation.
NoteFull assignment rules support including regex patterns and advanced label operators is available in Cast AI Terraform provider v7.58.3 and later. For complete documentation and examples, see the Cast AI Terraform provider documentation.
Next steps
Updated 24 days ago