
Time-slicing
Cast AI supports GPU sharing through time-slicing, which allows multiple workloads to share a single physical GPU by rapidly switching between processes. This feature enables better GPU utilization and cost optimization for workloads that don't require dedicated GPU access.
Monitor your GPU sharing efficiency with GPU utilization metrics once configured.
What is GPU time-slicing?
GPU time-slicing is achieved through rapid context switching, where:
- Each process gets an equal share of GPU time
- Compute resources are assigned to one process at a time
- GPU memory is shared between all processes
- The NVIDIA device plugin manages the sharing configuration
For more information on GPU time-slicing, see:
Supported configurations
| Provider | GPU time-slicing support | Notes |
|---|---|---|
| AWS EKS | ✓ | Available with time-slicing configuration. Supported on Amazon Linux 2023 and Bottlerocket. |
| GCP GKE | ✓ | - |
| Azure AKS | Not yet supported | - |
How it works
- Configuration: Enable GPU sharing in your node template with time-slicing parameters
- Resource calculation: Cast AI calculates extended GPU capacity as
GPU_COUNT * SHARED_CLIENTS_PER_GPU - Node provisioning: The autoscaler provisions nodes in adherence to the specified sharing configuration
- Workload scheduling: Pods continue to request
nvidia.com/gpu: 1- no changes to pod specifications required
Configuring GPU time-slicing
GPU sharing can be configured through multiple methods.
Console UI
GPU sharing is configured through node templates in the Cast AI console:
- Create or edit a node template
- Enable Use GPU time-slicing
- Configure sharing parameters:
- Default shared clients per GPU: The default number of workloads that can share each GPU (1-48)
- Sharing configuration per GPU type: Override defaults for specific GPU models
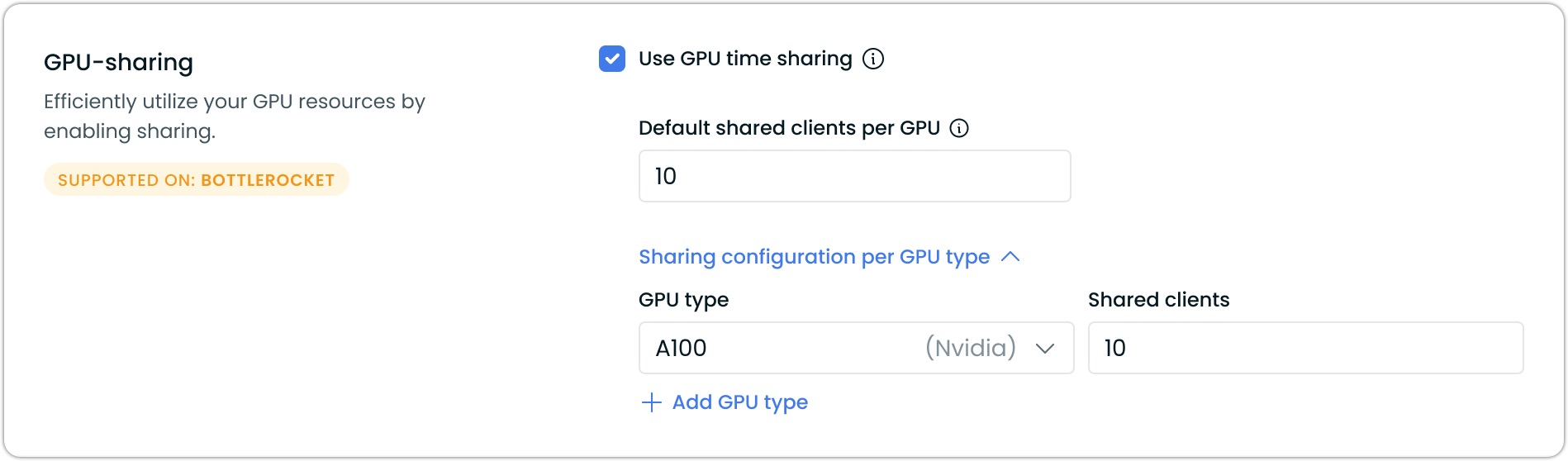
The maximum number of shared clients per physical GPU is 48.
API
Use the Node Templates API to configure GPU sharing programmatically. Include the gpu object in your node template configuration:
{
"gpu": {
"enableTimeSharing": true,
"defaultSharedClientsPerGpu": 10,
"sharingConfiguration": {
"nvidia-tesla-t4": {
"sharedClientsPerGpu": 8
},
"nvidia-tesla-a100": {
"sharedClientsPerGpu": 16
}
}
}
}Terraform
Configure GPU sharing using the Cast AI Terraform provider. Add the gpu block to your node template resource:
resource "castai_node_template" "example" {
# ... other configuration
gpu {
enable_time_sharing = true
default_shared_clients_per_gpu = 10
sharing_configuration = {
"nvidia-tesla-t4" = {
shared_clients_per_gpu = 8
}
"nvidia-tesla-a100" = {
shared_clients_per_gpu = 16
}
}
}
} Workload configuration
When using GPU time-slicing, pods continue to request GPUs using the standard nvidia.com/gpu resource. The key difference is targeting nodes with time-slicing enabled through node selectors and tolerations.
Basic time-slicing workload
spec:
nodeSelector:
scheduling.cast.ai/node-template: "gpu-sharing-template"
tolerations:
- key: "gpu-sharing-template"
value: "template-affinity"
operator: "Equal"
effect: "NoSchedule"
containers:
- image: my-image
name: gpu-test
resources:
requests:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
limits:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1Complete deployment example
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpu-timeslicing-workload
spec:
replicas: 10 # Can schedule 10 pods on a single GPU with 10x sharing
selector:
matchLabels:
app: gpu-timeslicing-workload
template:
metadata:
labels:
app: gpu-timeslicing-workload
spec:
nodeSelector:
scheduling.cast.ai/node-template: "gpu-sharing-template"
tolerations:
- key: "scheduling.cast.ai/node-template"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: gpu-workload
image: your-gpu-image
resources:
limits:
nvidia.com/gpu: 1Provider-specific considerations
AWS EKS
Amazon Linux 2023 (AL2023)
Amazon Linux 2023 (AL2023) AMIs support GPU time-slicing. When using AL2023 for GPU nodes with time-slicing enabled, Cast AI automatically configures the required NVIDIA device plugin settings.
Updating existing NVIDIA device plugin installations
If you have an existing NVIDIA device plugin Helm chart installation and want to use GPU time-slicing with AL2023, you must update your installation to prevent its pods from scheduling on nodes with GPU time-slicing enabled.
Add the following affinity configuration to your Helm values:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# On discrete-GPU based systems NFD adds the following label where 10de is the NVIDIA PCI vendor ID
- key: feature.node.kubernetes.io/pci-10de.present
operator: In
values:
- "true"
# Cast AI condition to exclude nodes with preinstalled NVIDIA device plugin
- key: "scheduling.cast.ai/preinstalled-nvidia-driver"
operator: DoesNotExist
- matchExpressions:
# On some Tegra-based systems NFD detects the CPU vendor ID as NVIDIA
- key: feature.node.kubernetes.io/cpu-model.vendor_id
operator: In
values:
- "NVIDIA"
# Cast AI condition to exclude nodes with preinstalled NVIDIA device plugin
- key: "scheduling.cast.ai/preinstalled-nvidia-driver"
operator: DoesNotExist
- matchExpressions:
# Allow GPU deployment to be forced by setting this label to "true"
- key: "nvidia.com/gpu.present"
operator: In
values:
- "true"
# Cast AI condition to exclude nodes with preinstalled NVIDIA device plugin
- key: "scheduling.cast.ai/preinstalled-nvidia-driver"
operator: DoesNotExistThis ensures that the NVIDIA device plugin pods run only on nodes without Cast AI's preinstalled device plugin, preventing conflicts with GPU time-slicing configurations.
Bottlerocket
Bottlerocket AMIs come with pre-installed NVIDIA drivers. Do not install additional NVIDIA device plugins on clusters where you plan to use Bottlerocket GPU nodes, as they may conflict with the pre-installed drivers and fail to start. If you do, you need to ensure these NVIDIA device plugin daemonsets do not run on those Bottlerocket nodes through tolerations.
When using Bottlerocket for GPU nodes, the OS handles driver management automatically. For more information, see Bottlerocket support for NVIDIA GPUs.
GPU sharing configuration: When using GPU time-slicing with Bottlerocket, Cast AI automatically configures the required NVIDIA device plugin settings. Do not manually add GPU time-slicing settings to your init script, as these will conflict with Cast AI's automatic configuration and prevent nodes from being created successfully.
See Node Configuration documentation for more details on AMI choice.
GCP GKE
GPU time-slicing is supported on GKE with the standard Cast AI GPU driver configuration. No additional provider-specific configuration is required beyond enabling time-slicing in your node template.
Combining time-slicing with MIG
Cast AI supports combining Multi-Instance GPU (MIG) with time-slicing for maximum resource utilization. This powerful combination allows multiple workloads to share each MIG partition through time-based scheduling.
For detailed information on configuring MIG with time-slicing, see the MIG with GPU time-slicing section in the MIG documentation.
Monitoring GPU utilization
Once GPU time-slicing is configured, monitor your GPU sharing efficiency with GPU utilization metrics. These metrics help you:
- Track GPU compute utilization across shared workloads
- Identify GPU memory waste
- Analyze cost efficiency of your sharing configuration
- Optimize sharing multipliers based on actual usage patterns