
Model autoscaling and hibernation
Cast AI's AI Enabler supports intelligent autoscaling for self-hosted model deployments. AI Enabler automatically manages capacity through model replica scaling, hibernation during idle periods, and seamless fallback to external SaaS providers when models are unavailable.
The autoscaling system provides three key capabilities that work together:
Replica-based scaling automatically adjusts model replicas based on traffic and GPU utilization metrics.
Active and user-defined hibernation scales model deployments to zero replicas during periods of inactivity to minimize GPU costs.
SaaS fallback integration routes requests to external model providers when self-hosted models are unavailable or scaling, ensuring continuous service availability.
This approach delivers significant reductions in GPU costs while maintaining performance and availability for variable AI workloads, development and production environments alike.
Accessing scaling configuration
For new deployments, navigate to AI Enabler > Model Deployments and click Deploy model. The scaling options are in the Automation and scaling section of the deployment drawer.
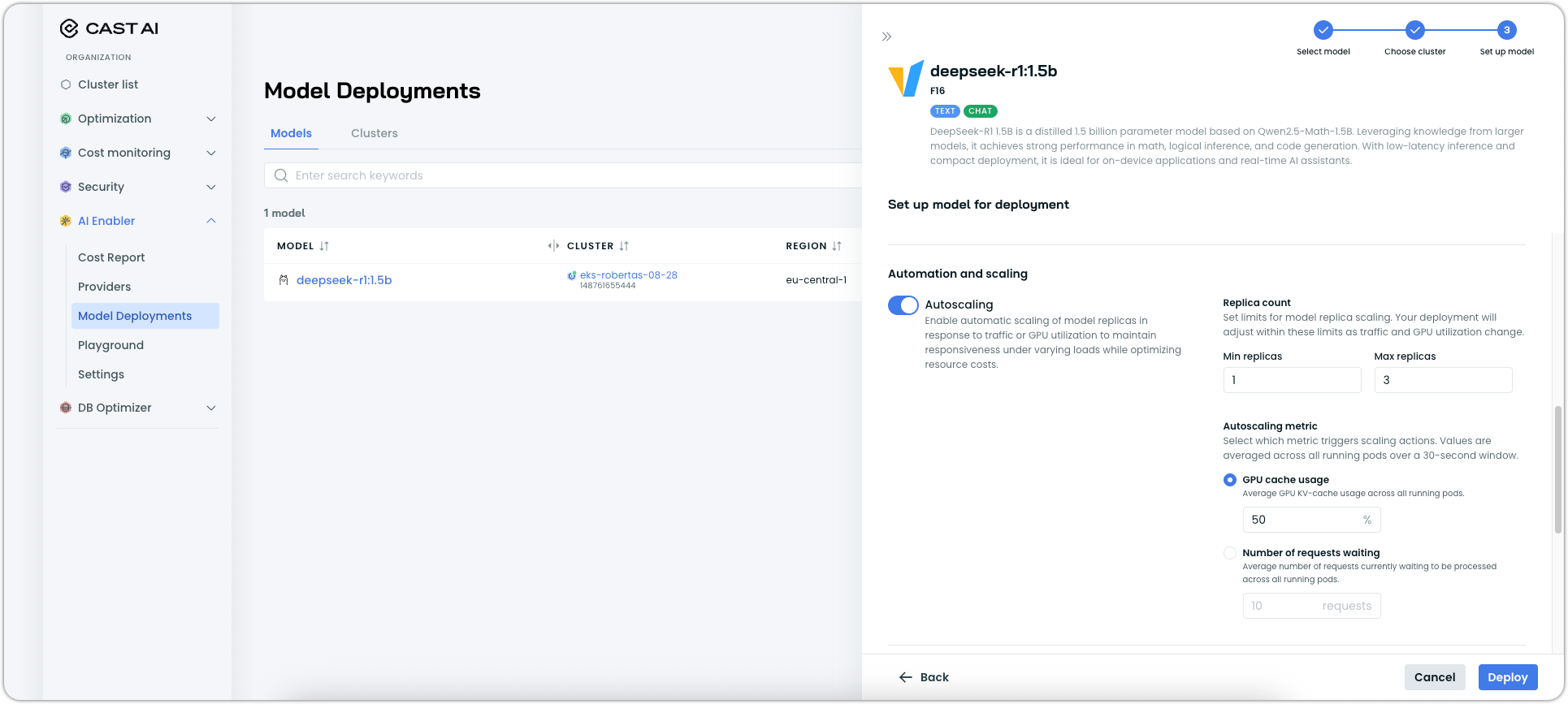
For existing models, select your deployment from the list and click the Settings tab. Changes take effect immediately, so you can adjust scaling behavior whenever you need.
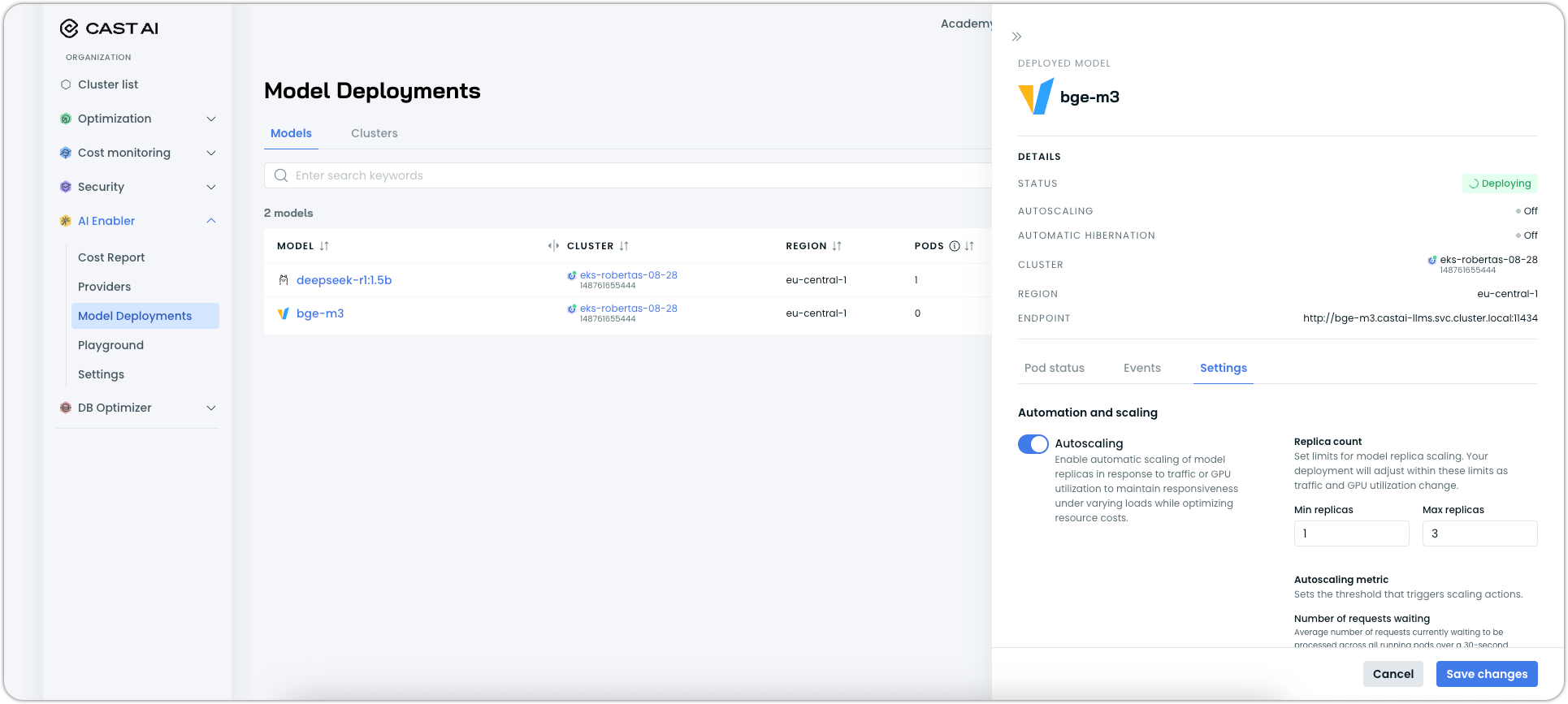
All scaling configurations are also available through the Cast AI API. See our API documentation to get started
Autoscaling configuration
NoteAutoscaling is currently available only for vLLM-based model deployments. Ollama model deployments support hibernation and fallback features but not replica-based autoscaling.
Enable autoscaling to automatically adjust the number of running replicas based on demand. Configure minimum and maximum replica counts to define scaling boundaries.
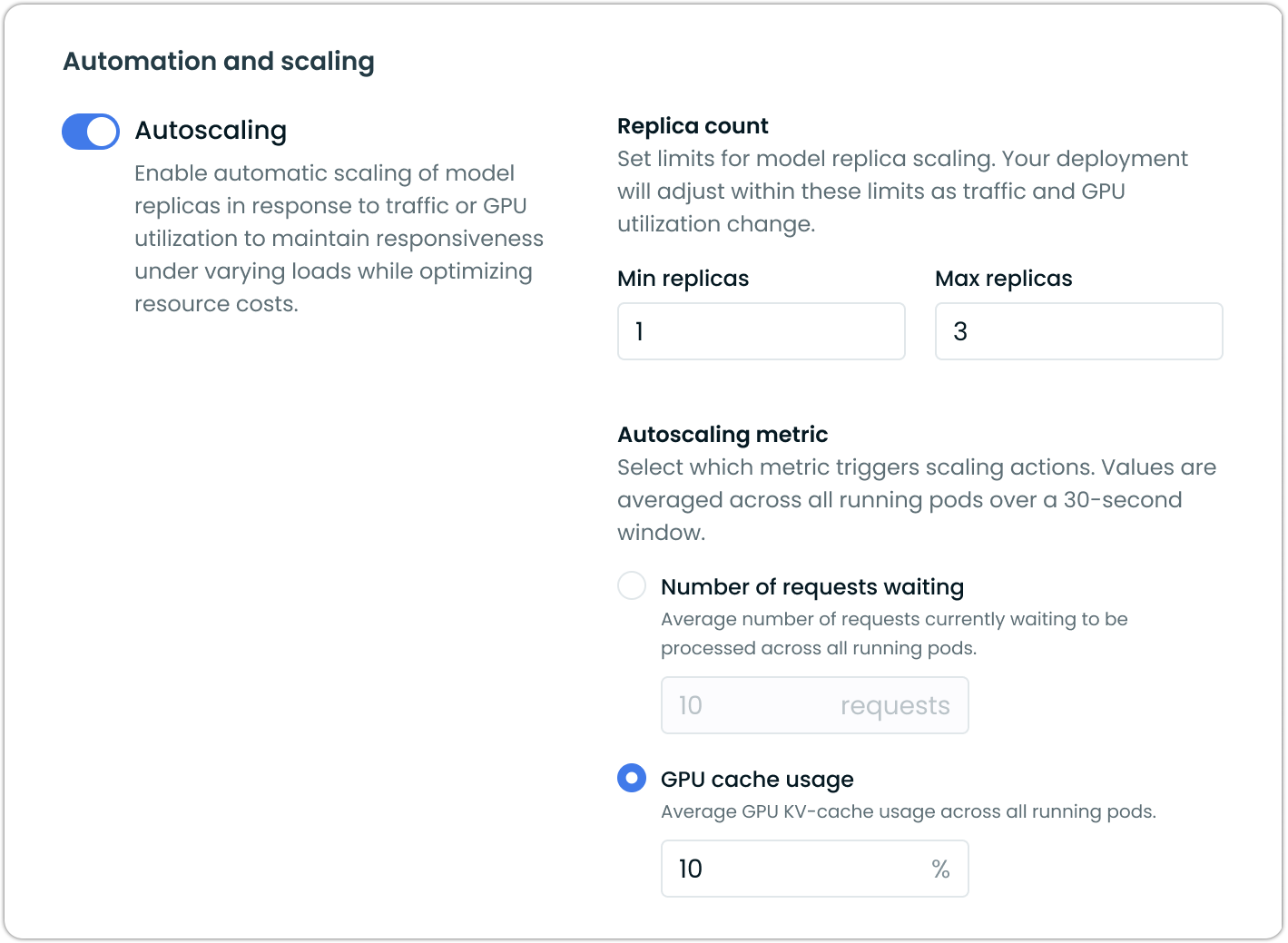
Set min replicas for guaranteed minimal availability in production workloads. The max replicas setting prevents runaway scaling and controls maximum resource consumption.
Scaling metrics
Choose the metric that triggers scaling decisions:
Number of requests waiting scales based on request queue depth. The system scales up when requests accumulate and scales down when the queue clears. This works well for variable request patterns and maintains consistent response times.
GPU cache usage scales based on memory utilization, useful for large models.
Automatic model hibernation
Model hibernation automatically scales deployments to zero replicas during inactivity, providing significant cost savings. When enabled, the system monitors request throughput and triggers hibernation when activity falls below configured thresholds.
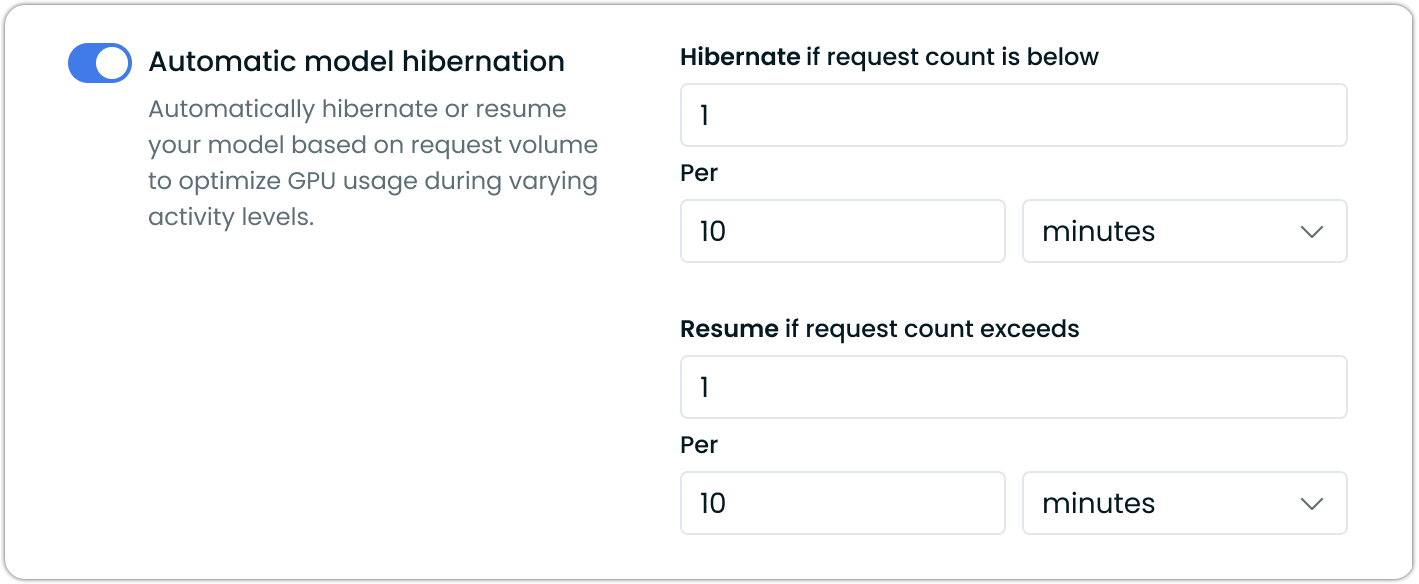
Configure hibernation thresholds based on your usage patterns. Shorter idle times maximize savings for development environments, while longer thresholds work better for production workloads with less predictable traffic and different SLA requirements.
When a hibernated model receives requests, the system automatically begins wake-up while routing traffic to your configured fallback model. This ensures hibernation doesn't impact service availability.
Resuming from hibernated state
When hibernation thresholds are met, models transition through clean shutdown and resource cleanup. During hibernation, models consume zero GPU resources while maintaining the ability to respond to new requests.
Wake-up begins immediately when hibernated models receive the number of requests you configured to trigger resumption. The system provisions GPU resources and initializes containers while routing current requests to fallback providers.
Wake-up times vary by model size and GPU availability:
- Smaller models: 2-3 minutes
- Larger models: 5-10 minutes
Traffic gradually transitions back to self-hosted deployments once fully operational.
Fallback model configuration
SaaS fallback models ensure service continuity when self-hosted models are hibernating, scaling, or otherwise unavailable. Configure external providers to handle requests during these periods.
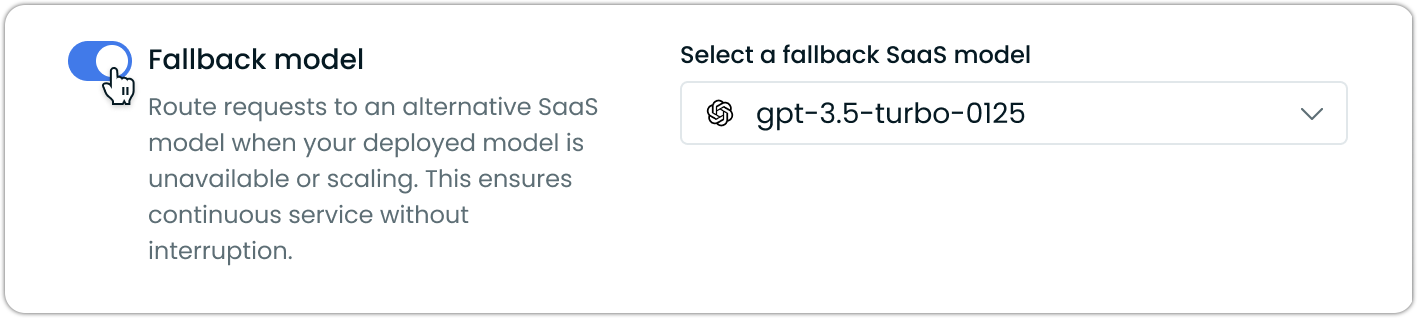
Fallbacks are restricted to external SaaS providers to prevent routing loops. Select providers with models similar to your self-hosted deployment for capability matching.
The fallback system activates automatically during hibernation, initial deployment, model errors, and maintenance periods.
NoteIf you have not yet registered a provider with AI Enabler, this feature will be unavailable until you do so.
Monitoring and observability
Each deployed model provides a detailed event history showing all autoscaling and hibernation activities. Navigate to a specific model and click the Events tab to view a chronological record of what happened.
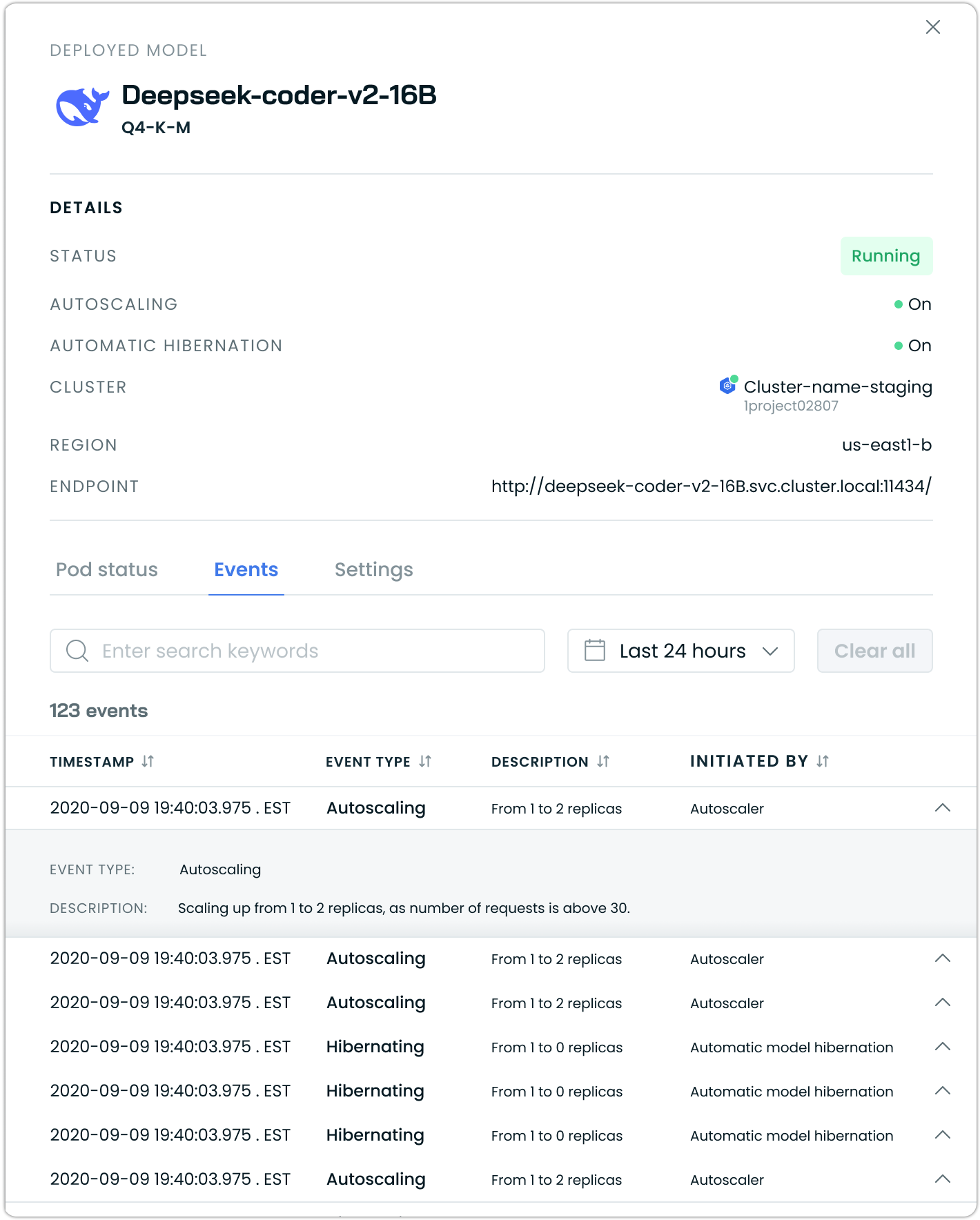
The events log shows the following:
Autoscaling events record when replicas are increased or decreased, including the trigger that caused the scaling action.
Hibernation events track when models scale to zero replicas due to inactivity and when they resume from the hibernated state. These events show both automatic hibernation triggers and any manual hibernation actions.
Each event record includes a precise timestamp, event type, description of what occurred, and which system component initiated the action. This granular visibility helps you understand model behavior and troubleshoot any scaling issues.