
Pod Pinner
Pod Pinner coordinates between the Cast AI Autoscaler and the Kubernetes scheduler to ensure the optimal pod placement in your Kubernetes cluster. Without Pod Pinner, the Kubernetes scheduler might place pods on unintended nodes, resulting in suboptimal resource utilization and higher costs.
Pod Pinner integrates Cast AI Autoscaler decisions into your cluster, allowing it to override the Kubernetes scheduler's decisions when necessary. For example, Pod Pinner assigns pending pods to a placeholder node during node rebalancing, ensuring they are directed to the correct node once it’s ready.
Installing Pod Pinner can directly enhance cluster savings. Pod Pinner is a Cast AI in-cluster component similar to the Cast AI agent, cluster controller, and others. There is no risk of downtime if Pod Pinner fails; the default Kubernetes scheduler will automatically take over pod placement decisions for rebalancing and autoscaling.
How Pod Pinner works
Pod Pinner works alongside the Cast AI Autoscaler to ensure pods are scheduled onto the specific nodes chosen by the Autoscaler. Here's how this process works:
-
When the Cast AI Autoscaler determines new nodes are needed, it sends scheduling instructions to Pod Pinner through a continuous data stream.
-
Pod Pinner creates a placeholder Node resource in Kubernetes using the API. This placeholder reserves the space for the incoming node before it physically joins the cluster, allowing Pod Pinner to coordinate scheduling decisions ahead of time.
-
For pods that need scheduling, Pod Pinner uses the Kubernetes
/pods/bindingAPI to explicitly assign them to specific nodes by settingspec.nodeName. This direct binding bypasses the default Kubernetes scheduling process. -
When the actual node joins the cluster, it automatically connects to its corresponding placeholder node, ensuring continuity in the scheduling process.
This coordination prevents scheduling conflicts between Cast AI and Kubernetes by ensuring pods land on their intended nodes rather than letting the Kubernetes scheduler place them based on its own scoring mechanisms. This is especially important because the Kubernetes scheduler isn't aware of nodes that are about to join the cluster and may make placement decisions that are different from what the Cast AI Autoscaler intended.
Limitations
Mutating admission webhooksPod Pinner is not compatible with mutating admission webhooks. It pins pods based on the original pod spec before any webhook mutations are applied, which can cause incorrect scheduling or resource oversubscription.
Scheduling constraint mutations
Pod Pinner is not compatible with mutating admission webhooks that modify scheduling-related pod specs. This includes Cast AI Pod Mutations, Cast AI Spot-webhook, and Kyverno.
The Autoscaler and Rebalancer make placement decisions based on the original pod spec. If a webhook adds nodeSelector, tolerations, or affinity rules after pinning occurs, those constraints are ignored because nodeName takes precedence over nodeSelector. For example, if a mutation adds scheduling.cast.ai/spot: "true" to a pod that was already pinned to an on-demand node, the pod will fail with a NodeAffinity mismatch.
If you use mutating webhooks that affect scheduling, disable Pod Pinner or define scheduling constraints directly in your workload specs. We are working on improving compatibility between Pod Pinner and Pod Mutations.
Runtime sidecar injection
Pod Pinner calculates node capacity based on the original pod spec at pin time. If a mutating webhook, such as Istio's or Linkerd's sidecar injector, adds containers after pinning occurs, their resource requests are not accounted for. During large-scale or burst scheduling events, this can cause nodes to become oversubscribed, resulting in pods failing with OutOfcpu or OutOfmemory status.
If your cluster uses runtime sidecar injection, disable Pod Pinner to avoid these scheduling failures.
Custom resources
Pod Pinner cannot pin pods that use custom resources (such as GPUs and ENIs). This is because custom resources like GPUs are initialized after a node joins the cluster. When a node first boots up, custom resources (like GPUs) are not immediately available - they require initialization by their respective drivers.
Installation and version upgrade
For newly onboarded clusters, the latest version of the Pod Pinner castware component castai-pod-pinner is installed automatically. Therefore, at the beginning:
- Review whether your cluster has the
castai-pod-pinnerdeployment in thecastai-agentnamespace available:
$ kubectl get deployments.apps -n castai-agent
NAME READY UP-TO-DATE AVAILABLE AGE
castai-agent 1/1 1 1 15m
castai-agent-cpvpa 1/1 1 1 15m
castai-cluster-controller 2/2 2 2 15m
castai-evictor 0/0 0 0 15m
castai-kvisor 1/1 1 1 15m
castai-pod-pinner 2/2 2 2 15mPrerequisites
Before installing Pod Pinner, ensure your cluster meets the following requirements:
- Kubernetes version 1.27 or later
Helm
Which upgrade method to useThe Helm commands on this page use the umbrella chart (
castai-helm/castai) by default. If you need to use a different method:
- castctl: To upgrade all Cast AI components at once without managing Helm flags:
This preserves your existing configuration. See the castctl documentation for installation and authentication instructions.castctl castware upgrade- Individual charts: If you installed each component as a separate Helm release (e.g., for ArgoCD or custom GitOps), replace the release name and chart reference with the component-specific ones (e.g.,
castai-workload-autoscalerandcastai-helm/castai-workload-autoscaler) and remove theautoscaler.castai-workload-autoscaler.value prefix.Not sure which method you used? Run
helm list -n castai-agent. A single release namedcastaimeans umbrella chart; separate releases likecastai-workload-autoscalermean individual charts.
Option 1: Cast AI-Managed (default)
By default, Cast AI manages Pod Pinner, including automatic upgrades.
- Check the currently installed Pod Pinner chart version. If it's >=
1.0.0, an upgrade is not needed.
You can check the version with the following command:
$ helm list -n castai-agent --filter castai-pod-pinner
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
castai-pod-pinner castai-agent 11 2024-09-26 11:40:00.245427517 +0000 UTC deployed castai-pod-pinner-1.0.2 v1.0.0- If the version is <
1.0.0run the following commands to install or upgrade Pod Pinner to the latest version.
helm repo add castai-helm https://castai.github.io/helm-charts
helm repo update
helm upgrade castai castai-helm/castai -n castai-agent --reset-then-reuse-valuesAfter installation or upgrade to version >= 1.0.0Pod Pinner will automatically be scaled to 2 replicas and will be managed by Cast AI, as indicated by the charts.cast.ai/managed=true label applied to the pods of the castai-pod-pinner deployment. All the following Pod Pinner versions will be updated automatically.
Option 2: Self-Managed
To control the Pod Pinner version yourself:
Configuration-only changesThis command upgrades all components in the umbrella chart, not just Pod Pinner. To change configuration without upgrading component versions, pin the chart to your current version by adding
--version <your-current-chart-version>to the command. Runhelm list -n castai-agentto check your current version.
helm upgrade castai castai-helm/castai -n castai-agent \
--reset-then-reuse-values \
--set autoscaler.castai-pod-pinner.managedByCASTAI=falseThis prevents Cast AI from automatically managing and upgrading Pod Pinner.
Upgrading using Pod Pinner when in Self-Managed mode:
If the version is < 1.0.0 run the following commands to upgrade Pod Pinner to the latest version.
helm repo add castai-helm https://castai.github.io/helm-charts
helm repo update
helm upgrade castai castai-helm/castai -n castai-agent \
--reset-then-reuse-values \
--set autoscaler.castai-pod-pinner.managedByCASTAI=falseRe-running Onboarding Script
You can also install Pod Pinner by re-running the phase 2 onboarding script. For more information, see the cluster onboarding documentation.
Terraform Users
For Terraform users, you can manage Pod Pinner installation and configuration through your Terraform scripts. This allows for version control and infrastructure-as-code management of Pod Pinner settings.
Enabling/Disabling Pod Pinner
Pod Pinner is enabled by default but can be disabled in the Cast AI console.
If you disable Pod Pinner this way, the deployment will be scaled down to 0 replicas and not auto-upgraded by Cast AI.
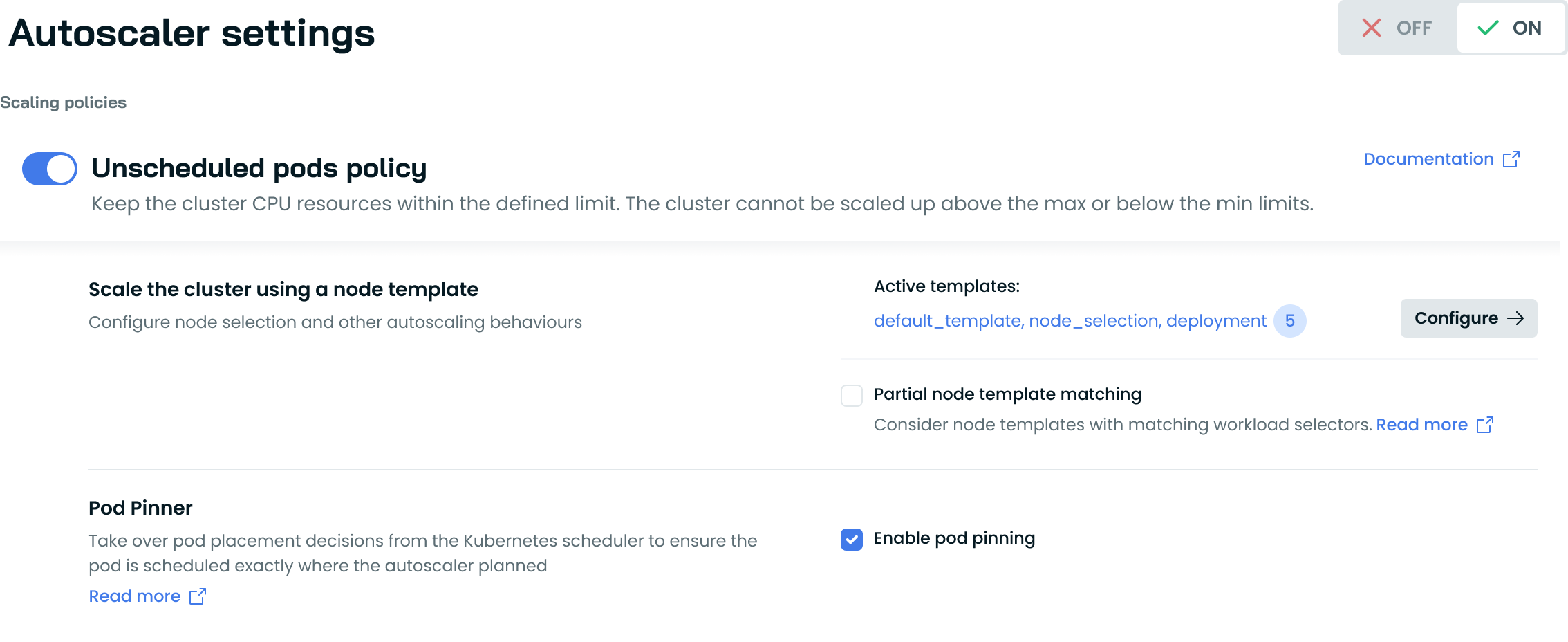
Autoscaler Settings UI
To enable/disable Pod Pinner:
- Navigate to Autoscaler settings in the Cast AI console.
- You'll find the Pod Pinner option under the "Unscheduled pods policy" section.
- Check/uncheck the "Enable pod pinning" box to activate/deactivate the Pod Pinner. Disabling Pod Pinner will scale down the deployment to 0 replicas and turn off auto-upgrades.
NoteWhen Pod Pinner is disabled through the console and the
charts.cast.ai/managed=truelabel is present, CAST AI will scale down the deployment to 0 replicas no matter what. To manually control Pod Pinner while keeping it active, use the self-managed installation option mentioned above.
Ensuring stability
It is suggested that you keep the Pod Pinner pod as stable as possible, especially during rebalancing. You can do so by applying the same approach you are using for castai-agent.
For instance, you can add the autoscaling.cast.ai/removal-disabled: "true" label/annotation to the pod. If the Pod Pinner pod restarts during rebalancing, the pods won't get pinned to the nodes as expected by the Rebalancer. It may result in suboptimal pod placement as the Kubernetes cluster scheduler will schedule the pods.
NoteYou can scale down the
castai-pod-pinnerdeployment anytime. This will result in normal behavior and will not impact the cluster negatively other than the Kubernetes scheduler taking over pod scheduling.
Logs
You can access logs in the Pod Pinner pod to see what decisions are being made. Here is a list of the most important log entries:
| Example | Meaning |
|---|---|
node placeholder created | A node placeholder has been created. The real node will use this placeholder when it joins the cluster. |
pod pinned | A pod has been successfully bound to a node. Such logs always appear after the node placeholder is created. |
node placeholder not found | This log appears when Pod Pinner tries to bind a pod to a non-existing node. This may occur if Pod Pinner fails to create the node placeholder. |
pinning pod | This log occurs when the Pod Pinner's webhook intercepts a pod creation and binds it to a node. This happens during rebalancing. |
node placeholder deleted | A node placeholder has been deleted. This happens when a node fails to be created in the cloud, and Pod Pinner must clean up the placeholder that was created. |
failed streaming pod pinning actions, restarting... | The connection between the Pod Pinner pod and Cast AI has been reset. This is expected to happen occasionally and will not negatively impact your cluster. |
http: TLS handshake error from 10.0.1.135:48024: EOF | This log appears as part of the certificate rotation performed by the webhook. This is a non-issue log and will not negatively impact the cluster. |
Troubleshooting
Failed pod status reason: OutOf{resource}
OutOf{resource}OutOfcpu, OutOfmemory, OutOf{resource} pod statuses happen when the scheduler schedules a pod on a node, but the kubelet rejects it due to a lack of some sort of resource. These are Failed pods that CAST AI and the Kubernetes control-plane know how to ignore.
This happens when many pods are upscaled at the same time. The scheduler has various optimizations to deal with large bursts of pods, so it makes scheduling decisions in parallel. Sometimes, those decisions conflict, resulting in pods scheduled on nodes where they don't fit. This happens especially in GKE. If you see this status, don't be afraid. The control-plane will eventually clean those pods up after a few days.
Pods might get this status when the Kubernetes scheduler takes over scheduling decisions due to a blip in Pod Pinner's availability. However, this does not negatively impact the cluster as Kubernetes recreates the pods.
Failed pinning reason: pod requires unsupported resources
Pod Pinner >=1.6.3 checks resources requested by pods. If you see this error, it means the pod requests (or limits) some resource that is not yet available on the node. The Kubernetes scheduler will still schedule these pods when there is a suitable node available. This is common for delayed initialization resources like GPUs. If scheduled too early on a node, such pods often crash-loop until these resources become available.
If crash-looping is desired (as opposed to not getting pinned), you can annotate the pod with autoscaling.cast.ai/pin-ignore-missing-resources=true to bypass this validation. This annotation is supported by Pod Pinner >=1.7.0.