
Scheduled rebalancing
How it works
Scheduled rebalancing enables full or partial rebalancing process on a user-defined schedule, scope, and trigger to automate various use cases. Most commonly scheduled rebalancing is used in the following scenarios:
- Identify the most expensive Spot Instances and replace them with cheaper alternatives
- Perform full rebalancing of clusters on weekends
- Roll old nodes
- Periodically target and replace nodes with specific labels
A rebalancing schedule is an organization-wide object that can be assigned to one or multiple clusters. Once triggered, it creates a rebalancing plan scoped by parameters provided in the node selection preferences, while the problematic workloads are excluded automatically.
To set up scheduled rebalancing, navigate to the organizational-level Optimization menu or access the Rebalancer view within the cluster.
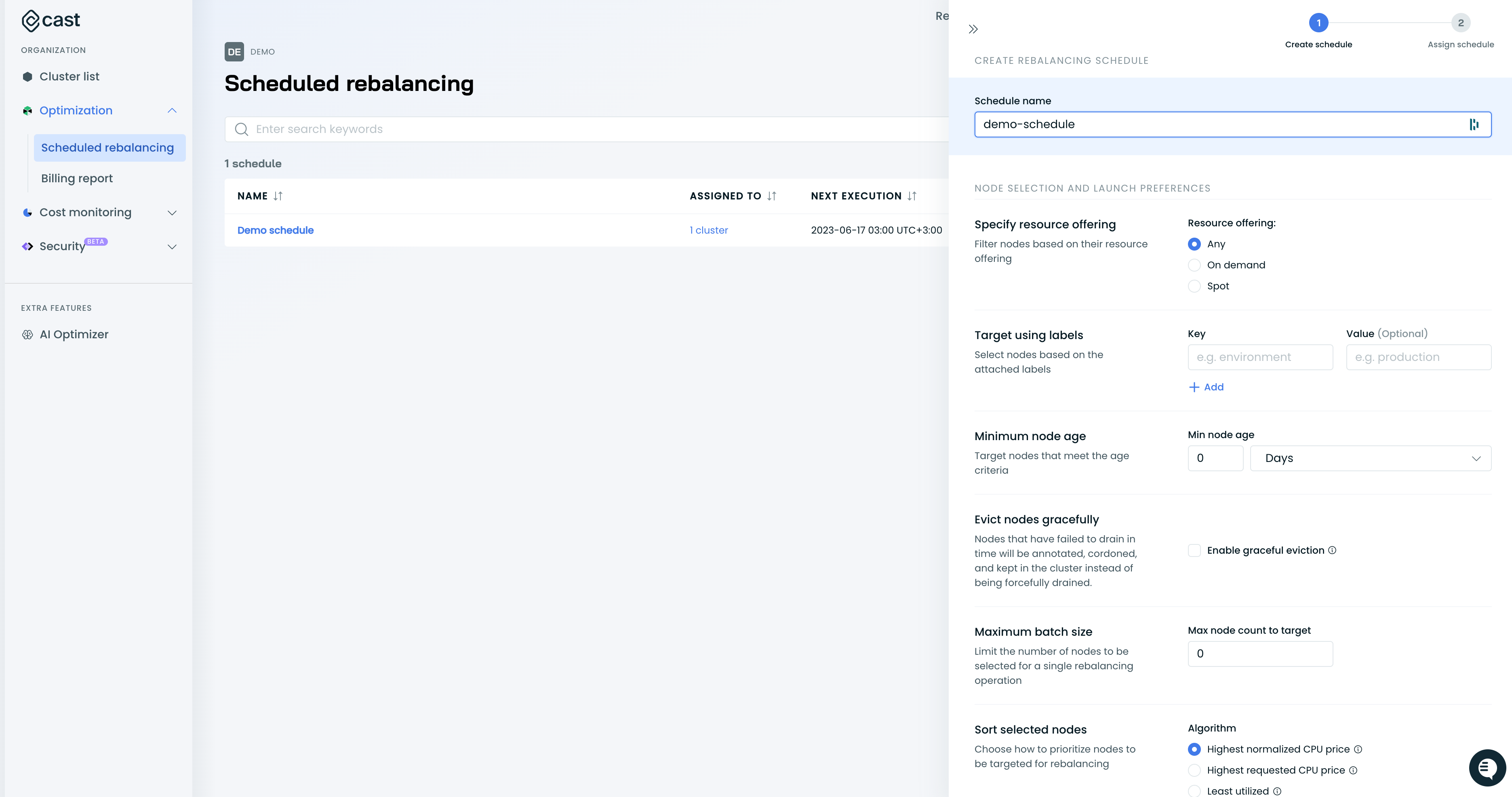
Setup
There are two main components in the scheduled rebalancing functionality
- A rebalancing job is a job that triggers a rebalancing schedule on an associated cluster.
- Rebalancing schedule - an organization-wide rebalancing schedule that can be used on multiple rebalancing jobs.
The Rebalancing schedule consists of four parts:
- The schedule describes when to run the scheduling (periodically, within the maintenance window, etc.)
- Node selection preferences contain rules for picking specific nodes, how many to target, and similar rules that mimic decision-making when manually rebalancing a cluster.
- Trigger requirements are decision rules for executing the rebalancing plan. They include rules like the “Savings threshold,” determining whether the generated plan should be executed.
- Execution safeguard: Cast AI stops rebalancing before draining the original nodes if it finds that the user-specified minimum level of savings can't be achieved. This additional protection layer is required as planned nodes might temporarily be unavailable in the cloud provider's inventory during the rebalancing.
Settings
The following settings can be adjusted when setting up the scheduled rebalancing:
| Setting | Description |
|---|---|
| Specify resource offering | Spot, On-Demand, or Any |
| Target using labels | Key-value pairs are provided as For |
| Minimum node age | Amount of time since the node creation before the node can be considered for rebalancing. 0 - means a node of any age can be considered. |
| Evict nodes gracefully | Defines whether nodes that fail to drain within a configurable timeout (default: 20 minutes, maximum: 180 minutes) will be kept with a When disabled (default): Nodes are forcefully drained after the timeout, which may override Pod Disruption Budgets (PDBs) to complete the rebalancing operation. When enabled: Nodes are annotated, cordoned, and kept in the cluster. PDBs are strictly respected. By default, Cast AI automatically uncordons these Nodes after 3 hours. To disable automatic uncordoning, set |
| Drain timeout | Maximum time to wait for each node to drain during rebalancing. Default: 20 minutes. Maximum: 180 minutes (10800 seconds). Default: 20 minutes. Configure this in Advanced settings when setting up a rebalancing schedule. After this timeout expires, the node is either forcefully drained (default) or annotated and kept in the cluster (when Evict nodes gracefully is enabled). |
| Maximum batch size | Maximum number of nodes that will be selected for rebalancing. '0' indicates that all nodes in the cluster can be selected |
| Sort selected nodes | The algorithm used to sort selected nodes:
|
| Aggressive mode | Rebalance problematic pods, those without a controller, job pods, and pods with the removal-disabled annotation |
| Savings threshold |
|
| Execution times | Execution time can be adjusted by providing a timezone and a crontab expression |
Node targeting
When configuring node targeting for scheduled rebalancing, you can choose between two methods: Labels or Fields. This selection determines how you'll identify nodes for the rebalancing operation.
Using labels
To configure label-based targeting:
- Select "Labels" under "Target using"
- Configure your label-matching rules:
- Key: Enter the Kubernetes label key (e.g.,
scheduling.cast.ai) - Operator: Choose from:
Exists: Match nodes where the label existsDoesNotExist: Match nodes where the label is absentIn: Match nodes where the label value matches one in a listNotIn: Match nodes where the label value doesn't match any in a list
- Value: Enter the label value to match (required for
InandNotInoperators)
- Key: Enter the Kubernetes label key (e.g.,
- Add additional label-matching expressions using the "+ Add" button if needed
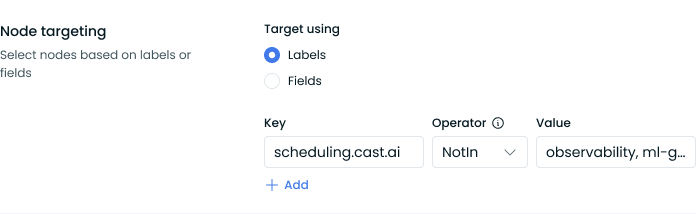
Multiple node label matching expressions are combined using the AND logic – nodes must match all specified conditions to be selected for rebalancing.
For example, if you configure:
field1Inspot_tmpfield2Inwrestle
Only nodes with both field1=spot_tmp AND field2=wrestle will be selected.

Technical details
Under the hood, the Console UI creates a single nodeSelectorTerm with multiple matchExpressions. According to Kubernetes selector logic:
- All expressions within a
nodeSelectorTermare ANDed together - Multiple
nodeSelectorTermsare ORed together (API-only, see below)
Using fields
Field-based targeting provides an alternative method when label-based selection isn't sufficient. When selecting Fields, you can target nodes based on their Kubernetes field values rather than labels.
Example
An example use case for field targeting is rebalancing a specific node by name. This is useful when you've identified a particular node that needs replacement. For example, a node running an outdated configuration or one flagged for maintenance.
- Select Fields under Target using
- Configure the field selector:
- Key:
metadata.name - Operator:
= - Value: the name of the node to target (e.g.,
ip-10-0-1-42.ec2.internal)
- Key:
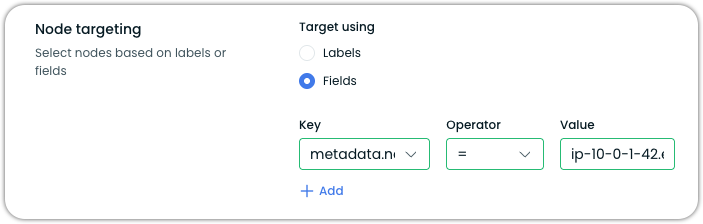
This configuration targets a single node by its Kubernetes node name, allowing you to schedule its replacement without affecting other nodes in the cluster.
For more information on using field selectors, refer to Kubernetes documentation.
Known limitation: cordoned-node targeting may cause schedules to be skippedTargeting cordoned Nodes with
spec.unschedulable=truecan cause the scheduled rebalancing operation to be skipped entirely rather than rebalancing the targeted Nodes. Drain-failed Nodes left cordoned after a graceful eviction timeout are automatically uncordoned after 3 hours by default, but will still be skipped by scheduled rebalancing while cordoned.For recovery options, see Handling failed Node drains.
Using OR conditions for node labels in scheduled rebalancing
OR conditions for node labels in scheduled rebalancingThe console UI supports AND logic only. To use OR conditions between node label values, use the Cast AI API:
- Use the Cast AI API endpoint for creating rebalancing schedules:
POST /v1/rebalancing-schedules - Specify multiple
nodeSelectorTermsin your request to createORlogic between terms - Within each term, use
matchExpressionswith theInoperator to target multiple values for the same label key
Example: OR logic for multiple values of the same label
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "nodetemplate",
"operator": "In",
"values": ["customerA", "customerB", "customerC"]
}
]
}
]This configuration targets nodes with the nodetemplate label matching any of the specified values (customerA OR customerB OR customerC).
Example: OR logic between different label conditions
To create OR logic between multiple distinct label conditions, add multiple objects to the nodeSelectorTerms array:
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "nodetemplate1",
"operator": "In",
"values": ["customerA"]
}
]
},
{
"matchExpressions": [
{
"key": "nodetemplate2",
"operator": "In",
"values": ["customberB"]
}
]
}
]This selects nodes with either nodetemplate=customerA OR nodetemplate2=customerB.
WarningWhen using multiple
nodeSelectorTermsvia the API, the UI may not display all values correctly. The UI is limited to displaying a single term with AND logic only.
For complete details, refer to the Cast AI API reference documentation for creating rebalancing schedules.
Sort selected nodes
When configuring scheduled rebalancing, the Sort selected nodes setting determines how nodes are prioritized for rebalancing. Each algorithm serves different optimization goals.
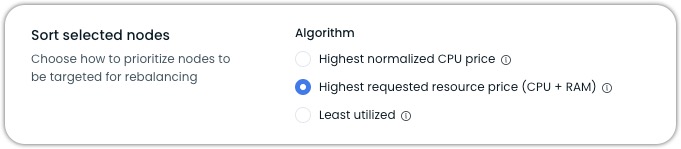
Highest normalized CPU price
- Sorts nodes by dividing the node's total cost by its CPU count, which prioritizes removing expensive nodes based on their provisioned (total available) CPUs.
- Best for: Spot Instance clusters when you want to remove the most expensive instances or a partial rebalancing where you just want to remove the most expensive nodes
NoteIt doesn't consider actual resource utilization, only the raw cost per CPU.
Highest requested resource price (CPU + RAM)
- Sorts nodes by calculating the cost of actually requested (used) resources, considering both CPU and memory in a 1:7 ratio. For example, a $5/hour node using 1 CPU and 7GB RAM has a resource price of $2.50/unit, while the same node using 4 CPU and 28GB RAM has a resource price of $0.63/unit.
- Best for: Most scenarios, especially mixed workloads with varying memory and CPU needs, as it provides the best overall cost optimization by targeting nodes with the highest wasted resource cost.
Least utilized
- Sorts nodes purely based on CPU utilization percentage, regardless of node size or cost. For example, a 2-core node with 1 core used (50% utilized) would be prioritized over a 64-core node with 20 cores used (31% utilized), even though the larger node has more wasted resources
- Best for: Specific use cases where you want to consolidate many small, underutilized nodes, regardless of cost impact
NoteIt may miss opportunities to remove larger, more expensive nodes that have higher percentage utilization but more wasted resources as a sum.
For most cost optimization scenarios, the Highest requested resource price (CPU + RAM) sorting algorithm provides the best balance for removing expensive and underutilized nodes.
Aggressive mode configuration
When using aggressive mode in scheduled rebalancing, you can configure additional options to control how problematic workloads are handled.
Local Persistent Volumes configuration
By default, even in aggressive mode, nodes with Local Persistent Volumes (LPVs) are marked as "Not ready" for rebalancing. This is because LPVs are tied to specific nodes through node affinity rules (typically using the kubernetes.io/hostname topology label) and cannot be migrated between nodes.
You can configure aggressive mode to ignore these local volume constraints.
Configuration via API
When creating or updating a rebalancing schedule through the API, include the aggressiveModeConfig in your request:
{
"launchConfiguration": {
"rebalancingOptions": {
"aggressiveMode": true,
"aggressiveModeConfig": {
"ignoreLocalPersistentVolumes": true
}
}
}
}This configuration:
- Requires
aggressiveModeto be set totrue - Allows rebalancing to include nodes with Local Persistent Volumes
WarningSetting
ignoreLocalPersistentVolumestotruewill allow rebalancing to evict pods with local storage. This will result in data loss for applications using Local Persistent Volumes. Only use this option when data persistence is not critical.
For complete API documentation and the latest schema, refer to our Scheduled Rebalancing API Reference.
Configuration via Terraform
In Terraform, use the aggressive_mode_config block to configure Local Persistent Volumes handling:
resource "castai_rebalancing_schedule" "example" {
# Required configuration elements...
launch_configuration {
# Enable aggressive mode
aggressive_mode = true
# Configure aggressive mode options
aggressive_mode_config {
ignore_local_persistent_volumes = true
}
# Other launch configuration settings...
}
}
WarningSetting
ignore_local_persistent_volumestotruewill allow rebalancing to evict pods with local storage. This will result in data loss for applications using Local Persistent Volumes. Only use this option when data persistence is not critical.
For more information about Terraform configuration options, refer to the Cast AI Terraform Provider documentation.
Configuration examples
Using the API
Create a rebalancing schedule using the API:
{
"schedule": {
"cron": "*/30 * * * *"
},
"launchConfiguration": {
"selector": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "scheduling.cast.ai/spot",
"operator": "Exists"
}
]
}
]
},
"rebalancingOptions": {
"executionConditions": {
"enabled": true,
"achievedSavingsPercentage": 10
},
"minNodes": 2,
"keepDrainTimeoutNodes": false
},
"targetNodeSelectionAlgorithm": "TargetNodeSelectionAlgorithmNormalizedPrice",
"numTargetedNodes": 3,
"nodeTtlSeconds": 300
},
"triggerConditions": {
"savingsPercentage": 20
},
"name": "rebalance spots at every 30th minute"
}Using Terraform
Define a rebalancing schedule using the Terraform provider:
resource "castai_rebalancing_schedule" "spots" {
name = "rebalance spots at every 30th minute"
schedule {
cron = "*/30 * * * *"
}
trigger_conditions {
savings_percentage = 20
}
launch_configuration {
# only consider instances older than 5 minutes
node_ttl_seconds = 300
num_targeted_nodes = 3
rebalancing_min_nodes = 2
keep_drain_timeout_nodes = false
selector = jsonencode({
nodeSelectorTerms = [{
matchExpressions = [
{
key = "scheduling.cast.ai/spot"
operator = "Exists"
}
]
}]
})
execution_conditions {
enabled = true
achieved_savings_percentage = 10
}
}
}