
Node templates, node configuration, and labels
Can I use multiple custom labels for a node template?
Yes, CAST AI allows that
Does creating a template and applying it to default just apply it to new nodes or to the cluster immediately?
Using the node template and applying to default will apply only to new nodes, including those created by CAST AI. Workloads are matched to nodes depending on the node's taints, the pod's tolerations, node affinity, or topology spread constraints.
You can find more detailed information on Node templates here.
Why aren't global options for min/max CPU/MEM aren't working for custom node templates?
Node template offers its min/max, while the settings on the standard autoscaler only apply to the "default".
We want to create node configuration and node templates in the production cluster - can we do that when autoscaler is disabled?
Yes, you can create node templates and node configurations. However, if you create workloads with node template selectors, CAST AI will add new nodes unless the global kill switch is turned off.
It depends on how you manage your autoscaler policies. If you manage them through the UI, the kill switch isn't exposed, so there is no way to disable CAST AI entirely while the agent is running in the cluster.
If you manage autoscaler policies through Terraform, it is possible to turn it off entirely. If you are using Terraform, you're safe as long as the "enabled" flag in the autoscaler policy JSON is set to false.
Also, the unschedulable pods policy switch should control all new node additions. So, if the unschedulable pods policy is toggled off, the global switch isn't required.
To block the creation of an EC2 instance by the default node configuration, we apply an SCP that will deny instance creation with a specific tag. We see that CAST AI sent 4 requests per minute to create the instance and failed (Client.UnauthorizedOperation ). Can this cause any issues on the CAST AI side (limits or throttling)?
This setup should not cause any issues. It will cause alerts, but these can be silenced upon request.
In your documentation, it states that CAST AI supports nodeAffinity. Does that include selecting the right nodeTemplate by affinities?
nodeAffinity. Does that include selecting the right nodeTemplate by affinities?Let's explain this on the basis of this example scenario:
The pod doesn't have a nodeSelector; it has a nodeAffinity. Will CAST AI's autoscaler select a nodeTemplate with a given label, or will it select the default template since the pod doesn’t have any nodeSelectors?
This scenario will work. For example, in this case, CAST AI will schedule a pod on the node created using the node template, which has the given labels:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: product-line
operator: In
values:
- ugcWe have a scenario where a node template has two labels, and the pod uses this pair in nodeSelector and nodeAffinity. Can this work?
Mixing node selector and affinity is possible. You can accomplish this using the mechanism mentioned on this page.
If I create a node template without taint nodes, will the spot fallback option still work?
You should still be able to use spot fallback. You likely want to set it and remove the taint after setting the fallback configuration.
need four different node configurations for the same cluster. But I see the autoscaler configuration only allows for one node configuration. Is there a way to manage several node configurations for the same cluster or should I break the cluster into four different clusters?
Node templates act as virtual autoscalers separate from the default autoscaler. If you apply the template node selectors and/or tolerations to your workloads, CAST AI will add nodes according to the node template settings rather than the autoscaler settings.
This would allow you to define the node configurations as needed.
We are seeing a version number on the node templates, is this the way to see the configurations of all the previous versions?
CAST AI doesn't offer that yet but will do so in the future.
I have installed a node-local DNS. To have pods use the node-local DNS, the kubelet running on each node needs to be configured. How can I configure this on CAST AI?
You can accomplish this via the nodeConfiguration API using the UI, find more information here.
The node configuration Config is located in the EKS Object, you can learn more about it here.
Is there a way I can mandate that only 500 EBS volumes get attached to each node?
You can use the node config to set min disk: /v1/kubernetes/clusters/{clusterId}/node-configurations
"minDiskSize": 0,How can I select subnets in the node config page? I can see that only public subnets are listed in the subnet list - there are private subnets or an option to add custom subnets.
You can use subnets by pointing to NAT/Internet Gateways. CAST AI can’t create nodes without this clause as nodes won’t have internet access.
The platform validates this before allowing you to use subnets so that nodes need to be able to get everything they need and join the cluster. You can learn more here.
Is it possible to specify the Kubernetes version of nodes in CAST AI?
CAST AI doesn't support changing Kubernetes versions.
The only workaround available is to use a compatible image with the old K8s version that works with your control plane version and then add it to the node configuration.
You can also achieve this by adding or updating the node configuration with a specific image version. You can find more details in the documentation on this page.
Note the supported versions and the specific versions acceptable to create new node pools for AKS (learn more).
New instances are created without IMDSv2, why is that so?
Forcing IMDSv2 on existing clusters could be a breaking change, we made it a flag on the NodeConfiguration. You can adjust it through the API or TF: API reference
I would like to set the default EBS size of 50 GB instead of 100 GB, how can I do it?
You can use the NodeConfiguration API to update minDiskSize to set it to 50 GB: Swagger UI Updates configuration of a specific cluster.
In nodeTemplate, I set min CPU constraint to 4, then the node created got 30 GB memory and usage is just 37%?
For a spot node, CAST AI will try to find the cheapest CPU/hour machines. If a machine that has 4 CPUs and 16GB has the same spot price as 4 CPUs and 32 GB, it will pick the latter.
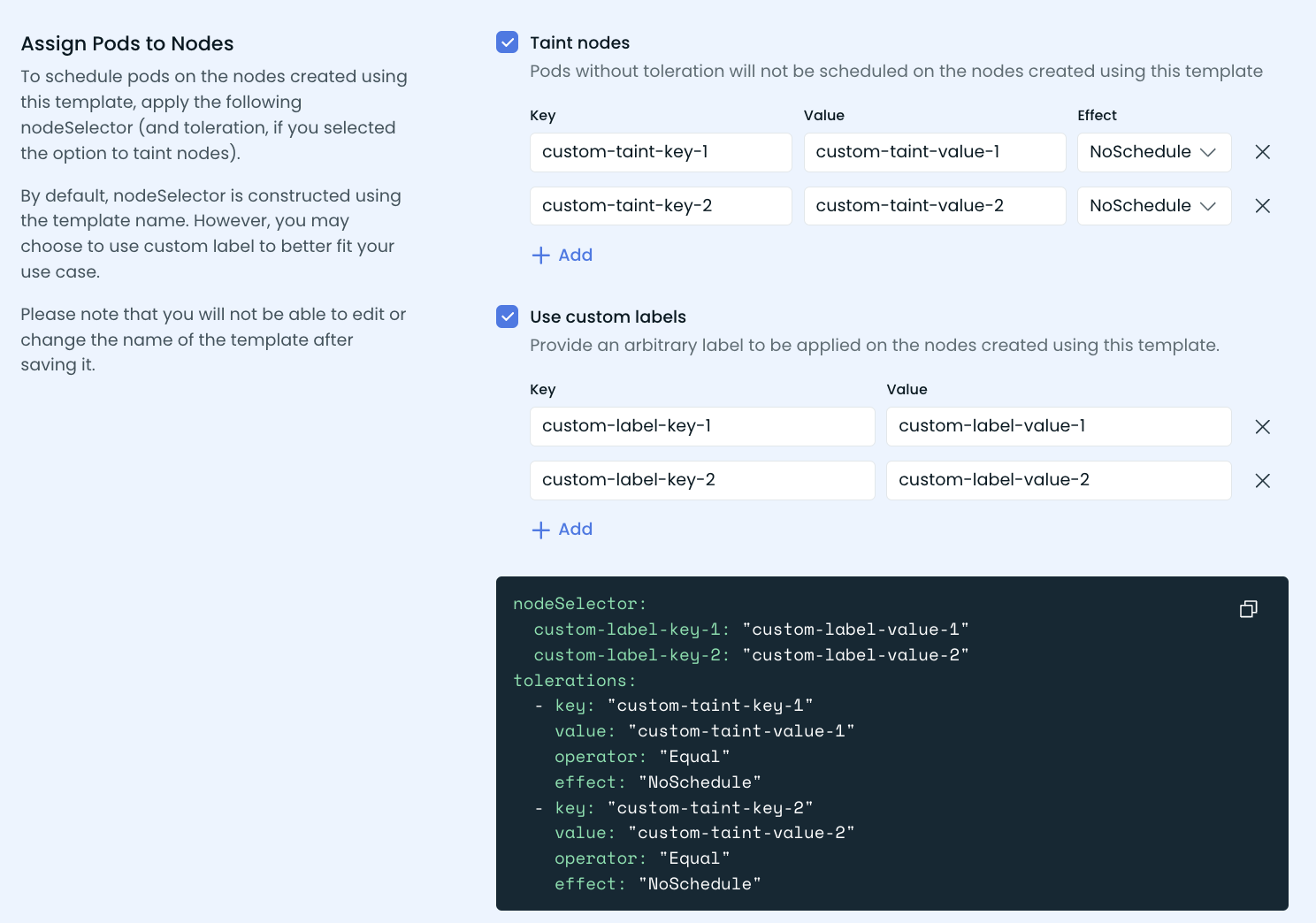
Does CAST AI support custom multi-labels and multi-taints for node templates?
CAST AI does support custom-label multi-labels and custom multi-taints in node templates. Configurable via UI, TF, and API: API reference
I'm facing issues with pods not coming up because of volume limit reached for the node in the eks-stage-v3 cluster. If I configure volume-attach-limit, then it is respected by other controllers. Can you confirm if this parameter is also respected by CAST AI?
Setting the volume attachment limit is not supported at the moment.
Is there any affinity to assign pods to latest created node?
Currently, CAST AI doesn't support any affinity that will assign pods to the latest-created node.
Do we have a way of supporting workloads that don't use workload identity in Google Cloud?
Creating nodes with workload identities allows apps/pods to access Google Cloud services without service principals, which is the recommended way from a security standpoint.
This has not been validated, but we believe pods that use other means of authorization should still be able to do so on nodes that have workload identity enabled.
Their use case might be different as there are security limitations enabled when using workload identity. Node’s metadata endpoint and host network are not accessible in the same manner as without workload identity.
We don't have node config support out of the box for this. To change the behavior, you need to choose one or another config by reconfiguring the cast-pool.
Does the node label provisioner.cast.ai/node-id=(ClusterID) mean this node was created by CAST AI?
provisioner.cast.ai/node-id=(ClusterID) mean this node was created by CAST AI?This is just an identifier CAST AI adds to all nodes so we can track them.
The label provisioner.cast.ai/managed-by=cast.aiIdentify the nodes created by CAST AI.
Why is custom_taints marked to be deleted, if should_taint is set to true, so the default taint should be applied and what will happen if I actually run this?
custom_taints marked to be deleted, if should_taint is set to true, so the default taint should be applied and what will happen if I actually run this?According to your documentation of node template inside TF provider, whenever custom_taints are not provided nodes should be tainted with the default node template taint. That seems like the correct behavior, however, when doing Terraform apply the following configuration of a node template:
graviton = {
node_configuration_name = "registry-pull-qps-10"
should_taint = true
constraints = {
fallback_restore_rate_seconds = 1800
spot = false
use_spot_fallbacks = true
architectures = ["arm64"]
min_cpu = 16
max_cpu = 48
min_memory = 32768
max_memory = 393216
}
}Terraform wants to perform the following changes:
# module.eks.module.castai[0].module.castai-eks-cluster.castai_node_template.this["graviton"] will be updated in-place
~ resource "castai_node_template" "this" {
id = "graviton"
name = "graviton"
# (8 unchanged attributes hidden)
~ constraints {
- spot_diversity_price_increase_limit_percent = 20 -> null
- spot_interruption_predictions_type = "aws-rebalance-recommendations" -> null
# (14 unchanged attributes hidden)
}
- custom_taints {
- effect = "NoSchedule" -> null
- key = "scheduling.cast.ai/node-template" -> null
- value = "graviton" -> null
}
}What will happen if we do the terraform apply which will remove the custom_taints? Will new nodes still be tainted with the node_template name or will new nodes not have any taints?
- custom_taints {
- effect = "NoSchedule" -> null
- key = "scheduling.cast.ai/node-template" -> null
- value = "graviton" -> null
}IfshouldTaint is true, but no custom taints are provided, the nodes will be tainted with the default node template taint
So as the custom taints are not defined in the following node template that you want to apply, it will delete the custom taints and post changes the nodes created using this node template will have a default node template taint.
In the default template, both architectures are allowed and it appears the nodes are not tainted - how does the workload know where to land or stay away from a particular node?
If the workload has affinity for both architectures, it allows CAST AI autoscaler to place it on the cheapest type available regardless of the architecture.
Once you have modified the "default" CAST AI node template to include both architectures, what is preventing Graviton nodes from being created in the general workload?
CAST AI defaults to x86, but the option to enable both architectures is available if workloads are compatible.
I am trying to create a new node template (not the default) for multi-arch. Should I just copy the configs from the default template and possibly taint for multi-arch use?
The workloads would also need the affinity we provide in the UI with the kubernetes.io/arch label and the values for both architectures.
So it would be nodeSelector for the template, tolerations for the template, and the affinity for the architectures.
Examples:
nodeAffinity for architectures: Add the following node affinity to the specification to indicate that the workload can be scheduled on nodes with both types of processors:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- arm64
- amd64- nodeSelector for nodeTemplate: When using a multi-architecture node template, also use the NodeSelector kubernetes.io/arch: "arm64" to ensure that the pod lands on an ARM node.
- toleration for nodeTemplate
tolerations:
- key: "scheduling.cast.ai/node-template"
value: "taintedarm"
operator: "Equal"
effect: "NoSchedule"How are node configurations linked to multiple templates at the same time?
The node configuration determines things like in which subnets nodes can be created, what ami they use, etc., while the node template allows you to constrain the types that are picked for certain workloads.
Can you check in historical data which node templates were running specific nodes for a given timeframe?
If you have the CAST AI node ID, an easy method to determine the node template name for a node is to review the audit logs and apply a filter based on the node ID. By inspecting the log of node creation, you can identify the node label associated with the node template.
How can I set the pod capacity in CAST AI?
AWS CNI has a mode that enables to provision of more Pods (more IPs for small EC2 instances increasing ENI limit).
kubectl set env daemonset aws-node -n kube-system ENABLE_PREFIX_DELEGATION=truevalidate:
kubectl describe daemonset -n kube-system aws-node | grep ENABLE_PREFIX_DELEGATIONIt requires to set in Autoscaler -> nodeConfiguration -> Init script:
# !/bin/bash
KUBELET_CONFIG=/etc/kubernetes/kubelet/kubelet-config.json
echo "$(jq ".maxPods=110" $KUBELET_CONFIG)" > $KUBELET_CONFIG
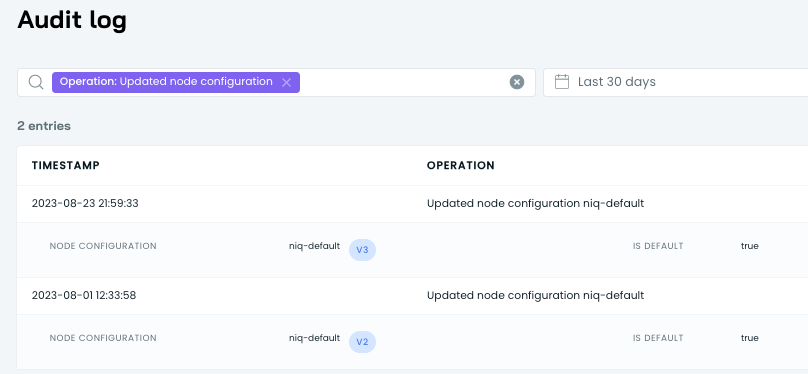
systemctl restart kubeletWhere can I see this node configuration version history in CAST AI?
You can go to audit logs and check the changes - select filter operation Updated node configuration
One of my workloads is putting some node in Not Ready status when I'm trying to do a rebalance. How can I fix that issue ?
Example:
issues:
kind: TopologySpread
description: Unsupported topology spread key: kubernetes.io/hostnameCurrently, CAST AI does not support pod affinity using the kubernetes.io/hostname topology key.
I have two node templates with different nodeSelectors and tolerations. Can I use both node templates in my deployment, and will CAST AI provision nodes from both templates?
No, CAST AI autoscaler will find any instance matching a separate node template and eventually add an event to the pending pod.
Why did CAST AI create 102 GB volumes instead of 100 GB, which we mention in our node config?
This is the formula for calculating disk size:
int32(nodeCfg.Template.MinDiskSize) + int32(instanceType.Vcpu)\*int32(nodeCfg.Template.DiskCPURatio)This is a Bottlerocket node, the second device is created by us. The first volume is too small for pods to use, and the 2 GB correspond to OS image.
It looks like neither the CAST AI rebalancer nor autoscaler use our custom node templates even though they have no labels, taints, or config that would out select them from certain workloads. It forces all non-system nodes to run on the default template and the rebalancer complains if the default template is disabled. Why is this the case?
CAST AI needs a way to determine which node template to use, in this case, the workloads don't have a node selector so there is no way for CAST AI to detect which workloads to put on default vs. general-purpose-on-demand vs. general-purpose-spot.
This would result in non-deterministic scaling because a workload is valid on all three of those node templates. We don't currently support unlabeled scaling on a non-default pool. If there are workloads that need to run on-demand we will need to add a nodeSelector and label for that node template.
How can we bypass spot, and do we have any ways to achieve it?
You can enable both the on-demand and spot resource offerings in a template, but would then need to tell the autoscaler what workloads should be placed on spot by giving them the spot nodeSelector and toleration:
tolerations:
- key: scheduling.cast.ai/spot
operator: Exists
nodeSelector:
scheduling.cast.ai/spot: "true"Workloads without this will get on-demand nodes, and those with it will get spot instances.
Will CAST AI still try to add a fallback node to the cluster if spot instances aren't available for a particular node template and the application has the following nodeAffinity?
Scenario:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduling.cast.ai/spot-fallback
operator: DoesNotExistCAST AI won’t add fallbacks in such cases.
Is there any way to set an upper limit on the number of nodes or the maximum total memory/CPU for a particular node template?
We can put a cap on the number of cores in the overall cluster but not for a particular template.
If you use the node template for a dedicated namespace, you can use NamespaceQuotas to get the same result.
Why are spot fallback nodes not getting replaced?
The problem may be that you have turned off the default node template.
All of the spot fallbacks are nodes managed by a node template, but the node template doesn't have any taints. So, it may happened that pods without any selectors manage to get scheduled on them. But when the spot fallback replacement logic kicks in, it finds that the default node template is turned off and it won't be able to satisfy those pods, so it leaves them hanging. You should either enable the default node template or add taints to those node templates.
My workload has tolerations matching taints on a node template, but it's landing on a default node template without taints. Why?
The Kubernetes scheduler places pods based on nodeSelectors and affinities, not tolerations. Tolerations indicate where pods are allowed to run, but they do not determine placement. To scale based on specific criteria, such as taints, you must use nodeSelectors in addition to tolerations.
What AMIs are supported by CAST AI?
CAST AI supports AMIs with the families "AL2" and "Bottlerocket".
How long is an instance blacklisted if it fails to add, and how can I manually whitelist it?
If an instance fails to add, such as due to quota issues, it is automatically blacklisted for 24 hours. To manually whitelist it before the period expires, you can use the “Remove Blacklist” API endpoint here: Remove Blacklist API.
What AMI is used for EC2 instances provisioned by CAST AI?
The AMI is determined by the node configuration associated with the node template. If no specific AMI is provided in the configuration, CAST AI automatically selects the latest available image that is compatible with the specified Kubernetes version.