
Troubleshooting
Your cluster does not appear on the Connect Cluster screen
If the cluster does not appear on the Connect your cluster screen after you've run the connection script, perform the following steps:
1. Check agent container logs:
```shell
kubectl logs -n castai-agent -l app.kubernetes.io/name=castai-agent -c agent
```2. You might get output similar to this:
```text
time="2021-05-06T14:24:03Z" level=fatal msg="agent failed: registering cluster: getting cluster name: describing instance_id=i-026b5fadab5b69d67: UnauthorizedOperation: You are not authorized to perform this operation.\n\tstatus code: 403, request id: 2165c357-b4a6-4f30-9266-a51f4aaa7ce7"
```
or
```text
time="2021-05-06T14:24:03Z" level=fatal msg=agent failed: getting provider: configuring aws client: NoCredentialProviders: no valid providers in chain"
```
or
```text
time="2023-08-18T18:44:49Z" level=error msg="agent failed: getting provider: configuring aws client: getting instance region: EC2MetadataRequestError: failed to get EC2 instance identity document\ncaused by: RequestError: send request failed\ncaused by: Get \"http://169.254.169.254/latest/dynamic/instance-identity/document\": context deadline exceeded (Client.Timeout exceeded while awaiting headers)"These errors indicate that the CAST AI agent failed to connect to the AWS API. The reason may be that your cluster's nodes and/or workloads have custom-constrained IAM permissions, or the IAM roles are removed entirely.
However, the CAST AI agent requires read-only access to the AWS EC2 API to identify some properties of your EKS cluster correctly. Access to the AWS EC2 Metadata endpoint is optional, but the variables discovered from the endpoint must then be provided.
The CAST AI agent uses the official AWS SDK, so it supports all variables to customize your authentication mentioned in its documentation.
Provide cluster metadata by adding these environment variables to the CAST AI agent deployment:
- name: EKS_ACCOUNT_ID
value: "000000000000" # your aws account id
- name: EKS_REGION
value: "eu-central-1" # your eks cluster region
- name: EKS_CLUSTER_NAME
value: "staging-example" # your eks cluster nameIf you're rather using GCP GKE, you can provide the following environment variables to overcome the lack of access to VM metadata:
- name: GKE_PROJECT_ID
value: your_project_id
- name: GKE_CLUSTER_NAME
value: your_cluster_name
- name: GKE_REGION
value: your_cluster_region
- name: GKE_LOCATION
value: your_cluster_azThe CAST AI agent requires read-only permissions, so the default AmazonEC2ReadOnlyAccess is sufficient. Provide AWS API access by adding these variables to the CAST AI Agent secret:
AWS_ACCESS_KEY_ID = xxxxxxxxxxxxxxxxxxxx
AWS_SECRET_ACCESS_KEY = xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxHere is an example of a CAST AI agent deployment and secret with all the mentioned environment variables:
# Source: castai-agent/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: castai-agent
namespace: castai-agent
labels:
app.kubernetes.io/name: castai-agent
app.kubernetes.io/instance: castai-agent
app.kubernetes.io/version: "v0.23.0"
app.kubernetes.io/managed-by: castai
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: castai-agent
app.kubernetes.io/instance: castai-agent
template:
metadata:
labels:
app.kubernetes.io/name: castai-agent
app.kubernetes.io/instance: castai-agent
spec:
priorityClassName: system-cluster-critical
serviceAccountName: castai-agent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "kubernetes.io/os"
operator: In
values: [ "linux" ]
- matchExpressions:
- key: "beta.kubernetes.io/os"
operator: In
values: [ "linux" ]
containers:
- name: agent
image: "us-docker.pkg.dev/castai-hub/library/agent:v0.24.0"
imagePullPolicy: IfNotPresent
env:
- name: API_URL
value: "api.cast.ai"
- name: PPROF_PORT
value: "6060"
- name: PROVIDER
value: "eks"
# Provide values discovered via AWS EC2 Metadata endpoint:
- name: EKS_ACCOUNT_ID
value: "000000000000"
- name: EKS_REGION
value: "eu-central-1"
- name: EKS_CLUSTER_NAME
value: "castai-example"
envFrom:
- secretRef:
name: castai-agent
resources:
requests:
cpu: 100m
limits:
cpu: 1000m
- name: autoscaler
image: k8s.gcr.io/cpvpa-amd64:v0.8.3
command:
- /cpvpa
- --target=deployment/castai-agent
- --namespace=castai-agent
- --poll-period-seconds=300
- --config-file=/etc/config/castai-agent-autoscaler
volumeMounts:
- mountPath: /etc/config
name: autoscaler-config
volumes:
- name: autoscaler-config
configMap:
name: castai-agent-autoscaler# Source: castai-agent/templates/secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: castai-agent
namespace: castai-agent
labels:
app.kubernetes.io/instance: castai-agent
app.kubernetes.io/managed-by: castai
app.kubernetes.io/name: castai-agent
app.kubernetes.io/version: "v0.23.0"
data:
# Keep API_KEY unchanged.
API_KEY: "xxxxxxxxxxxxxxxxxxxx"
# Provide an AWS Access Key to enable read-only AWS EC2 API access:
AWS_ACCESS_KEY_ID: "xxxxxxxxxxxxxxxxxxxx"
AWS_SECRET_ACCESS_KEY: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"Alternatively, if you use IAM roles for service accounts you can annotate the castai-agent service account instead of providing AWS credentials with your IAM role.
kubectl annotate serviceaccount -n castai-agent castai-agent eks.amazonaws.com/role-arn="arn:aws:iam::111122223333:role/iam-role-name"Spot nodes show as On-demand in the cluster's Available Savings page
See this section.
TLS handshake timeout issue
In some edge cases, due to specific cluster network setup, the agent might fail with the following message in the agent container logs:
time="2021-11-13T05:19:54Z" level=fatal msg="agent failed: registering cluster: getting namespace \"kube-system\": Get \"https://100.10.1.0:443/api/v1/namespaces/kube-system\": net/http: TLS handshake timeout" provider=eks version=v0.22.1You can resolve this issue by deleting the castai-agent pod. The deployment will recreate the pod and resolve the issue.
Refused connection to control plane
When enabling automated cluster optimization for the first time, the user runs a pre-generated script to grant required permissions to CAST AI. The error message No access to Kubernetes API server, please check your firewall settings indicates that a firewall prevents communication between the control plane and CAST AI.
To solve this issue, allow access to CAST AI IP 35.221.40.21 and then enable automated optimization again.
Disconnected or Not responding cluster
If the cluster has a Not responding status, most likely the CAST AI agent deployment is missing. Press Reconnect and follow the instructions provided.
The Not responding state is temporary, and unless fixed, the cluster will enter the Disconnected state. If your cluster is disconnected, you can reconnect or delete it from the console, as shown below.
The delete action only removes the cluster from the CAST AI console, leaving it running in the cloud service provider.
Upgrading the agent
For clusters onboarded via console
To check the version of the agent running on your cluster, use the following command:
kubectl describe pod castai-agent -n castai-agent | grep castai-hub/library/agent:vYou can cross-check our GitHub repository for the number of the latest version available.
To upgrade the CAST AI agent version, please perform the following:
- Go to Connect cluster.
- Select the correct cloud service provider.
- Run the provided script.
In case of an error when upgrading the agent e.g. MatchExpressions:[]v1.LabelSelectorRequirement(nil)}: field is immutable run the command kubectl delete deployment -n castai-agent castai-agent and repeat step 3.
The latest version of the CAST AI agent is now deployed in your cluster.
For clusters onboarded via Terraform
By default, Terraform modules do not specify the cast-agent Helm chart version. As a result, the latest available cast-agent Helm chart is installed when onboarding the cluster, but as new agent versions are released, re-running Terraform doesn't upgrade the agent.
We are looking to solve this, but a short-term fix would be to provide a specific agent version as TF variable agent-version and re-apply Terraform plan. For valid values of the castai-agent Helm chart, see releases of CAST AI helm-charts.
Deleted agent
If you delete the CAST AI agent deployment from the cluster, you can re-install the agent by re-running the script from the Connect cluster screen. Please ensure you choose the correct cloud service provider.
Cluster controller is receiving forbidden access error
In some scenarios, during multiple onboardings, failing updates or other issues, the cluster token used by the cluster controller can get invalidated. By becoming forbidden from accessing the CAST AI API, it fails to operate the cluster.
To renew it, you should run the following Helm commands:
helm repo update
helm upgrade -i cluster-controller castai-helm/castai-cluster-controller -n castai-agent \
--set castai.apiKey=$CASTAI_API_TOKEN \
--set castai.clusterID=<your-cluster-id>AKS version not supported
During the cluster onboarding to CAST AI managed mode, the onboarding process will create a new Node Pool. Microsoft Azure Cloud enforces certain restrictions for Node Pool creations:
- Node Pool can NOT be newer than your AKS cluster control plane version.
- Microsoft support only a very small number of minor/patch K8s versions for Node Pool creation. Azure documentation.
You can check the list of supported AKS versions in your region:
❯ az aks get-versions --location eastus --output table
KubernetesVersion Upgrades
------------------- -----------------------
1.26.3 None available
1.26.0 1.26.3
1.25.6 1.26.0, 1.26.3
1.25.5 1.25.6, 1.26.0, 1.26.3
1.24.10 1.25.5, 1.25.6
1.24.9 1.24.10, 1.25.5, 1.25.6If your AKS cluster control plane version is 1.24.8, no new Node Pools can be created (CAST AI or not). To continue CAST AI onboarding, upgrade the AKS control plane to the nearest patch version say 1.24.9 or 1.24.10 (at the time of writing), and re-run the onboarding script. There is no need to upgrade your existing nodes, just the Control Plane.
AKS fail to pull images from Azure Container Registry to Azure Kubernetes Service cluster
If the cluster is already attached to the ACR after onboarding on CAST AI, the Service Principal created to manage the cluster might not have the correct permissions to pull images from the private ACRs. This may result in failed to pull and unpack image, failed to fetch oauth token: unexpected status: 401 Unauthorized when creating new nodes.
Microsoft has detailed documentation on troubleshooting and fixing the issue: Fail to pull images from Azure Container Registry to Azure Kubernetes Service cluster.
In most cases, Solution 1: Ensure AcrPull role assignment is created for identity is enough to resolve it.
Custom secret management
There are many technologies for managing Secrets in GitOps. Some store the encrypted secret data in a git repository and use a cluster add-on to decrypt the data during deployment. Some other use a reference to an external secret manager/vault.
The agent helm chart provides the parameter apiKeySecretRef to enable the use of CAST AI with custom secret managers.
# Name of secret with Token to be used for authorizing agent access to the API
# apiKey and apiKeySecretRef are mutually exclusive
# The referenced secret must provide the token in .data["API_KEY"]
apiKeySecretRef: ""An example of the CAST AI agent
Here's an example of using a CAST AI agent helm chart with a custom secret:
helm repo add castai-helm https://castai.github.io/helm-charts
helm repo update
helm upgrade --install castai-agent castai-helm/castai-agent -n castai-agent \
--set apiKeySecretRef=<your-custom-secret> \
--set clusterID=<your-cluster-id>An example of the CAST AI cluster controller
An example of using CAST AI cluster controller helm chart with a custom secret:
helm repo add castai-helm https://castai.github.io/helm-charts
helm repo update
helm upgrade --install castai-agent castai-helm/castai-cluster-controller -n castai-agent \
--set castai.apiKeySecretRef=<your-custom-secret> \
--set castai.clusterID=<your-cluster-id>Cannot access the Workloads Efficiency tab
It could be the case that the CAST AI agent cannot discover and poll metrics from the Metrics Server.
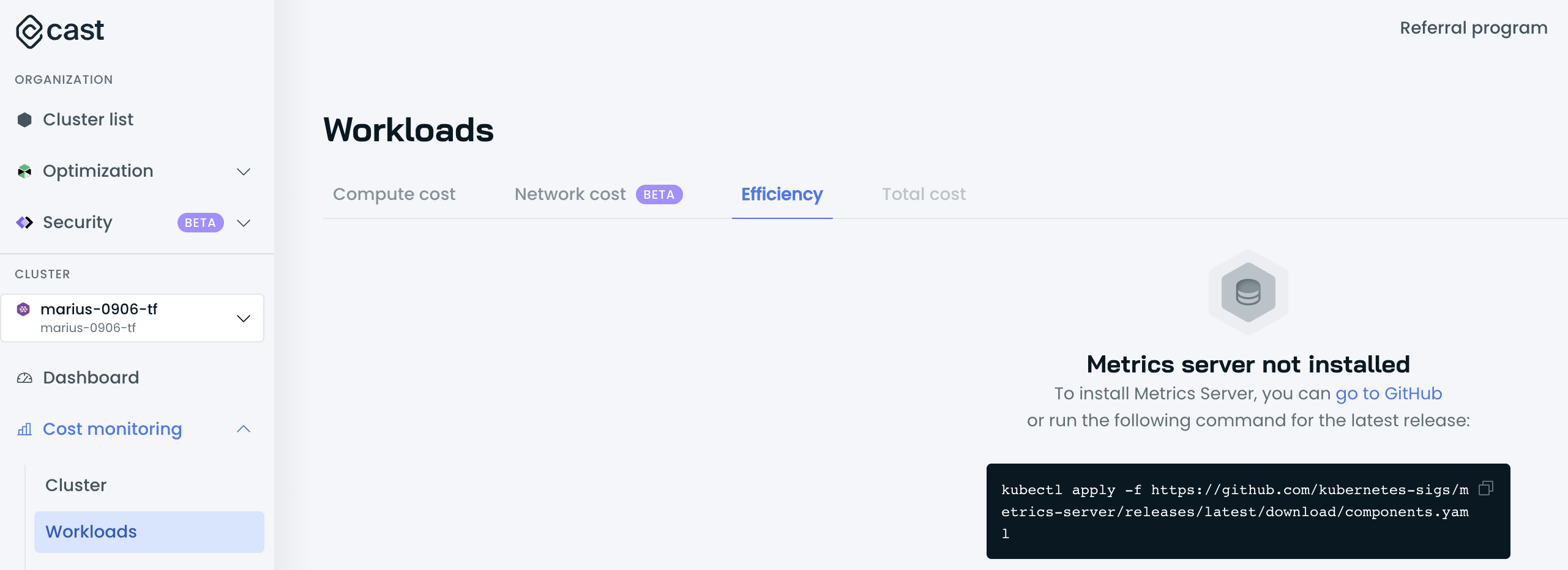
Validate whether the Metrics Server is running and is accessible by running the following commands:
kubectl get deploy,svc -n kube-system | egrep metrics-serverIf Metrics Server is installed, the output is similar to the following example:
deployment.extensions/metrics-server 1/1 1 1 3d4h
service/metrics-server ClusterIP 198.51.100.0 <none> 443/TCP 3d4hIf the Metrics Server is not running, follow the installation process here.
If the Metrics Server is running, verify that the Metrics Server is returning data for all pods by issuing the following command:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods"The output should be similar to the one below:
{"kind":"PodMetricsList","apiVersion":"metrics.k8s.io/v1beta1","metadata":{},
"items":[
{"metadata":{"name":"castai-agent-84d48f88c9-44tr8","namespace":"castai-agent","creationTimestamp":"2023-03-15T12:28:12Z","labels":{"app.kubernetes.io/instance":"castai-agent","app.kubernetes.io/name":"castai-agent","pod-template-hash":"84d48f88c9"}},"timestamp":"2023-03-15T12:27:36Z","window":"27s","containers":[{"name":"agent","usage":{"cpu":"5619204n","memory":"75820Ki"}}]}
]}If no output or erroneous output is returned, review the configurations of your Metrics Server and/or reinstall it.
If those checks passed, look for any unavailable apiservices with the following command:
kubectl get apiservicesThe output should be similar to the following example:
NAME SERVICE AVAILABLE AGE
v1. Local True 383d
v1.acme.cert-manager.io Local True 161d
v1.admissionregistration.k8s.io Local True 383d
v1.apiextensions.k8s.io Local True 383d
v1.apps Local True 383d
v1.authentication.k8s.io Local True 383d
v1.authorization.k8s.io Local True 383d
v1.autoscaling Local True 383d
v1.batch Local True 383dAll apiservices must show True in the available column. Any that show False will need to be repaired if its still in use by one your workloads. If it is not still in use, the apiservice can be deleted.
If everything looks good, but you still cannot access the Workloads Efficiency tab, please contact our support.
Max Pod Count on AWS CNI
There are situations when you can get VMs in AWS which will have low upper limit of max pod count, i.e. 58 for c6g.2xlarge. Full list of ENI limitations per instance type available at eni-max-pods.txt.
This can be mitigated in two ways
- Setting Min CPU constraints in Node Templates to 16 CPUs, as the issue only exists on nodes that are lower on CPUs (i.e. 8 CPU nodes)
- Increasing the pods per node limits, you can do it by executing the following within your cluster context:
kubectl set env daemonset aws-node -n kube-system ENABLE_PREFIX_DELEGATION=true- Amazon VPC CNI plugin increases pods per node limits
- Increase the amount of available IP addresses for your Amazon EC2 nodes
Topology spread constraints
Kubernetes Scheduler
Pods might not get scheduled as intended due to conflicting or incorrectly configured topology spread constraints.
Here's what you can do to troubleshoot this issue:
- Review constraints: ensure your topology spread constraints are configured correctly in the Pod specs. Verify the
maxSkew,topologyKey, andwhenUnsatisfiableparameters. - Verify node labels: ensure your nodes have accurate and required labels. If
topologyKeyreferences node labels, these must be consistent across all nodes. - Check the scheduler logs: inspect the Kubernetes scheduler logs for any issues or warnings related to Pod scheduling. Use
kubectl describe pod <pod-name>to see events and errors. - Inspect resource utilization: ensure that your nodes have enough resources to accommodate the Pods following spread constraints. Insufficient resources or tight constraints might lead to scheduling issues.
Event: Cannot Satisfy Zone Topology Spread
topology.kubernetes.io/zone is a supported topology spread constraint key in the Node Placer, allowing you to deploy Pods in a highly available way to take advantage of the cloud zone redundancy.
The Kubernetes Scheduler will take all cluster nodes and extract availability zones (AZs), which are used for distributing workloads across cluster nodes and utilizing topology spread constraints.
CAST AI's Autoscaler won't scale Pods up when it detects that it can't create new nodes in the AZs for which the cluster isn't configured, even when it contains nodes in non-configured zones. Instead, it will add a Cannot Satisfy Zone Topology Spread event to them.
Here's what you can do to troubleshoot this issue:
- Check for which AZs the cluster is configured: if the cluster has nodes in AZs that aren't configured, remove those nodes from the cluster.
- Configure the cluster to use the required AZs for nodes.
- Configure stricter node affinity on workload specifying only the configured AZs.
After implementing the troubleshooting steps, initiate reconciliation on the updated cluster.
Example Deployment
This example deployment is expected to spawn at least 3 nodes in different zones, each of them running 10
replicas.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: az-topology-spread
name: az-topology-spread
spec:
replicas: 30
selector:
matchLabels:
app: az-topology-spread
template:
metadata:
labels:
app: az-topology-spread
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- az-topology-spread
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 1000mUpdated 7 months ago