
Autoscaler preparation checklist
After successfully enabling Cast AI's automation features, turning on and testing the following aspects will help you ensure the platform's autoscaling engine operates properly.
Further fine-tuning might be necessary for specific use cases.
Before enabling autoscaling in production
Cast AI's autoscaler and Evictor work by provisioning and removing nodes, and by evicting and rescheduling pods. Workloads that do not follow Kubernetes best practices can experience unexpected downtime when automation is active.
Before enabling autoscaling on a production cluster, verify that your workloads meet the following requirements:
| Requirement | Why it matters |
|---|---|
| PodDisruptionBudgets (PDBs) configured for all critical workloads | Without a PDB, Evictor may evict all pods of a deployment simultaneously. A PDB with minAvailable: 1 is the minimum recommended setting. See PodDisruptionBudgets. |
imagePullPolicy is not Always unless required | Always introduces delays when pods are rescheduled to new nodes, and will fail entirely if the registry is temporarily unreachable. |
| Startup probes configured for services with slow initialization | JVM-based services and other slow-starting workloads should have startup probes to prevent traffic routing before the app is ready. This is a best practice rather than a hard requirement. |
| Stateful workloads reviewed individually | Databases, caches, and message queues must have data replication in place and be able to tolerate pod restarts. |
Pod startup times are compatible with nodeGracePeriodMinutes | The default grace period before Evictor targets a new node is 5 minutes. Workloads with slow startup times may need this value increased. |
TipEnable and validate autoscaling in a staging or development environment with representative workloads before rolling it out to production. See the Evictor documentation for more details on production readiness.
Goals
- Upscale the cluster during peak hours.
- Binpack or downscale the cluster when excess capacity is no longer required.
- Use Spot Instances to reduce your infrastructure costs, but have the safety of on-demand instances when needed.
Recommended setup
The following section describes the Autoscaling policy setup needed to achieve these goals.
Unscheduled pods policy
To upscale a cluster, Cast AI needs to react to unschedulable pods. You can achieve this by turning on the Unscheduled Pods policy and configuring the Default Node template.
What is an unschedulable pod?This term refers to a pod stuck in a pending state, meaning that it cannot be scheduled onto a node. Generally, this is because insufficient resources of one type or another prevent scheduling.
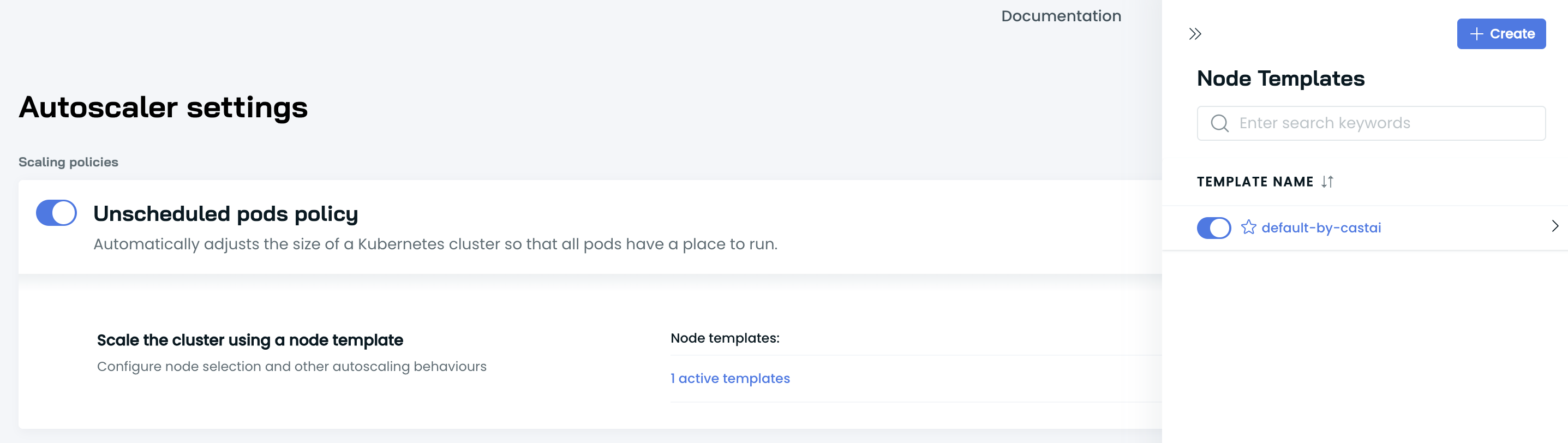
Unscheduled pods policy with Default Node template
Why?
✅ Automatically add the required capacity to the cluster.
✅ Enable Spot instances to allow CAST AI to handle spot instances & their interruptions.
✅ Enable Spot Fallbacks to automatically switch back and forth to the on-demand capacity when spots are not available in the cloud environment.
Node deletion policy / Evictor
CAST AI can constantly binpack the cluster and remove any excess capacity. To achieve this goal, we recommend the following initial setup:
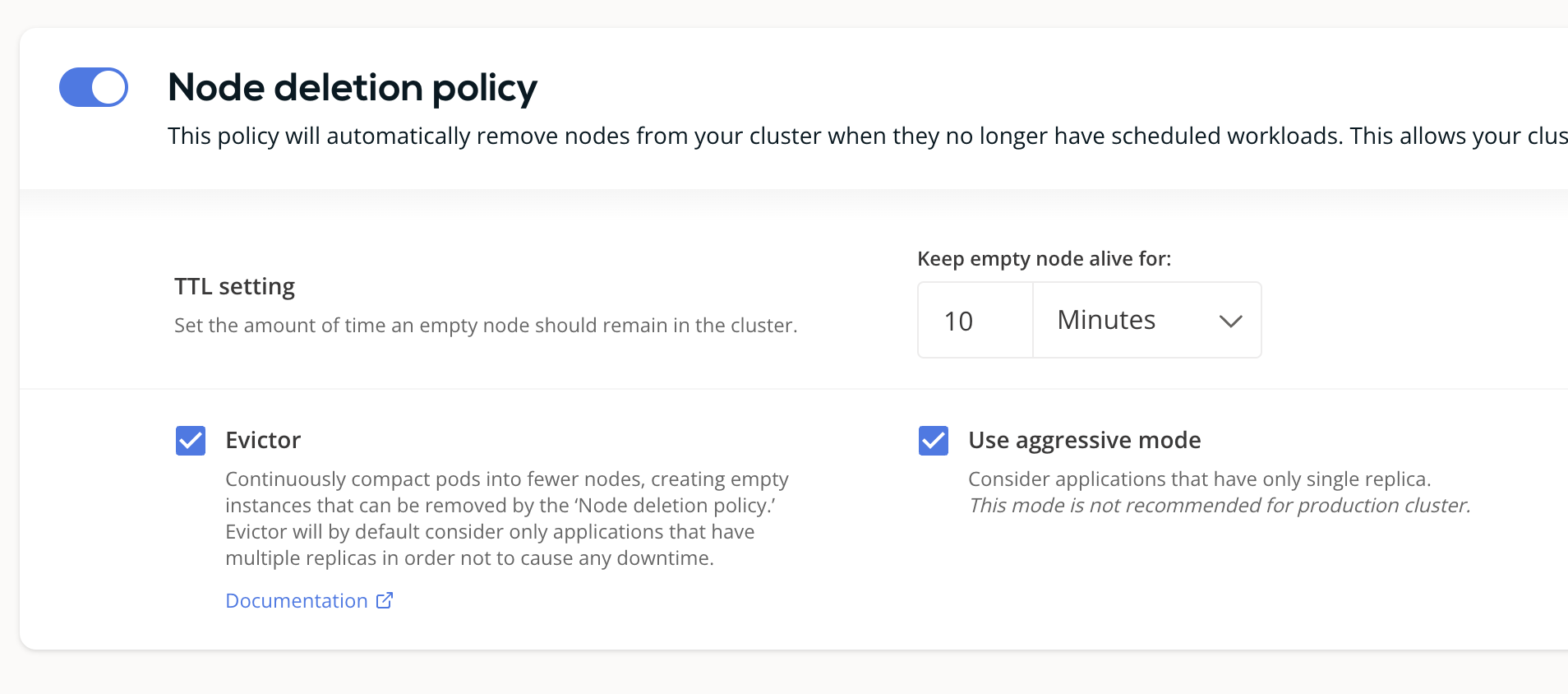
Node deletion policy recommended settings
Why?
✅ Ensure that empty nodes are not running in the cluster for longer than the configured duration.
✅ Enable Evictor for higher node resource utilization & less waste. Evictor continuously simulates scenarios where it tries to eliminate underutilized nodes by checking if the pods could be scheduled in the remaining capacity. Simulation respects PDBs and all other Kubernetes restrictions. Configure PDBs for all critical workloads before enabling Evictor — without a PDB, there is no guarantee that at least one replica will remain available during bin-packing.
What is Evictor's aggressive mode?When Evictor runs in aggressive mode, it considers workloads with a single replica as potential targets for binpacking. This might cause some disruption in single-replica workloads.
Testing
After completing the basic setup, we recommend performing a simple upscale/downscale test to verify that the autoscaler functions correctly and that the cluster can scale up and down as needed.
➡️ First, deploy the following spot workload to check if the autoscaler reacts to the need for spot capacity:
kubectl apply -f https://raw.githubusercontent.com/castai/examples/main/evictor-demo-pods/test_pod_spot.yaml# https://github.com/castai/examples/blob/main/evictor-demo-pods/test_pod_spot.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: castai-test-spot
namespace: castai-agent
labels:
app: castai-test-spot
spec:
replicas: 10
selector:
matchLabels:
app: castai-test-spot
template:
metadata:
labels:
app: castai-test-spot
spec:
tolerations:
- key: scheduling.cast.ai/spot
operator: Exists
nodeSelector:
scheduling.cast.ai/spot: "true"
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 4✅ This step ensures that Cast AI has all the relevant access to upscale your cluster automatically.
➡️ Once the capacity is added, check that your desired DaemonSet pod count matches the node count.
# Get DaemonSets in all namespaces
kubectl get ds -A
# Get Node count
kubectl get nodes | grep -v NAME | wc -l➡️ Verify that the deployed pod is Running, then run:
kubectl scale deployment/castai-test-spot --replicas=0✅ Verify that Cast AI eliminates empty nodes in the configured time interval.
Troubleshooting
Partially managed by Cast AI
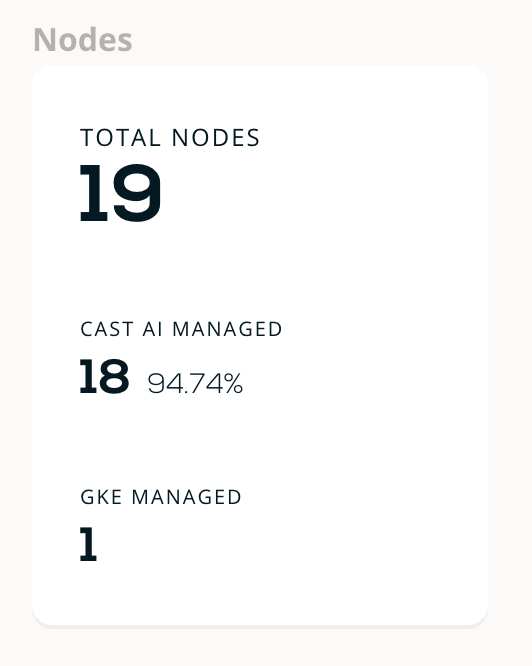
One node not managed by Cast AI
- In some situations, when you connect a cluster, it may not be immediately fully managed by Cast AI. This means that some workloads still run on existing legacy node pools/Autoscaling groups.
- We recommend adding
autoscaling.cast.ai/removal-disabled="true"on such node pools/Autoscaling groups so that Cast AI can exclude such nodes from the Evictor & Rebalancing features.