
How does it work?
Explore the architecture and key components of our database optimization.
Overview
Cast AI DB Optimizer (DBO) proxies and caches database queries using native database wire protocols. It connects to your current database transparently and requires no code or configuration; simply update your database connection string to route database traffic through the Proxy.
Queries are inspected in real-time and reads (SQL SELECT) are cached and served sub-millisecond from the cache, no matter the query complexity. All other traffic (INSERT, UPDATE, DELETE, etc.) seamlessly passes through to the origin database, automatically invalidating any changed data from the cache in real time. (Smart Invalidation).
Architecture
DBO consists of two components that are hosted within your architecture. These are collectively referred to as the Cache:
- Proxy - A high-performance, low-latency SQL proxy that caches data and proxies queries to the origin database.
- Query Processor - An advanced, ML-driven cache intelligence engine. The Query Processor communicates in real-time with the Proxy to determine what to cache and how long to cache it for. It is also responsible for invalidating the cache in real time based on observed Data Manipulation Language (DML) queries.
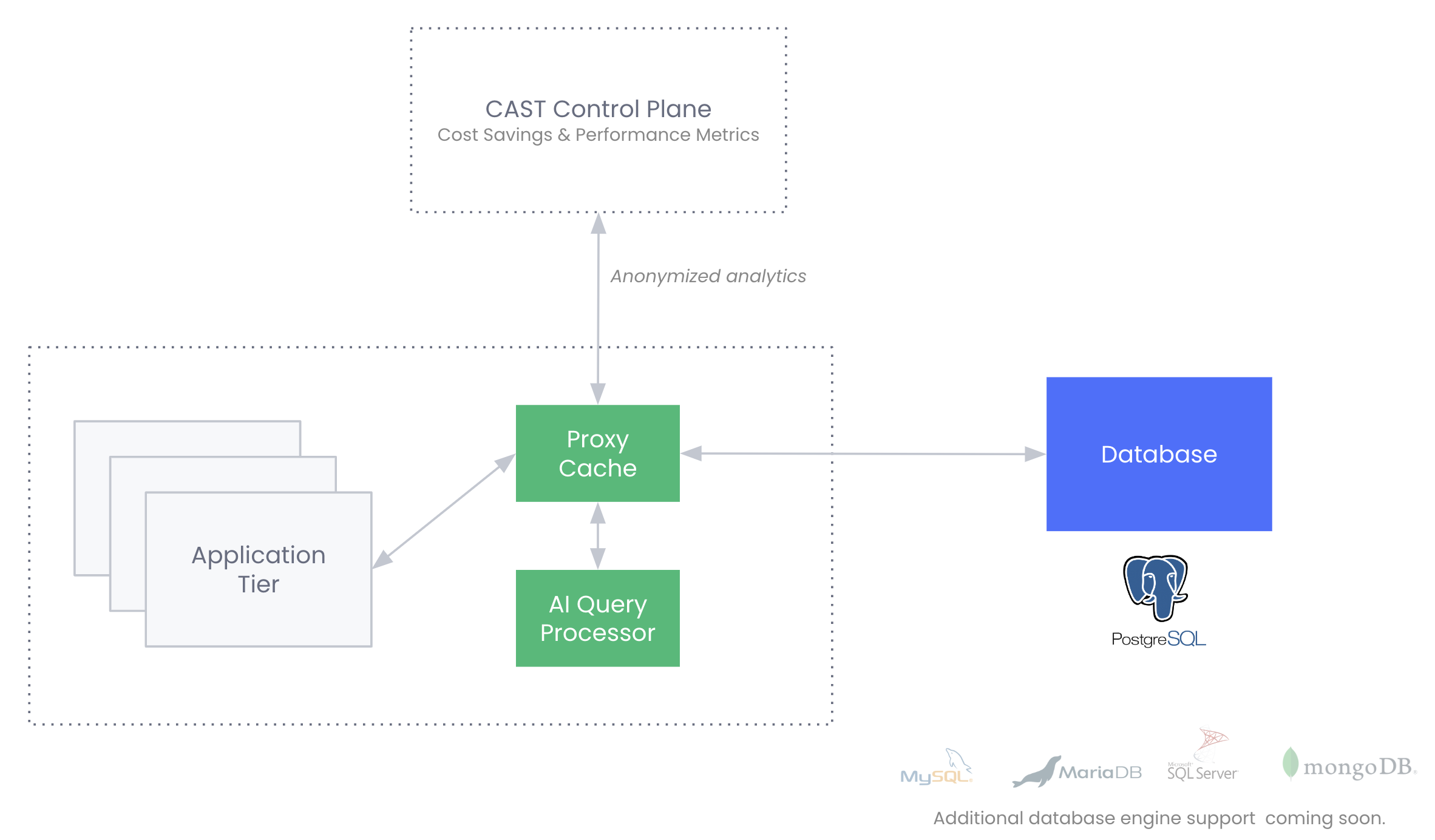
Architecture overview with Cast DBO deployed.
The diagram illustrates how our engine sits between the database and applications. The Cast AI engine consists of the ML query processor and proxy cache components that run within your infrastructure (customer premises). These components communicate with the Cast AI control plane, which only receives anonymized metadata for monitoring and performance optimization purposes. Your applications connect to the proxy, which intelligently handles both read and write operations, ensuring optimal performance while maintaining data consistency.
Get started with the Quick start guide.
Database Caching Modes
DBO offers three operating modes for database caching, providing flexibility to match your specific needs and comfort level:
Passthrough Mode
In passthrough mode, the Cast AI caching proxy operates in a read-only monitoring state:
- All queries pass through to your database without any caching
- DBO observes and analyzes your query patterns and traffic
- Metrics are collected to show potential caching benefits and performance improvements
- Zero impact on your production traffic or application behavior
- Allows you to understand caching opportunities before enabling active caching
This mode is ideal for initial deployment, allowing you to gain confidence in DBO's potential benefits without any risk.
Auto Mode
Auto mode leverages Cast AI's ML-driven caching engine:
- The proxy automatically caches all eligible queries
- ML algorithms determine optimal TTL values for each query based on observed patterns
- Continuously adapts to changes in your workload
- Smart Invalidation ensures data consistency
- No configuration required - fully autonomous operation
This is the recommended mode for most use cases, providing optimal caching performance with zero manual intervention.
Manual Mode
Manual mode provides complete control over caching behavior:
- No data is cached automatically
- Only queries for which override rules have been specified will be cached
- Full control over which queries or tables are cached
- Precise TTL configuration for specific use cases
- Ideal when you have specific caching requirements or compliance needs
TTL Configuration and Override Rules
Within Auto and Manual modes, DBO provides granular control over Time-To-Live (TTL) settings through override rules. These rules can be applied at the query or table level:
Query-Level Overrides
For individual queries, you can configure:
- Fixed TTL: Set a specific TTL value (in seconds) for caching the query results
- Dynamic: Allow Cast AI to determine the optimal TTL based on query patterns (default in Auto mode)
- Caching Off: Disable caching entirely for specific queries that should always hit the database
Table-Level Rules
Apply caching policies to all queries targeting specific tables:
- Rules cascade to all queries accessing the specified table
- Useful for tables with known update patterns or compliance requirements
- Simplifies management across multiple related queries
Override Behavior
- In Auto mode: Override rules supplement the ML-driven caching, allowing you to fine-tune specific queries or tables while the ML handles everything else
- In Manual mode: Only queries matching override rules will be cached; all other queries pass through to the database
Wire Protocol Compatible
DBO is designed to be fully compatible with native database wire protocols, which means:
- No Code Changes - Integrate with your applications in minutes without any code modifications
- Any Programming Language - Connect with any database driver across any programming language
- Polyglot Data Systems - Support for multiple database engines (PostgreSQL and MySQL now, MariaDB, MS SQL, and MongoDB on the roadmap)
- No Migrations - Zero data to modify or migrate
Cached Data
DBO caches database responses, i.e., the payloads returned from the origin database when a query is executed. These are stored in memory within the Proxy.
Caching Protocol
ML-driven, Fully Autonomous Cache
When operating in Auto mode, DBO utilizes machine learning to automate caching behavior. Caching operates at the level of unique SQL queries. Typically, an application generates thousands of unique queries with complex temporal dynamics and inter-dependencies. Managing the caching of these queries requires automation, and optimizing it requires machine learning.
Unlike traditional caching solutions that require query candidate identification, application-level integration, and manual configuration, DBO's ML engine is designed to find data patterns automatically. Once identified, it caches all that traffic across the entire workload without any developer intervention.
Automated Caching
DBO's machine learning algorithms identify caching opportunities by recognizing and remembering patterns in query traffic. The algorithms run continuously in the background and update on every query, rapidly adapting to changes in traffic as they arise. At any moment, the most up-to-date optimal cache configurations are applied. The algorithms manage caching at a scale far beyond the abilities of a human.
With DBO's automated approach, you can:
- Cache Everything - Cache entire, complex applications in minutes
- Future Proof - Every feature added to your application will be automatically optimized
- Achieve Linear Scaling - As data volumes grow, maintain consistent performance without increasing database instance size
Time To First Hit (TTFH)
The time to first hit is determined by multiple attributes of the particular query being processed: the arrival rate, the change rate of the query result, and the number of related queries seen, among other things. If the cache is automatically managed (default behavior) and the query being processed is new, i.e., it has never been seen, and no related queries have been seen by DBO previously, a cache hit will occur on or about the 3rd query. This will be reduced to as low as the 2nd query if the query being processed is similar to a previously processed query, i.e., the same query structure with different parameters.
Cache Invalidation
To guarantee the cache is invalidated accurately, DBO provides multiple layers of cache invalidation:
Smart Invalidation
Smart Invalidation is DBO's automated cache invalidation system. It is designed to provide 100% accurate, global eventual consistency for cached data.
At a high level, Smart Invalidation automatically detects and calculates when cached data may be stale and removes it from the cache.
Smart Invalidation has several out-of-the-box advantages:
- Performance - Smart Invalidation operates in real-time and invalidates the cache when a change/mutation query is detected. This can quite often mean that the Proxy & Query Processor, where a change has been detected, invalidates the cache, even before the change query has been executed on the origin database.
- Highly scalable - Unlike other caching systems that require access to the Write Ahead Log (WAL) or similar, DBO inspects the wire protocol traffic to drive Smart Invalidations. Hence, an unlimited number of Proxies can be supported without degradation to the origin database.
- 100% automatic - No code or configuration is required to be developed, and any type of workload is supported.
- Global eventual consistency - Smart Invalidation is designed to provide 100% accurate, global eventual consistency for cached data.
Smart Invalidation achieves this through a multi-layer approach. The first layer involves parsing the SQL queries at a row level. It analyzes which rows are read (in the case of read queries) and which rows are written to (in the case of write queries). This analysis is performed on fully anonymized representations of the queries to maintain data security and privacy. From these query details, targeted invalidations of cached data are performed.
The analysis performed by the first layer can sometimes be overwhelmed by complex queries. That is where the second layer of invalidation comes into play. A fallback to a simple but effective table-level invalidation occurs when a query is deemed too complex to determine what specific cached data may have become invalidated. In this case, all cached data coming from any affected tables is invalidated. This layer of invalidation errs on the side of caution, typically overreaching but ensuring stale cache data is not served.
The first two layers of invalidation are very effective. However, they can be thwarted in some circumstances. For example, out-of-band data changes are not visible to DBO or tightly coupled (in time) reads and writes. To address this, a third layer of invalidation exists within the cache automation itself. The automated caching layer monitors for and detects unexplained data changes. If these events are detected, it disables caching on the relevant queries. This provides an empirical safety net for the predictive actions of the first two layers.
Storage Efficiency
The aforementioned layers invalidate entries because it is believed the underlying data has changed. Another layer of invalidation occurs for cache data that is believed to be superfluous. It is an empirical fact that most query results written to the cache will never be served as cache hits. For a cache that sees one million distinct queries daily, perhaps only one hundred thousand will have cache hits. Removing the entries from the cache that will not be needed is an important part of an efficient cache implementation. DBO uses automated machine learning algorithms (specifically, non-homogeneous Poisson process modeling) to eliminate the build-up of never-to-be-used data.
DBO Smart Invalidation provides global eventual consistency through a multi-layered approach that resolves in a few tens of milliseconds.
Performance and Scaling
DBO delivers exceptional performance improvements with minimal resource requirements:
- Fast & Highly Scalable - ~1ms query response times with unlimited concurrency
- Dramatic Latency Reduction - From typical database response times of 850ms potentially down to sub-millisecond per query
- Demand-driven Data Sharding - Provides an unbounded cache that grows as needed
These improvements translate directly to better application performance and reduced infrastructure costs. Many customers see at least 30% cost savings while simultaneously improving system responsiveness.
Database and Cache Permissions
A DBO cache identifies a single server, i.e., a server host. DBO guarantees a unique cache based on a combination of the database name and database user. This means that database and user-level cache uniqueness is guaranteed.
Transactions
DBO currently does not support transactions (does not distinguish between queries within a transaction and not).
Connection Pooling
Coming soon!
Updated 2 months ago