
Fractional GPUs (AWS)
Cast AI supports AWS EC2 G6 instances that provide fractional NVIDIA L4 GPUs, allowing you to provision portions of a GPU for workloads that don't need full GPU capacity. This feature enables significant cost savings while maintaining the GPU acceleration your workloads require.
What are fractional GPUs?
Fractional GPUs give you access to a portion of a physical GPU's compute and memory resources. AWS partitions NVIDIA L4 GPUs creating instances with as little as 1/8th of a GPU (3 GB memory) up to a full GPU.
Unlike time-slicing or MIG, which you configure yourself, fractional GPUs come pre-partitioned from AWS. You simply choose the G6 instance or fractional GPU size that matches your needs, and Cast AI handles the provisioning.
How fractional GPUs differ from other sharing methods
- Pre-configured by AWS - No setup required, just select G6 instance or fractional GPU size
- Dedicated resources - Each fraction gets guaranteed compute and memory
- Appears as a full GPU - Kubernetes sees
nvidia.com/gpu: 1regardless of fraction size - Combines with time-slicing - Further multiply capacity by enabling time-slicing
Configuring fractional GPUs
Enable in your Node template
- Navigate to Node templates in the Cast AI console
- Create a new template or edit an existing one
- Under Instance constraints:
- Set Fractional GPUs to Yes
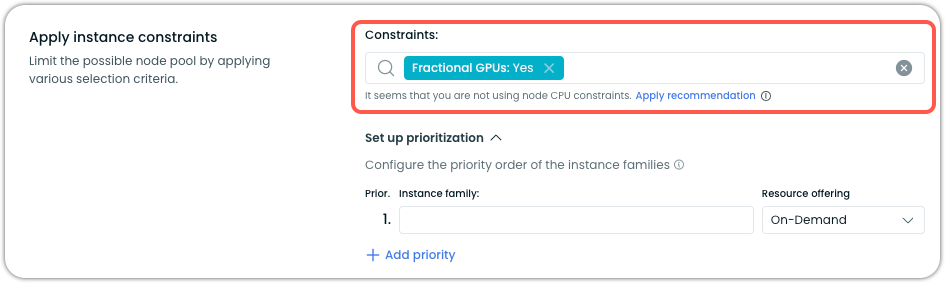
Cast AI will now consider G6 instances with fractional GPUs when provisioning GPU Nodes.
You can optionally further narrow down the selection of instances for provisioning by constraining the pool to G6 instances with fractional GPUs only:
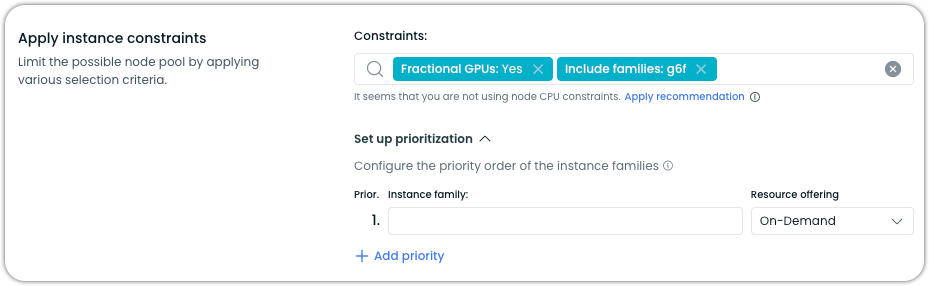
Important configuration details
To ensure fractional GPUs are considered, pay attention to your minimum GPU constraint:
| Min GPU setting | Fractional GPUs setting | Will fractional GPUs be used? |
|---|---|---|
| Not set | Yes | ✅ Yes - fractional GPUs will be considered |
| 0 | Yes | ✅ Yes - fractional GPUs will be considered |
| 1 | Yes | ❌ No - only full GPUs will be used |
| 0 | No | ❌ No - fractional GPUs disabled |
Why does Min GPU = 1 exclude fractional GPUs?Fractional GPUs provide less than one full GPU of resources. Setting Min GPU = 1 tells Cast AI you need at least one complete GPU, which fractional instances cannot provide.
Deploying workloads on fractional GPUs
Let Cast AI choose the best option
For most workloads, request GPU resources and let Cast AI's Autoscaler select the most cost-effective option:
apiVersion: apps/v1
kind: Deployment
metadata:
name: light-inference
spec:
replicas: 3
template:
spec:
containers:
- name: inference-service
image: your-gpu-app
resources:
limits:
nvidia.com/gpu: 1 # Always request 1, even for fractional GPUsWith fractional GPUs enabled in your Node template, Cast AI will automatically consider G6 instances with fractional GPUs and may provision fractional GPUs if they're more cost-effective for your workload.
Target specific fractional GPU sizes
Cast AI exposes the actual fraction size through the scheduling.cast.ai/gpu.count label. Use this to target specific fractional sizes:
Select only 1/8 GPU (3GB memory)
apiVersion: apps/v1
kind: Deployment
metadata:
name: minimal-gpu-workload
spec:
template:
spec:
nodeSelector:
scheduling.cast.ai/gpu.count: "0.125" # 1/8 GPU
containers:
- name: app
resources:
limits:
nvidia.com/gpu: 1Allow multiple fractional sizes
apiVersion: apps/v1
kind: Deployment
metadata:
name: flexible-gpu-workload
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduling.cast.ai/gpu.count
operator: In
values:
- "0.125" # 1/8 GPU (3GB)
- "0.25" # 1/4 GPU (6GB)
- "0.5" # 1/2 GPU (12GB)
containers:
- name: app
resources:
limits:
nvidia.com/gpu: 1Exclude fractional GPUs
For workloads that need full GPU performance, explicitly exclude fractional GPUs:
apiVersion: apps/v1
kind: Deployment
metadata:
name: full-gpu-only
spec:
template:
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduling.cast.ai/gpu.count
operator: NotIn
values:
- "0.125"
- "0.25"
- "0.5"
containers:
- name: training-job
resources:
limits:
nvidia.com/gpu: 1Understanding the labeling system
Fractional GPU nodes have two important labels that may seem contradictory at first:
nvidia.com/gpu.count: '1' # What Kubernetes sees
scheduling.cast.ai/gpu.count: '0.125' # Actual fraction (e.g., 1/8)This dual-labeling system exists because:
- Kubernetes requires integer GPU resources - The NVIDIA device plugin exposes each fractional GPU as
1to satisfy Kubernetes' requirement - You need to know the actual fraction - Cast AI's label shows the true fractional size for scheduling decisions
Always use scheduling.cast.ai/gpu.count when you need to target or identify fractional GPU sizes.
Combining fractional GPUs with time-slicing
For maximum cost savings, consider combining fractional GPUs with time-slicing. This allows multiple workloads to share each fractional GPU.
Example: development environment
Create a Node template with:
- Fractional GPUs: Yes
- GPU time-slicing: Enabled
- Shared clients per GPU: 4
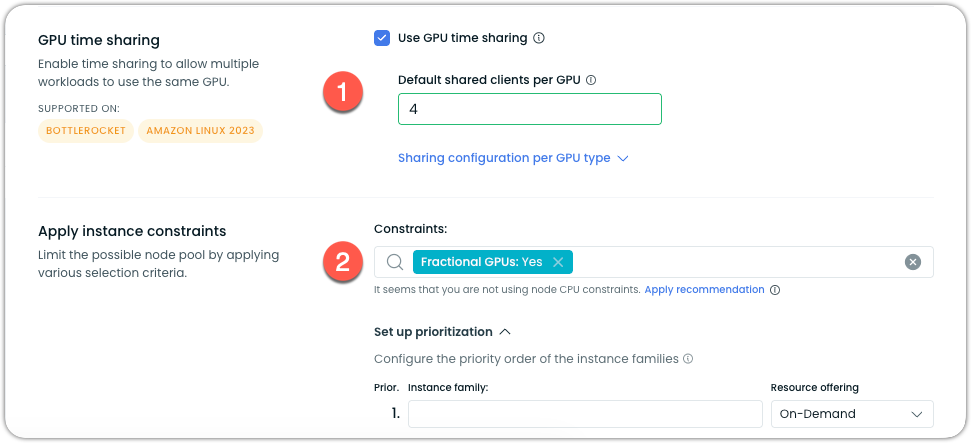
Result: A g6f.large instance (1/8 GPU) can now support 4 concurrent development workloads, each getting time-sliced access to 1/8 of a GPU.
When to use fractional GPUs
Ideal use cases
Development and testing: Developers rarely need a full 24GB L4 GPU for debugging CUDA code or testing model changes. A 3GB or 6GB fraction is perfect for iterative development.
Light inference workloads: Many inference models fit comfortably in 3-6GB of memory and don't fully utilize GPU compute. Fractional GPUs provide the right-sized resources here.
Batch processing: For GPU-accelerated data processing that runs in bursts, fractional GPUs offer cost-effective acceleration without paying for unused capacity.
Multi-tenant SaaS: Provide GPU acceleration to multiple customers without the cost of dedicated full GPUs per tenant.
When to avoid fractional GPUs
Large model training: Training large language models or computer vision models typically requires full utilization of GPU memory and compute resources.
MIG requirements: If you need hardware-level isolation between workloads, use MIG-capable GPUs instead (fractional GPUs don't support MIG).
High memory requirements: Workloads requiring more than 12GB of GPU memory should utilize full GPUs.
Available sizes and specifications
AWS G6 instances provide these fractional GPU options:
| Instance | GPU Fraction | vCPU | GPU Memory |
|---|---|---|---|
| g6f.large | 1/8 (0.125) | 2 | 3 GB |
| g6f.xlarge | 1/8 (0.125) | 4 | 3 GB |
| g6f.2xlarge | 1/4 (0.25) | 8 | 6 GB |
| g6f.4xlarge | 1/2 (0.5) | 16 | 12 GB |
| gr6f.4xlarge | 1/2 (0.5) | 16 | 12 GB |
Platform support
- Cloud Provider: AWS EKS only
- Regions: Check AWS documentation for G6 with fractional GPUs availability
- Node Images: Bottlerocket and Amazon Linux 2023
- GPU Sharing: Time-slicing supported, MIG not available
Limitations and considerations
Kubernetes constraints
Kubernetes requires GPU resources to be integers, which is why fractional GPUs appear as nvidia.com/gpu: 1. This means:
- You always request
1GPU in your Pod spec - The actual fraction is only visible via the
scheduling.cast.ai/gpu.countlabel - GPU resource limits work the same as with full GPUs
Monitoring limitations
Fractional GPUs expose fewer metrics than full GPUs. Only 4 metrics are available compared to 18 for standard GPUs. Plan around having application-level monitoring for detailed insights when using fractional GPUs.
# HELP DCGM_FI_DEV_MEMORY_TEMP Memory temperature for the device.
# TYPE DCGM_FI_DEV_MEMORY_TEMP gauge
DCGM_FI_DEV_MEMORY_TEMP{gpu="0",UUID="GPU-e5de654e-ae57-11f0-92fa-d4c3671e2bf4",pci_bus_id="00000000:31:00.0",device="nvidia0",modelName="NVIDIA L4-3Q",Hostname="ip-192-168-119-184.eu-central-1.compute.internal",container="gpu-test",namespace="default",pod="gpu-test-685ff6d954-5jdfh"} 0
# HELP DCGM_FI_DEV_FB_TOTAL Total Frame Buffer of the GPU in MB.
# TYPE DCGM_FI_DEV_FB_TOTAL gauge
DCGM_FI_DEV_FB_TOTAL{gpu="0",UUID="GPU-e5de654e-ae57-11f0-92fa-d4c3671e2bf4",pci_bus_id="00000000:31:00.0",device="nvidia0",modelName="NVIDIA L4-3Q",Hostname="ip-192-168-119-184.eu-central-1.compute.internal",container="gpu-test",namespace="default",pod="gpu-test-685ff6d954-5jdfh"} 3072
# HELP DCGM_FI_DEV_FB_FREE Framebuffer memory free (in MiB).
# TYPE DCGM_FI_DEV_FB_FREE gauge
DCGM_FI_DEV_FB_FREE{gpu="0",UUID="GPU-e5de654e-ae57-11f0-92fa-d4c3671e2bf4",pci_bus_id="00000000:31:00.0",device="nvidia0",modelName="NVIDIA L4-3Q",Hostname="ip-192-168-119-184.eu-central-1.compute.internal",container="gpu-test",namespace="default",pod="gpu-test-685ff6d954-5jdfh"} 2418
# HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB).
# TYPE DCGM_FI_DEV_FB_USED gauge
DCGM_FI_DEV_FB_USED{gpu="0",UUID="GPU-e5de654e-ae57-11f0-92fa-d4c3671e2bf4",pci_bus_id="00000000:31:00.0",device="nvidia0",modelName="NVIDIA L4-3Q",Hostname="ip-192-168-119-184.eu-central-1.compute.internal",container="gpu-test",namespace="default",pod="gpu-test-685ff6d954-5jdfh"} 0For more information on DCGM metrics, see GPU metrics exporter.
Troubleshooting
Workloads not scheduling on fractional GPUs
Check your Node template configuration:
- Ensure Fractional GPUs is set to Yes
- Verify Min GPU is set to 0 or not set
- Confirm G6 instances with fractional GPUs are available in your AWS region
OutOfMemory errors on fractional GPUs
OutOfMemory errors on fractional GPUsYour workload needs more GPU memory:
- Target larger fractions using
nodeSelector:nodeSelector: scheduling.cast.ai/gpu.count: "0.5" # 12GB instead of 3GB - Or switch to full GPUs by excluding fractional sizes
Identifying fractional GPU Nodes
Query Nodes by their fractional label:
kubectl get nodes -l 'scheduling.cast.ai/gpu.count in (0.125,0.25,0.5)'This shows all Nodes with fractional GPUs in your cluster.