
March 2025
Advanced Rebalancing Controls, Cluster Hibernation, and Improved Workload Optimization
Major Features and Improvements
Cluster Hibernation with Automated Scheduling
Say hello to our new Cluster Hibernation feature, which is a complete redesign of our previous cluster pausing capability. This solution allows you to optimize costs by temporarily scaling your cluster to zero nodes while preserving the control plane and cluster state.
Key features:
- Organization-level schedules for automatic hibernation and resumption
- API-driven implementation with improved reliability and consistency
- Support for all major cloud providers
Cluster hibernation is particularly valuable for non-production environments, development clusters, and any infrastructure that doesn't need to run 24/7. The system intelligently manages the hibernation process by removing nodes systematically while preserving essential functionality.
For detailed configuration instructions and API documentation, see our Cluster Hibernation documentation.
Optimization and Cost Management
Advanced Rebalancing Control Options
Enhanced rebalancing configuration offers more granular control options, allowing you to precisely define which problematic pods can be evicted during rebalancing operations.
Key features:
- Independent configuration for pods without controllers, job pods, and pods with removal-disabled annotations
- Available for both manual and scheduled rebalancing operations
- Supported in API and Terraform
This allows you to create more nuanced rebalancing strategies according to your workload requirements. For example, you can now safely rebalance clusters containing sensitive workloads by protecting them while allowing other problematic pods to be evicted.
For detailed information about configuring advanced rebalancing options, see our Cluster Rebalancing documentation.
Rebalancing with Workload Autoscaler Recommendations
Taking cluster optimization to the next level, a new capability integrates Workload Autoscaler recommendations directly into rebalancing. This feature creates a more comprehensive approach to optimization by considering both node-level and workload-level resource requirements simultaneously.
Key benefits:
- Greater cost savings by optimizing nodes based on actual workload requirements
- More efficient node provisioning based on pending workload optimizations
This approach ensures that when rebalancing plans are created, the system considers traditional node optimization factors and the latest deferred resource recommendations from the Workload Autoscaler. The result is better resource alignment and more effective cost optimization across your cluster.
For optimal results, we recommend using Workload Autoscaler version v0.31.0 or higher. This feature is currently available through our feature flag system—contact our support team to enable it.
For more information about optimizing your clusters, see our Cluster Rebalancing documentation.
Busy Workload Redistribution (Early Access)
Tackling CPU resource congestion becomes easier with Busy Workload Redistribution, a new feature designed to identify and address overloaded nodes. This capability redistributes pods from overloaded nodes to less utilized ones, creating more balanced resource utilization across your infrastructure.
Key features:
- Automatic detection of overloaded nodes using CPU utilization metrics
- Intelligent workload movement with Pod Pinner integration for optimal placement
Busy Workload Redistribution works best with Pod Pinner enabled and complements our existing optimization features like the Workload Autoscaler.
NoteThe feature is currently in early access and available upon request. Contact our support team for more information about enabling this capability in your environment.
Workload Optimization
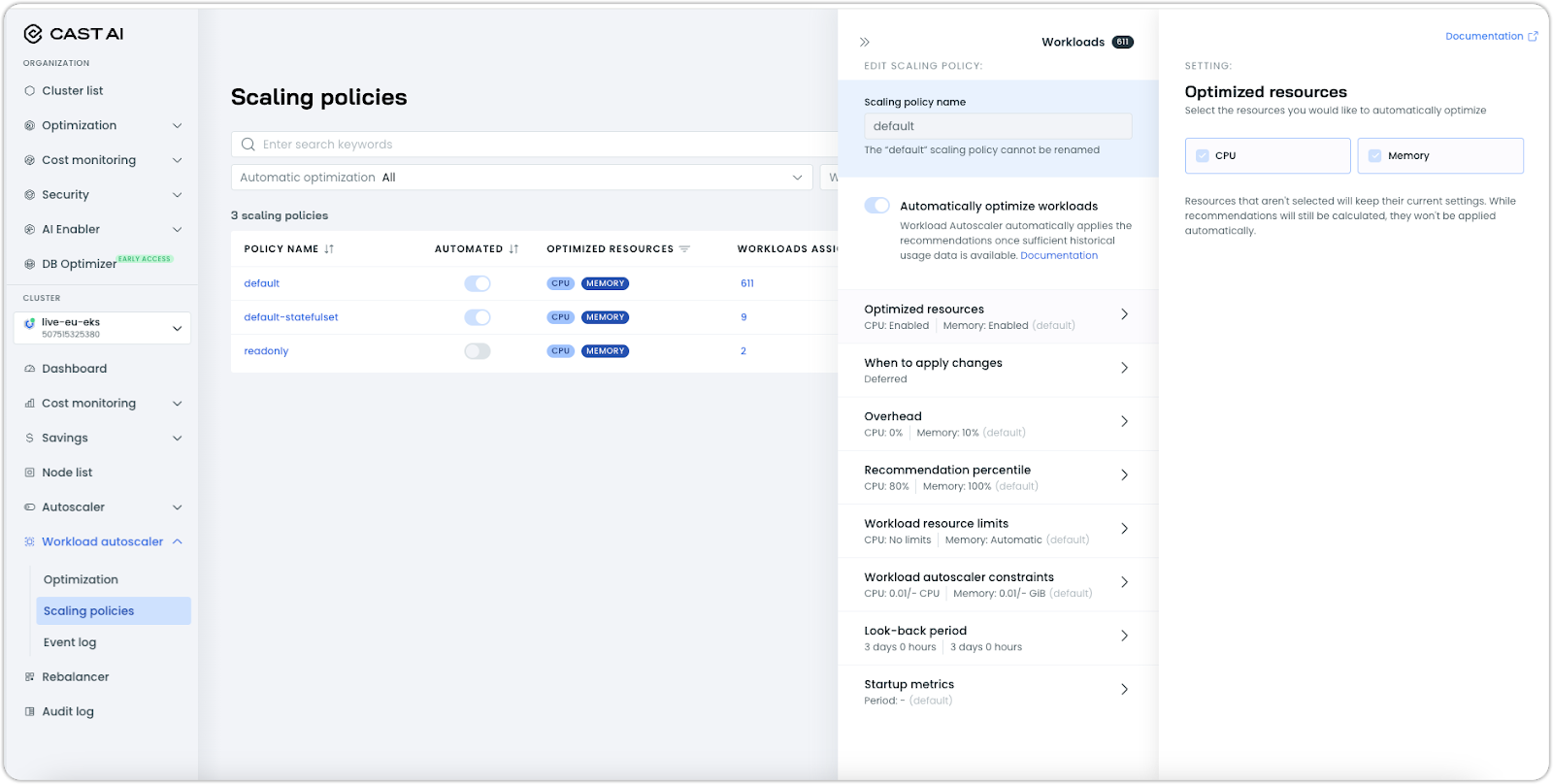
Redesigned Workload Autoscaler Policy Management
A complete overhaul of the Workload Autoscaler policy interface brings a more intuitive and organized structure. This redesign makes managing scaling policies significantly easier while introducing several highly requested features to the UI.
Key improvements:
- Dedicated scaling policies page for better visibility and management
- Interactive feature simulation charts to visualize the impact of configuration changes
- Direct UI access to workload limits settings without requiring annotations or API
This redesign transforms the policy management experience into a more structured, accessible interface. The new layout makes it easier to understand, configure, and maintain optimization policies across your organization.
For guidance on using workload autoscaling for your organization, see our Workload Autoscaler documentation.
ReplicaSet Support in Workload Autoscaler
Expanded capabilities now bring ReplicaSet resource optimization to the Workload Autoscaler. This addition extends the benefits of our Vertical Pod Autoscaler to a broader range of workload types.
Key features:
- Full support for ReplicaSets in both immediate and deferred scaling modes
- Compatible with native Kubernetes HPAs for horizontal scaling
- VPA correction functions properly on ReplicaSets managed by native HPAs
This provides greater flexibility for optimizing resource allocation across different Kubernetes resource types.
To use this feature, upgrade to Workload Autoscaler version v0.32.0 or higher. For instructions on how to do so, see our Workload Autoscaling documentation.
Container Grouping for Dynamic Workloads
Managing dynamic workloads gets easier with new container grouping support in the Workload Autoscaler. This feature makes it possible to optimize workloads that dynamically create containers with similar naming patterns, which is particularly useful for batch jobs, CI/CD pipelines, and platforms like Tekton that generate containers with auto-generated names.
Key features:
- Group dynamically created containers with similar naming patterns into a single logical container in the eyes of the Workload Autoscaler
- Maintain stable usage metrics for workloads with ephemeral containers
With container grouping, workloads that previously presented optimization challenges due to constantly changing container names can now be effectively monitored and optimized. The feature uses a flexible matching system that allows you to define grouping rules based on naming patterns.
This feature is available in Workload Autoscaler v0.33.0 and later. For configuration details and examples, see our Workload Autoscaling Configuration documentation.
High Availability for Workload Autoscaler
Reliability gets a boost with multi-replica support for the Workload Autoscaler. The component now supports running multiple replicas with leader election, ensuring continuous operation even during pod failures or maintenance events.
The leader election mechanism ensures that reconciliation tasks run on only one pod at a time, maintaining consistency while improving resilience.
To update your Workload Autoscaler to the latest version with these improvements (introduced in v0.30.0), follow our Workload Autoscaler upgrade documentation.
Cloud Provider Integrations
Public IP Support for AKS Nodes
Direct internet connectivity arrives for Azure Kubernetes Service (AKS) nodes with new support for public IPs. This enhancement allows you to configure instance-level public IP addresses for your AKS clusters when required by your architecture or compliance needs.
The implementation transfers your public IP configuration settings to the underlying Azure Virtual Machine Scale Sets (VMSS).
For detailed node configuration options, see our AKS Node Configuration documentation.
Unified Commitment Upload Process for All Cloud Providers
Standardized commitment management is now available across all supported cloud providers. This is transitioning from the previous CSV-based approach for Azure to a more robust script-based solution, creating consistency with our existing AWS and GCP commitment import processes.
The new script-based approach for Azure RI commitments resolves the persistent challenges that customers faced with the previous CSV upload method, including format inconsistencies and size constraints.
Security and Compliance
Improved Cloud Access Model for GCP and Azure
We've implemented a more secure access model for GCP and Azure customer resources, eliminating the need for long-lived service account keys. The new model uses identity impersonation with short-lived credentials to improve security while maintaining seamless integration with customer cloud environments.
Key improvements:
- Elimination of long-lived service account keys for GCP access
- Implementation of federated credentials for Azure Entra ID applications (formerly Azure Active Directory)
This implementation creates a more robust security architecture that aligns with cloud provider best practices for service authentication.
NoteTo migrate to this new credential flow, please contact our Customer Support team. The migration requires coordination with our team to ensure a smooth transition to the new access model.
Node Configuration
Improved Instance Family Selection for AWS
Automatic optimization of AWS instance selection now prioritizes newer instance families when creating nodes. This improvement selects newer generation instances (like r6a over r5a) that offer better performance at similar price points.
This is applied automatically to all AWS clusters and requires no configuration changes.
AI Enabler
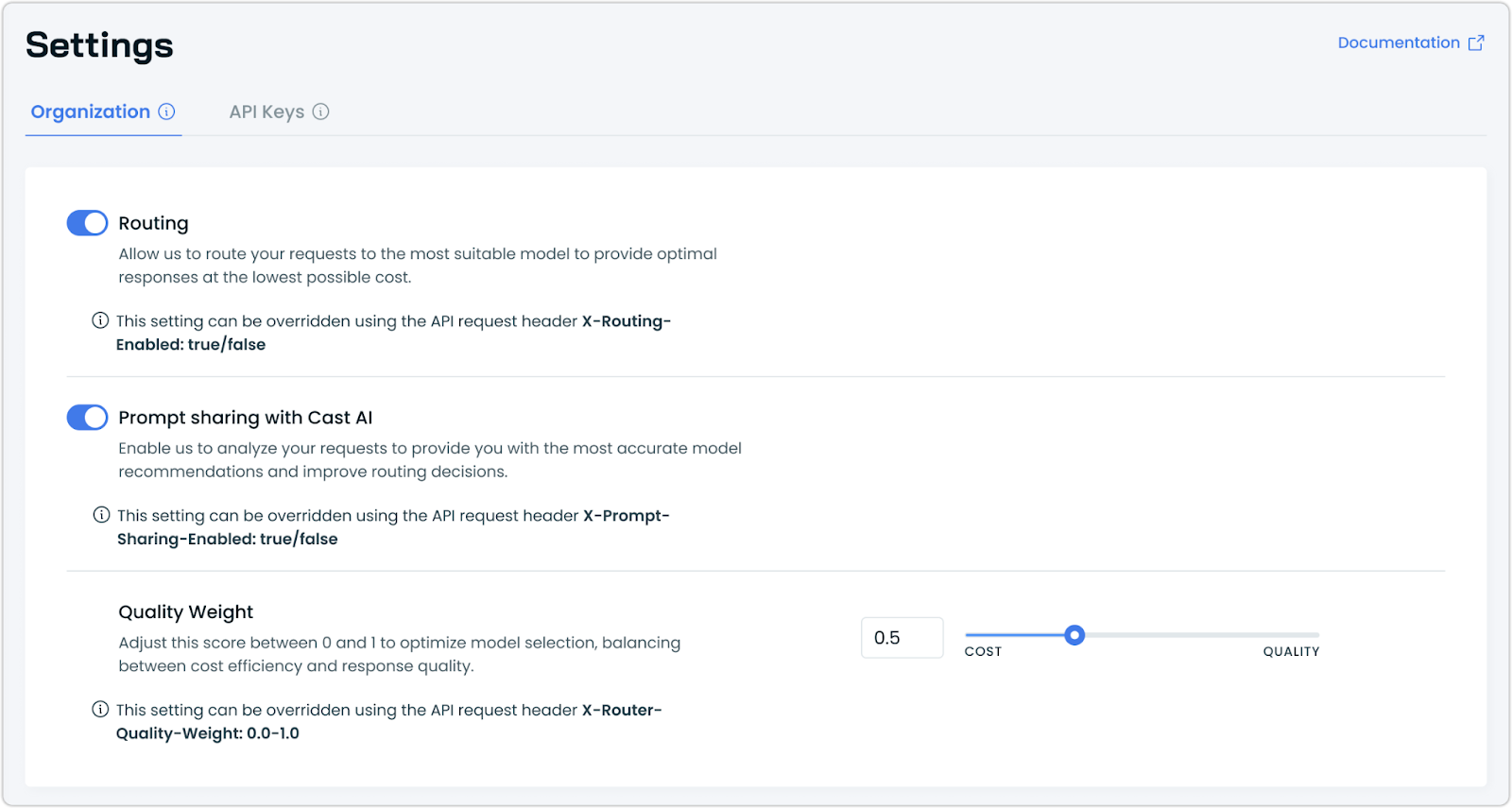
New AI Enabler Settings Page
Managing LLM routing becomes more intuitive with a dedicated Settings page for the AI Enabler. Previously only accessible through the API, these settings are now available in an intuitive interface.
Key features:
- Toggle routing on/off to control whether requests are routed to the most suitable model
- Manage prompt sharing preferences to balance privacy with optimization capabilities
- Adjust quality weight with a slider to find your ideal balance between cost efficiency and response quality
These settings apply organization-wide but can be temporarily overridden using API request headers for specific use cases. The interface is role-aware, with settings appearing disabled for users without Owner or Member roles.
For more information about optimizing your LLM usage with the AI Enabler, see our AI Enabler documentation.
vLLM Support for Self-Hosted Model Deployments
Deployment flexibility expands with vLLM support for self-hosted models alongside our existing Ollama integration. This addition gives you more options for how you deploy and run large language models within your Kubernetes infrastructure.
Key features:
- Support for vLLM as an alternative runtime to Ollama
- Direct deployment of models from Hugging Face Hub
- Significantly faster inference speeds for improved response times
vLLM offers substantial performance advantages through optimized attention mechanisms and memory management, resulting in higher throughput and lower latency compared to Ollama. This makes it particularly valuable for environments where performance is critical.
When deploying models, you can now choose between Ollama and vLLM based on your specific requirements for performance, compatibility, and resource efficiency.
User Interface Improvements
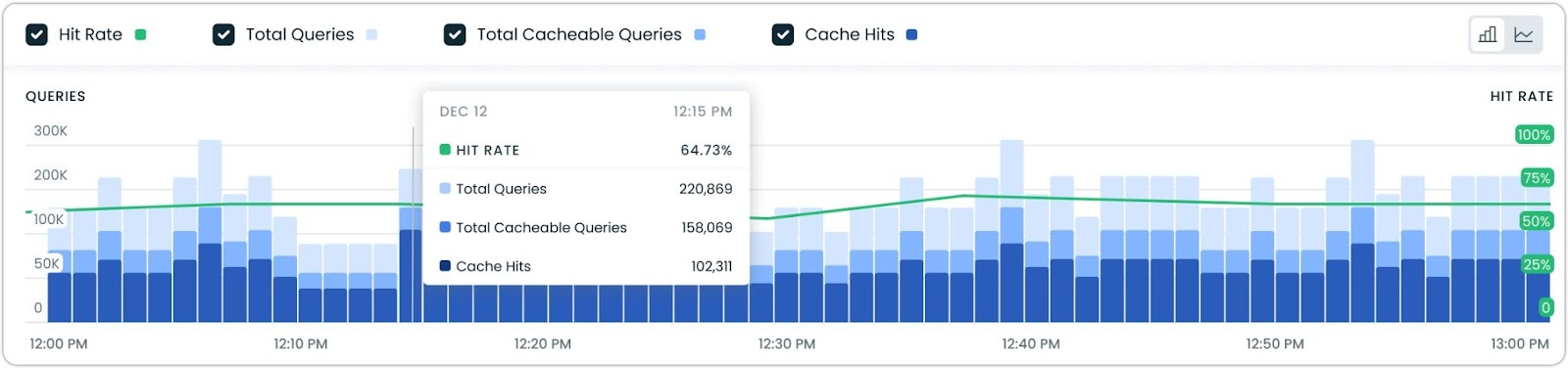
Granular Metrics for Database Optimizer
Gain deeper insights into database performance with granular metrics visualization and flexible time range filtering for the Database Optimizer (DBO). This enhancement provides detailed visibility into your database's cache performance across different timeframes.
Key features:
- Customizable time range selection (6h/24h/7days)
- Detailed performance graphs showing hit rate, total queries, and cache statistics
- Interactive visualization with detailed metrics at specific points
This helps users better understand caching patterns and optimize database performance by examining metrics at different time scales. The new visualization makes it easier to identify trends, spot anomalies, and make data-driven decisions about your database configuration.
AWS Reserved Instance Support in Console
Commitment management for AWS becomes seamless with direct console access to Reserved Instance management. This enhancement provides parity with our existing GCP and Azure commitment management interfaces.
Key features:
- Upload and view AWS Reserved Instance commitments directly in the UI
- Visual tracking of commitment utilization and effectiveness
- Streamlined assignment of commitments to clusters
This improvement creates a consistent commitment management experience across all supported cloud providers, eliminating the need to use different tools for different environments.
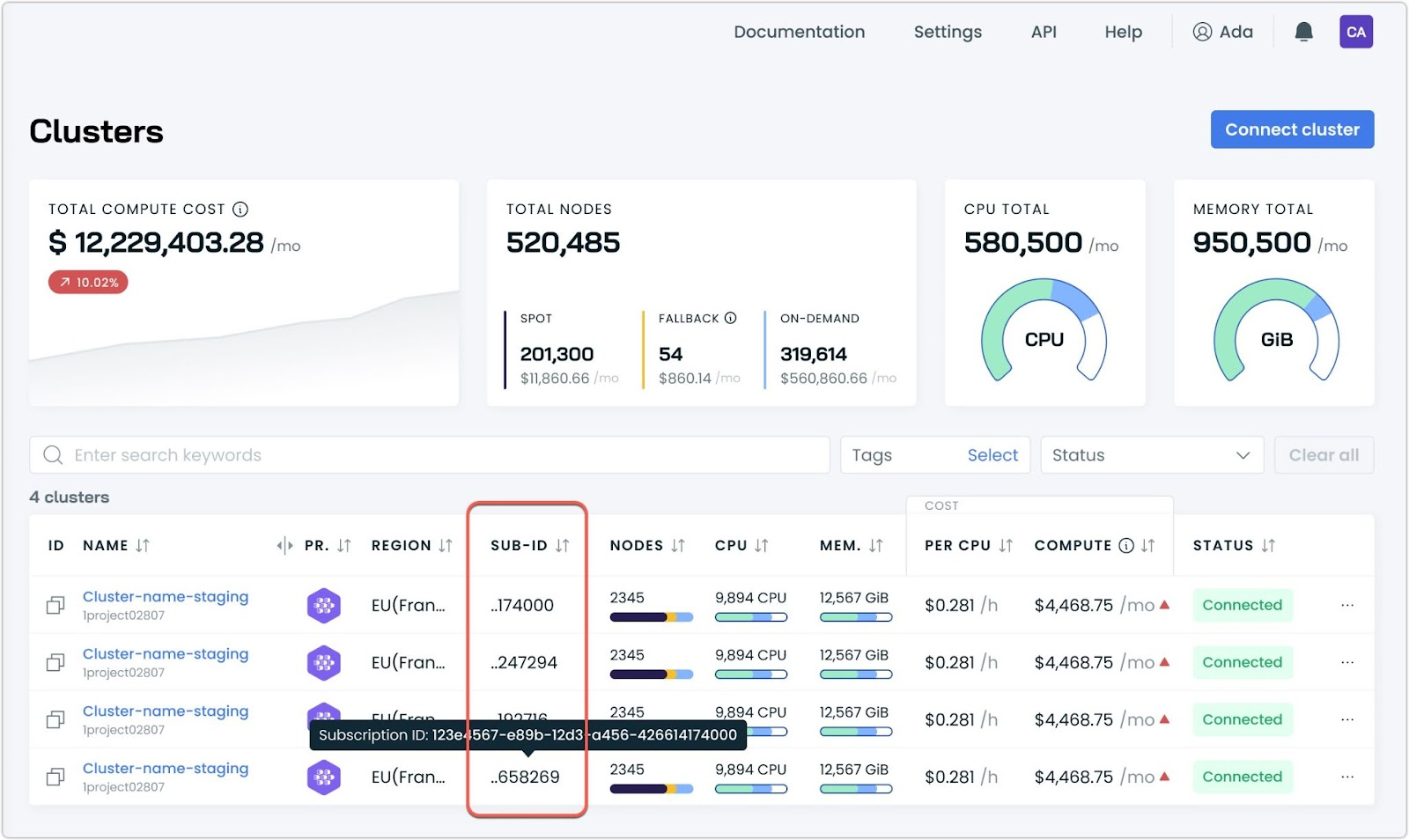
Subscription ID Column for AKS Clusters
Multi-subscription Azure environments benefit from a new Subscription ID column in the cluster list view. This enhancement makes it easier to identify and manage Azure Kubernetes Service (AKS) clusters across multiple subscriptions, developed based on customer feedback to improve navigation.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.