
October 2024
AI Enabler Playground, Improved Workload Autoscaling, and AWS Storage Reporting
Major Features and Improvements
AI Enabler Playground Console (Alpha)
We've introduced a new Playground Console that demonstrates the AI Enabler's routing capabilities in real time. This interactive environment allows you to explore and understand the router's decision-making process through hands-on experimentation.
Key features:
- Set up comparison scenarios with specific provider/model combinations
- Test routing behavior with custom system and user prompts
- Visualize routing decisions through an interactive decision tree
- Compare responses across different providers and models
- Configure and tune routing parameters
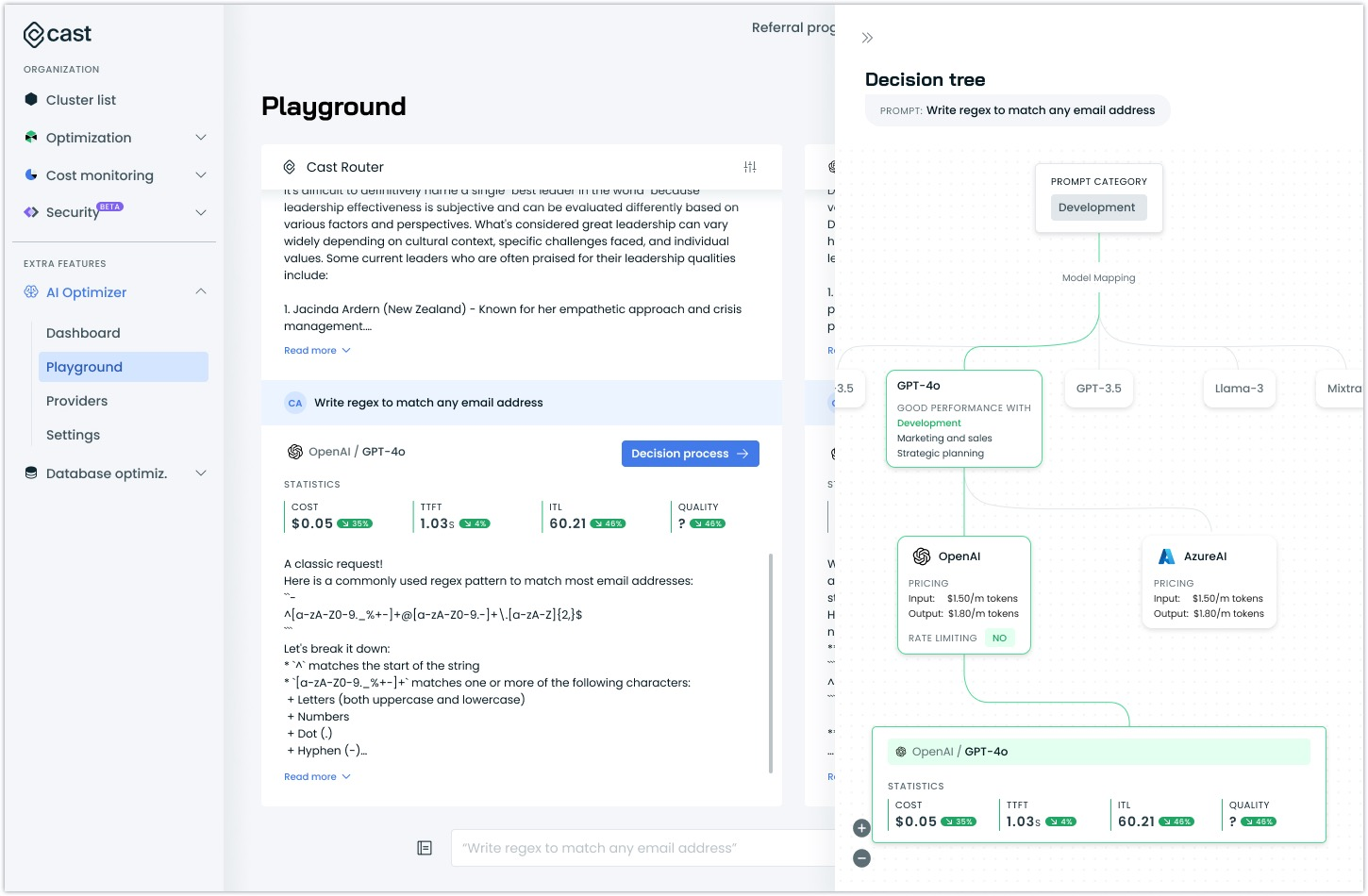
The Playground is currently in Alpha and available for exploration. To begin experimenting, head on over to the AI Enabler console.
Optimization and Cost Management
Enhanced Cost-Based Rebalancing Algorithm
We've updated our "Highest Requested Resource Price" rebalancing algorithm to consider both CPU and memory costs when making rebalancing decisions. The algorithm now uses a CPU:RAM ratio of 1:7 GiB, providing better optimization for memory-intensive workloads.
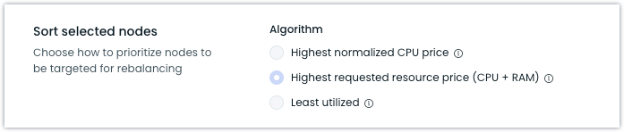
For more information about our rebalancing strategies, see our Cluster Rebalancing documentation.
Enhanced StatefulSet Protection in Evictor
We've improved how the Evictor handles StatefulSets by adding replica count awareness to pod targeting rules. In non-aggressive mode, the Evictor now respects minimum replica requirements, providing better protection for single-replica StatefulSets.
New configuration option:
podSelector:
kind: StatefulSet
replicasMin: 2This helps prevent unintended downtime for critical StatefulSet workloads while maintaining parity with deployment handling. The default behavior preserves backward compatibility with the new controls available through advanced configuration.
For detailed configuration options, see our Evictor documentation.
Immediate OOM Event Response in Workload Autoscaler
We've enhanced our Workload Autoscaler's handling of Out-of-Memory (OOM) events by introducing the ability to apply memory recommendations immediately, even when deferred scaling is configured. This improvement ensures faster recovery for pods experiencing memory issues, preventing extended periods of crash-looping.
This behavior can be configured at both the workload level and scaling policy level using the workloads.cast.ai/memory-event-apply-type annotation or through our Terraform provider (v7.18.0+).
For configuration details and best practices, see our Workload Autoscaling Configuration documentation.
AWS Storage Cost Support
We've expanded our storage cost reporting to include AWS storage volumes. The platform now tracks and reports provisioned storage costs for AWS EBS volumes, providing a more complete view of storage expenses across cloud providers.
This addition brings feature parity with existing storage cost reporting capabilities for GCP.
For more information on storage cost reporting, see our Storage cost monitoring documentation.
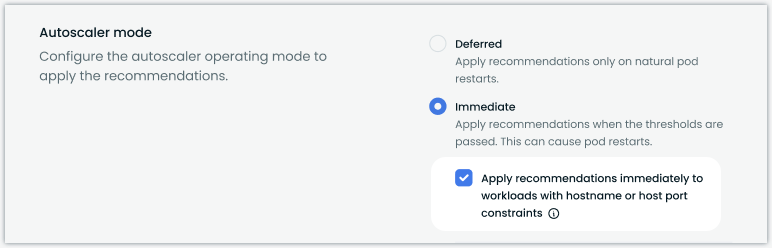
Configurable Anti-Affinity Handling in Workload Autoscaler
We've added the ability to override default anti-affinity handling in the Workload Autoscaler. This new setting allows immediate mode scaling to proceed even when workloads have hostname anti-affinity rules configured or require a specific hostPort.
The setting can be configured at both policy and workload levels. For configuration details, see our Workload Autoscaling documentation.
Node Configuration
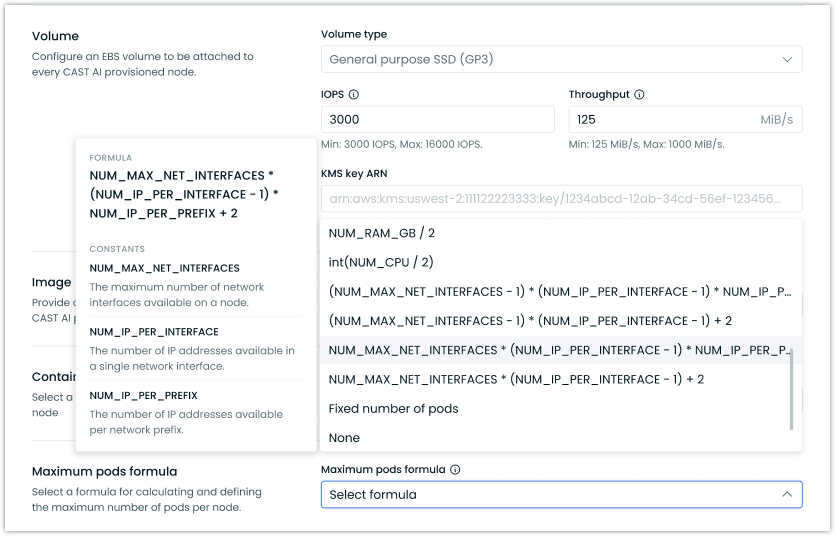
Maximum Pods per Node Configuration for EKS
The team has been working hard to introduce the ability to define the maximum number of pods allowed per AWS node in EKS clusters. This feature supports various Container Network Interface (CNI) configurations by allowing selection from predefined formulas or specification of custom calculations.
Key benefits:
- Supports clusters with non-default CNI configurations
- Enables precise control over pod density on nodes
- Provides flexibility through both UI selection and Terraform configuration
The feature is available through our Terraform provider and console UI. For more information on configuring maximum pods per node, see our EKS Node Configuration documentation.
Resource Scheduling and Constraints
Enhanced Topology Spread Support for Hostname Labels
We've added support for Topology Spread Constraints (TSC) on hostname labels, providing more flexible pod distribution across nodes than traditional pod anti-affinity rules. This enhancement allows for more nuanced pod placement strategies while maintaining efficient resource utilization.
The new capability works with the ScheduleAnyway parameter, enabling pods to be co-located when necessary while optimizing for spread across available nodes. Our autoscaler now recognizes these constraints when making node provisioning decisions.
For guidance on implementing topology spread constraints with CAST AI, see our Pod Placement documentation.
CPU Manufacturer Constraints for Node Templates
We've added CPU manufacturer as a new constraint option when configuring node templates. This allows you to ensure that any nodes provisioned using the template will use instances with specific CPU manufacturers (such as AMD or Intel).
AI Enabler
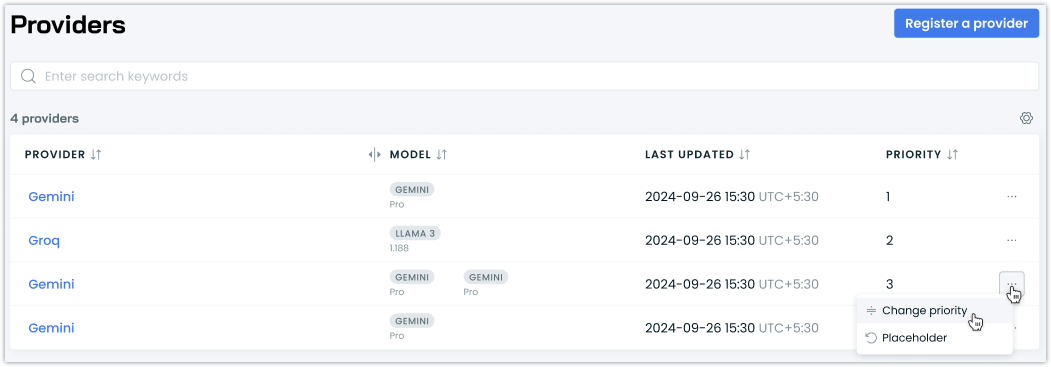
Configurable Provider Routing Priority
We've added the ability to customize the routing order of LLM providers in the AI Enabler. This new feature allows you to set and manage provider priorities through an intuitive drag-and-drop interface.
The Providers page now includes a Priority column that displays the current routing order, which you can modify using the new Change Priority function. Changes to the priority order are reflected immediately in the interface and saved with a single click.
Security and Compliance
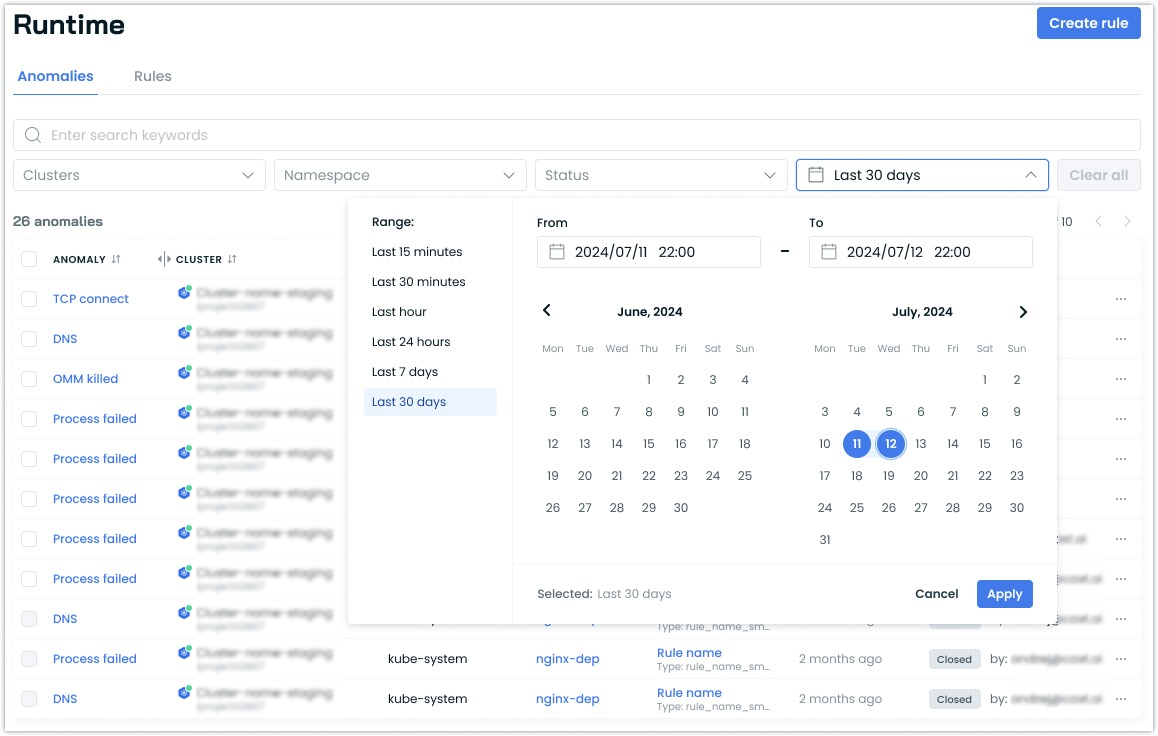
Enhanced Runtime Security Event Filtering
We've added date range filtering to the Runtime Security anomalies view, allowing for more precise historical analysis of security events. Users can now specify custom date ranges beyond the standard presets, making it easier to investigate security incidents and patterns over time.
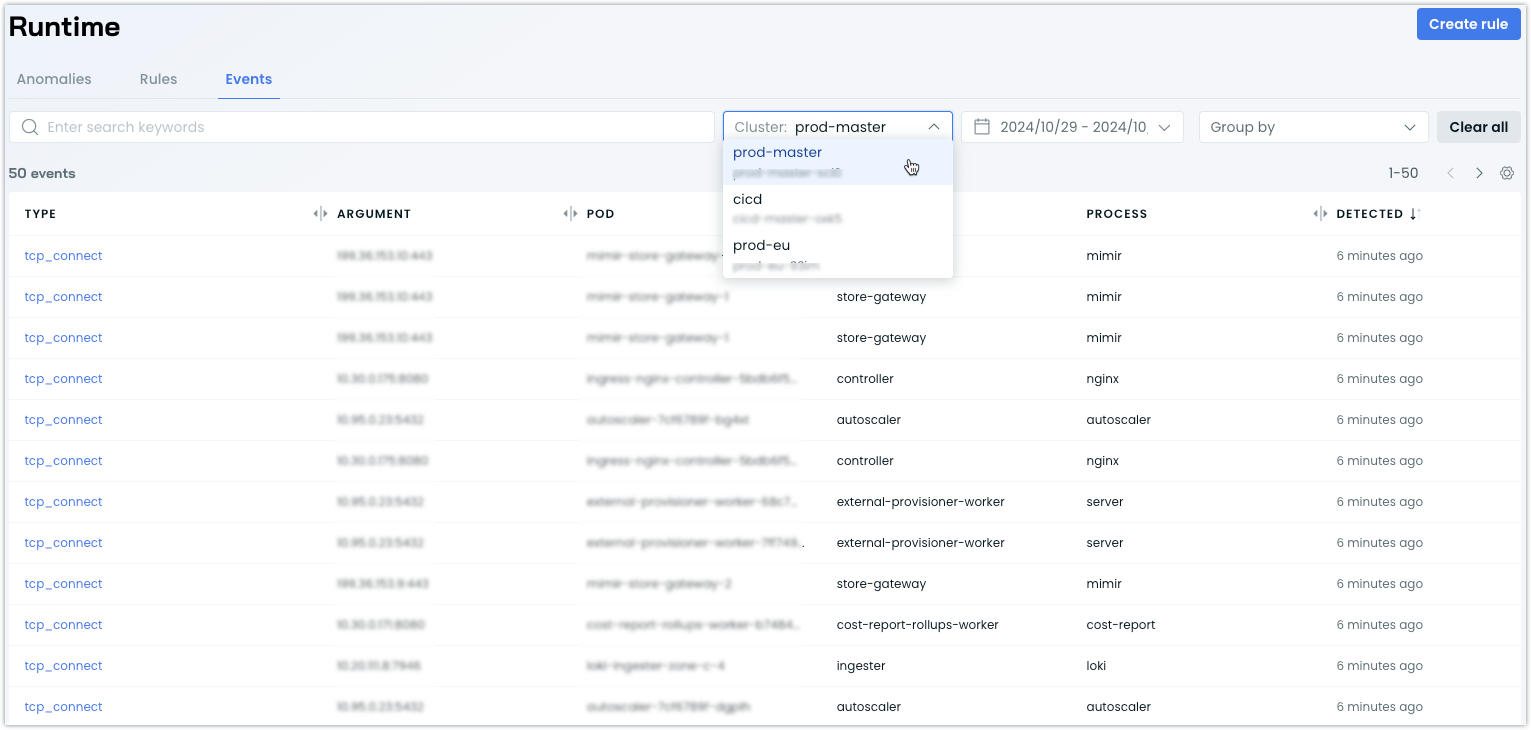
Cluster Filter for Runtime Security Events
We've added a cluster selection dropdown to the Runtime Security events view, allowing you to filter events for a specific cluster. This change improves query performance and provides more focused security event monitoring.
API and Metrics Improvements
Expanded Audit Logging for Node Templates
We've expanded our audit logging capabilities to include node template operations and commitment assignment events at the cluster level. This update provides better visibility into changes made to your cluster's configurations.
Key features:
- Audit log events for node template creation, updates, and deletions
- The audit log now captures detailed information about commitment assignments and removals.
User Interface Improvements
Enhanced Status Indicators Across the Platform
We've updated the visual design of status indicators throughout the platform to improve visibility and better reflect their meaning: Audit log status chips have been redesigned for better readability within expandable table rows The node list "Not Ready" status indicators now use yellow (cautionary) instead of red (negative) to better reflect their temporary state. These visual improvements help provide clearer and more intuitive status information across the platform.
Multiple Cluster List Sorting
We've improved the cluster list by adding multi-column sorting capabilities, including new sorting options for cluster names.

Improved Jira Integration Experience
We've made several improvements to our Jira integration within the Kubernetes Security product based on user feedback:
- Added the ability to view and edit integration details after initial setup
- Introduced project-specific ticket creation for better team workflow alignment
- Extended Jira ticket creation functionality to additional areas, including attack path details and anomaly details pages
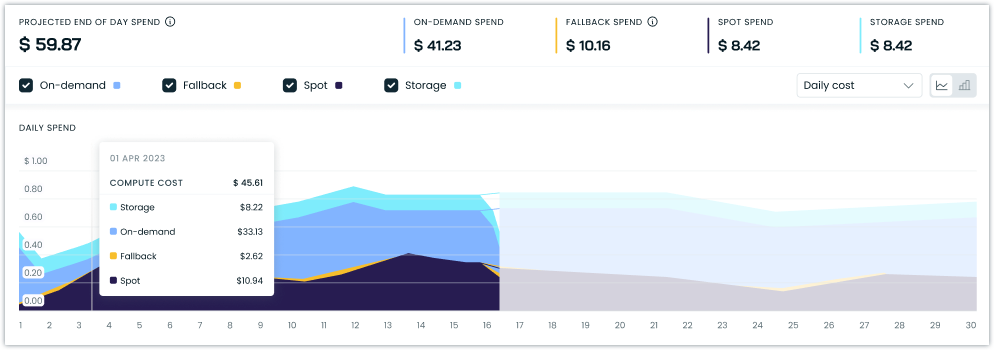
Distinct Storage Cost Visualization
We've updated our cost reporting visualizations to display storage costs in a distinct color, separating them from on-demand compute costs. This change provides clearer visibility into your cost breakdown across cluster reports, workload reports, and namespace reports.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the CAST AI agent. The complete list of changes is here.