
September 2024
Pod Pinner Release, Enhanced Runtime Security, and New Workload Autoscaler Features
Major Features and Improvements
Pod Pinner: General Availability Release
We're excited to announce that Pod Pinner has graduated from beta and is now generally available. This CAST AI in-cluster component enhances the alignment between CAST AI Autoscaler decisions and actual pod placement, leading to improved resource utilization and potential cost savings.
Pod Pinner is enabled by default for eligible clusters. Some customers may not see this feature immediately; if you're interested in using Pod Pinner, please contact our support team for activation.
For detailed installation instructions, configuration options, and best practices, refer to our Pod Pinner documentation.

Custom Lists for Runtime Security
We've enhanced our Runtime Security capabilities with configurable custom lists. This flexible feature lets you create and manage lists of elements like IP addresses, process names, or file hashes that you can reference in your security rules.
Key features:
- Create and manage custom lists via API
- Integrate lists into security rules using CEL expressions
- Support for various entry types, including IPv4, SHA256 hashes, and process names
New API endpoints:
- Create a list:
POST /v1/security/runtime/list - Retrieve all lists:
GET /v1/security/runtime/list - Get a specific list:
GET /v1/security/runtime/list/{id} - Add items to a list:
POST /v1/security/runtime/list/{id}/add - Remove items from a list:
POST /v1/security/runtime/list/{id}/remove - Get entries of a list:
GET /v1/security/runtime/list/{id}/entries - Delete a list:
POST /v1/security/runtime/list/delete
This addition provides greater flexibility in defining and enforcing security policies in your Kubernetes environment. For usage details and examples, refer to our Runtime Security documentation.
Cloud Provider Integrations
GPU Support for AKS Clusters (Preview)
Our GPU support expanded to include Azure Kubernetes Service (AKS) clusters, bringing feature parity across major cloud providers. This addition allows for autoscaling of GPU-attached nodes in AKS environments.
Key features:
- Support for NVIDIA GPUs in AKS clusters
- Autoscaling capabilities for workloads requesting GPU resources
- Integration with default and custom node templates
- Updated Terraform modules to support GPU configurations in AKS
This feature is currently in preview and available upon request. If you're interested in using GPU support for your AKS clusters, please contact our support team for enablement.
For more information on GPU support across cloud providers, see our GPU documentation.
Optimization and Cost Management
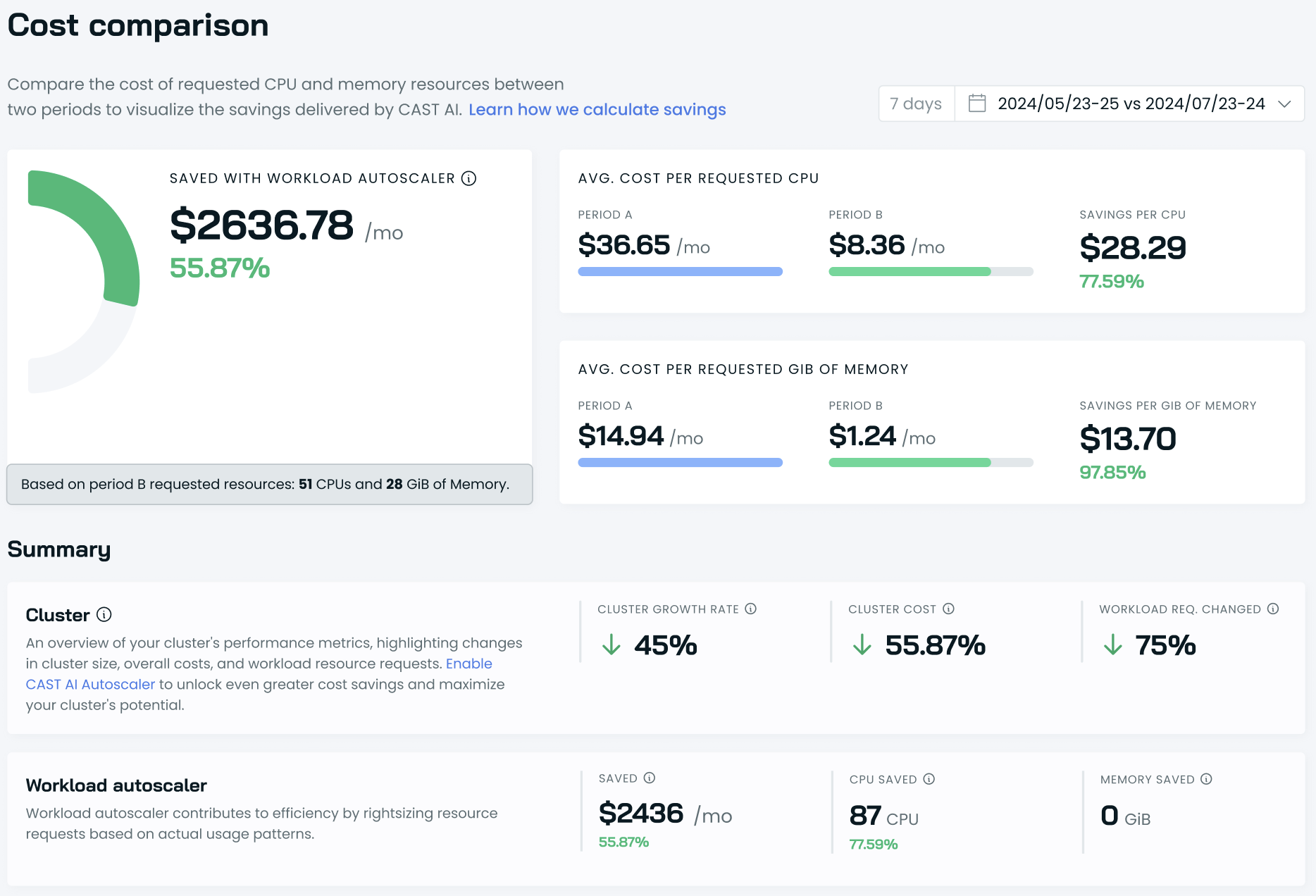
Cost Comparison Report Overhaul
We've significantly improved our cost comparison reports, providing deeper visibility into your Kubernetes spending over time. This overhaul includes several new features:
- Memory dimension added alongside CPU metrics for a more comprehensive resource analysis
- Workload analysis showing Workload Autoscaler impact, helping you understand cost optimizations
- Growth rate insights for cluster costs vs. size, allowing you to track cost efficiency as your cluster grows
These enhancements will help you gain more detailed insights into your Kubernetes spending patterns and optimization opportunities.
For more information on using these new features, please refer to our Cost Comparison Report documentation.
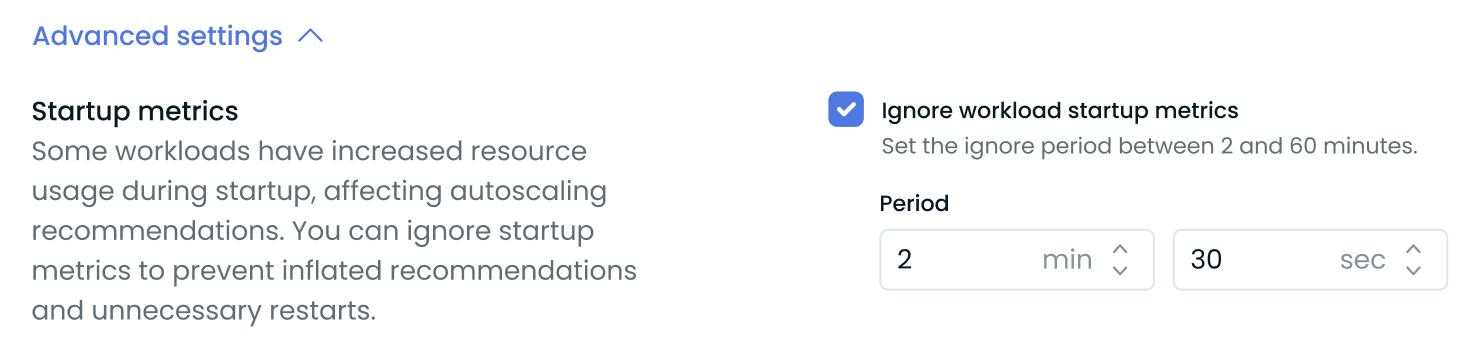
Workload Startup Ignore Period: Full Feature Availability
The feature to ignore initial resource usage during workload startup is now fully available across our platform. This enhancement is particularly beneficial for applications with high initial resource demands, such as Java applications.
Users can now configure scaling policies to disregard resource metrics for a specified period after startup, ensuring more accurate autoscaling decisions. This feature is accessible via:
- CAST AI Console
- Terraform
- API
For details on implementation and best practices, please refer to our Workload Autoscaler documentation.
Custom Look-back Period for Workload Autoscaler
We've enhanced our Workload Autoscaler with a custom look-back period feature. This allows you to specify the historical timeframe the autoscaler uses when analyzing resource usage and generating scaling recommendations.
Key points:
- Set custom look-back periods for CPU and memory separately
- Available through the Annotations, API, and Terraform, with UI coming soon
This feature provides greater flexibility in optimizing your autoscaling policies to match your specific application needs and usage patterns. For more details on configuring custom lookback periods, see our Workload Autoscaler documentation.

Enhanced Cluster Efficiency Reporting
We've improved the granularity of our cluster efficiency reports by reducing the minimum time step from 1 day to 1 hour. This change affects the /v1/cost-reports/clusters/{clusterId}/efficiency API endpoint.
Key benefits:
- More accurate representation of cluster efficiency over time
- Better alignment between efficiency reports and dashboard data
- Improved visibility for clusters with frequent resource changes
For more details on using the efficiency report API, see our Cost Reports API documentation.
Node Configuration
Improved EKS Node Configuration with Instance Profile ARN Suggestions
We've enhanced the EKS node configuration experience by adding suggestions for Instance Profile ARNs. This feature simplifies the setup of CAST AI-provisioned nodes in your EKS clusters.
Key benefits:
- Automated suggestions for Instance Profile ARNs
- Reduced need to switch between CAST AI and AWS consoles

Added Ability to Define MaxPods per Node Using Custom Formula
We've enhanced the EKS node configuration to allow users to select a formula for calculating the maximum number of pods per specific AWS EC2 node.
Key benefits:
- Supports customer configurations with various Container Network Interfaces (CNIs)
- Allows for non-default max pods per node, providing greater flexibility in cluster management
- Enables more precise control over pod density on nodes
This feature enhances CAST AI's ability to adapt to diverse customer environments and networking setups. For more information on using this feature, please refer to our EKS Node Configuration documentation.

Security and Compliance
SSH Protocol Detection in Runtime Security
We've enhanced our Runtime Security capabilities by implementing SSH protocol detection. This feature helps identify potentially unauthorized or unusual SSH connections to pods, which are generally discouraged in Kubernetes environments.
Key benefits:
- Improved visibility into SSH usage within your clusters
- Enhanced security signaling for potentially risky connections
This addition strengthens your ability to monitor and secure your Kubernetes workloads. For more information on Runtime Security features, see our documentation.
Expanded Detection of Hacking Tools
We've enhanced our KSPM capabilities by adding detection rules for a wider range of hacking and penetration testing tools. This update improves our ability to identify potential security threats in your Kubernetes environments.
For more information on our security capabilities, refer to our Runtime Security documentation.
Security Improvement for GPU Metrics Exporter
We've improved the security of the GPU Metrics Exporter by moving sensitive information (API Key, Cluster ID) from ConfigMap to Secrets. This change enhances the protection of your credentials. When updating to the latest version, a job will automatically migrate existing data to the new secure format. For details on updating, see our GPU Metrics Exporter documentation.
API and Metrics Improvements
New Cost Comparison API Endpoint
We've introduced a new API endpoint for retrieving cluster-level cost comparison data between two periods of time:GET v1/cost-reports/organization/cost-comparison.
This endpoint allows you to compare costs and savings between two time periods, providing resource cost breakdowns and savings calculations.
For more details on parameters and response format, see our API documentation.
Enhanced Node Pricing API
We've updated our Node Pricing API to provide a more detailed breakdown of node costs. This improvement offers greater transparency and flexibility in understanding your cluster's pricing structure.
Key updates:
- Detailed base price breakdown for nodes, including CPU, RAM, and GPU prices
- All price components are now exposed directly in the API response
- Available for new pricing data; historical data breakdowns not included at this time
This update allows for more accurate cost analysis and simplifies integration with external tools. To access this enhanced pricing data, use the endpoint: /v1/pricing/clusters/{clusterId}/nodes/{nodeId}.
For more details on using the updated Node Pricing API, refer to our API documentation.
Expanded Node Cost Metrics
We've expanded our node metrics endpoint (/v1/metrics/nodes) to include detailed cost information. New metrics include hourly costs for CPU and RAM, as well as overprovisioning percentages for these resources.
For more information on using these metrics, refer to our metrics documentation or check out our API Reference.
Updated Image Scanning API
We've updated the /v1/security/insights/images API endpoint to include an image scan status filter. This improvement allows for more efficient querying of scanned images and supports multiple status selections in a single query. For details, see our API documentation.
User Interface Improvements
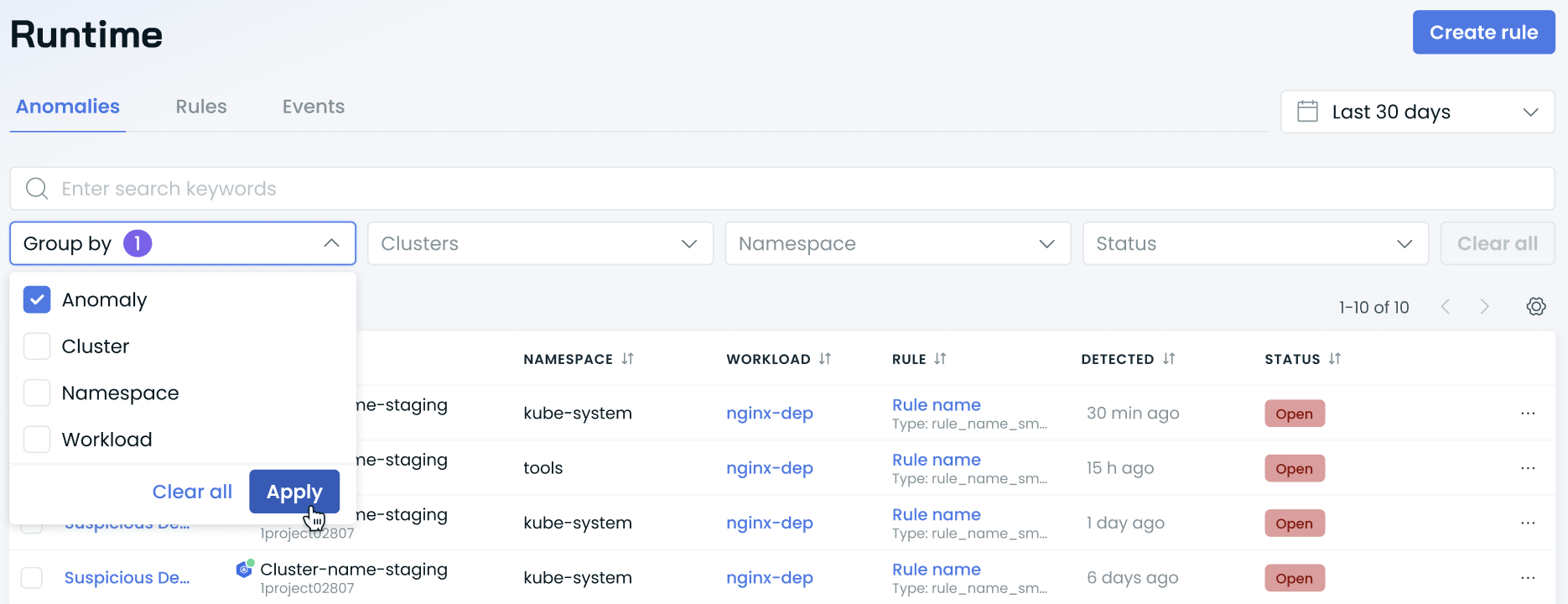
Enhanced Grouping Options in Runtime Security
We've improved the user experience in the Runtime Security section of the CAST AI console by introducing flexible grouping options. This allows users to organize and analyze security data more effectively.
Key features:
- New Group by dropdown menu in the Runtime Security interface
- Additional grouping parameters including Anomaly, Cluster, Namespace, Resource, and Workload
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the CAST AI agent. The complete list of changes is here.