
October 2025
Predictive Workload Scaling, Cast AI Operator, and Cross-Cloud GPU Sharing
This past month, we introduced predictive workload scaling, which proactively adjusts resources before traffic changes occur, and the Cast AI Operator for automated component lifecycle management. On the infrastructure side, we've expanded our support to include Oracle Cloud Infrastructure (OCI) for OMNI with GPU sharing capabilities across edge nodes, and GCP Private Service Connect for secure cluster connectivity, while AI Enabler added custom, fine-tuned model capabilities.
Major Features and Improvements
Cast AI Operator for Automated Component Management
The Cast AI Operator (castware-operator) automates the installation, configuration, and lifecycle management of Cast AI components in your Kubernetes cluster. This new control plane component reduces manual effort by handling component updates for you.
Key capabilities:
- Automated component management: The Operator installs and manages
castai-agentwith additional components planned for future releases - Console-driven updates: Update both the Operator and managed components directly through Component Control without running scripts
- Automatic migration: Existing
castai-agentinstallations are automatically detected and migrated to Operator management during Operator installation - Self-upgrading: The Operator updates itself when new versions are released
Installation options:
- New clusters: The Operator is installed automatically during Phase 1 onboarding
- Existing clusters: Enable via Component Control, manual Helm installation, or during
castai-agentupdates - Terraform: Full Terraform support for Operator installation and component management
For installation instructions and migration details, see our Cast AI Operator documentation.
Oracle Cloud Infrastructure Support for OMNI
OMNI now supports Oracle Cloud Infrastructure (OCI) as an edge location provider, enabling EKS and GKE clusters to provision nodes in OCI regions. This expands OMNI's multi-cloud capabilities beyond AWS and GCP, providing access to OCI's GPU capacity and competitive pricing for AI and compute-intensive workloads.
Users can create OCI edge locations through the Cast AI console and provision OCI instances that join their EKS or GKE clusters as native nodes. GPU resources on OCI edge nodes are visible at the control plane level and can be scheduled for GPU-based workloads.
This integration addresses GPU capacity constraints that many customers face by adding OCI's extensive GPU availability to OMNI's pool of edge location options across multiple cloud providers.
GPU Sharing Support for OMNI Edge Nodes
OMNI edge nodes now support GPU sharing through both Multi-Instance GPU (MIG) and time-slicing configurations via the NVIDIA GPU Operator. This enables optimized GPU utilization on nodes provisioned in edge locations across different cloud regions and providers.
Time-slicing allows multiple workloads to share a single physical GPU through rapid context switching, with configurable partition counts to maximize resource utilization for inference and development workloads.
MIG enables hardware-level partitioning of high-end GPUs (such as A100 and H100) into isolated instances with dedicated memory and compute resources, providing stronger isolation for multi-tenant scenarios.
These capabilities extend the GPU sharing functionality previously available for main cluster nodes to OMNI's multi-region and multi-cloud edge deployments.
Predictive Workload Scaling
Workload Autoscaler now offers predictive scaling, which uses machine learning to forecast CPU resource needs up to three days in advance based on historical usage patterns. Rather than reacting to changes after they occur, predictive scaling proactively adjusts resources before anticipated traffic increases or decreases.
The system analyzes workload usage over time to identify repeatable patterns such as daily or weekly cycles, then generates CPU recommendations based on predicted future usage. A safety buffer is automatically applied to prevent under-provisioning, and predictions update every 30 minutes, automatically adapting when workload patterns change.
Predictive scaling is designed for workloads with consistent, repeatable patterns and requires a minimum of 5 days of historical data. The feature is disabled by default and must be explicitly enabled through annotations or the Cast AI console.
Learn more in our Predictive scaling documentation.
Security and Compliance
AWS PrivateLink Support for Kvisor
Cast AI's AWS PrivateLink configuration now supports the Kvisor security and observability component. Organizations using PrivateLink to maintain private connectivity between their clusters and Cast AI can now enable Kvisor without requiring public internet endpoints.
This addition complements the existing PrivateLink endpoints, aligning with the GCP Private Service Connect (PSC) offering in terms of features.
GCP Private Service Connect Support for GKE
GKE clusters can now connect to Cast AI through GCP Private Service Connect, enabling secure communication without exposing traffic to the public internet. This addresses requirements for private GKE clusters that lack direct internet access.
Key features:
- Single endpoint architecture: Unlike AWS PrivateLink's multiple endpoints, Private Service Connect uses one endpoint with wildcard DNS routing to serve all Cast AI services
- Regional deployment: Support for both US (us-east4) and EU (europe-west1) regions
- Simplified configuration: Wildcard DNS setup (
*.psc.prod-master.cast.aior*.psc.prod-eu.cast.ai) routes all Cast AI traffic through the private endpoint - Full platform access: All Cast AI services are accessible through the private connection
Setup requires creating a Private Service Connect endpoint in your GCP project, configuring Cloud DNS with wildcard records, and connecting your cluster using modified Phase 1 or Phase 2 scripts. Terraform examples are available for automated infrastructure provisioning.
Learn more in our Private Service Connect documentation.
Cloud Provider Integrations
Spot Interruption Prediction for GKE
GKE node templates now support spot interruption prediction, enabling proactive workload rebalancing before Spot Instance terminations occur. This feature utilizes Cast AI's machine learning model to predict interruptions and automatically triggers the Rebalancer to move workloads to stable nodes before disruption occurs.
The interruption prediction model for GCP uses a 3-hour prediction window, optimized for GCP's Spot Instance behavior patterns. When enabled in node templates with Spot Instances, the system applies interruption prediction labels to at-risk nodes and initiates rebalancing operations to minimize the impact on workload.
This capability is disabled by default to allow teams to assess cost-stability tradeoffs, as preemptive rebalancing may increase costs.
Learn more in our Spot interruption prediction documentation.
GPU Time-Slicing Support for Amazon Linux 2023
GPU time-slicing is now supported on EKS clusters running Amazon Linux 2023, expanding beyond the previously supported Bottlerocket operating system. This enables multiple workloads to share a single physical GPU through rapid context switching on AL2023-based nodes, maximizing GPU resource utilization for inference and development workloads.
See time-slicing documentation.
Workload Optimization
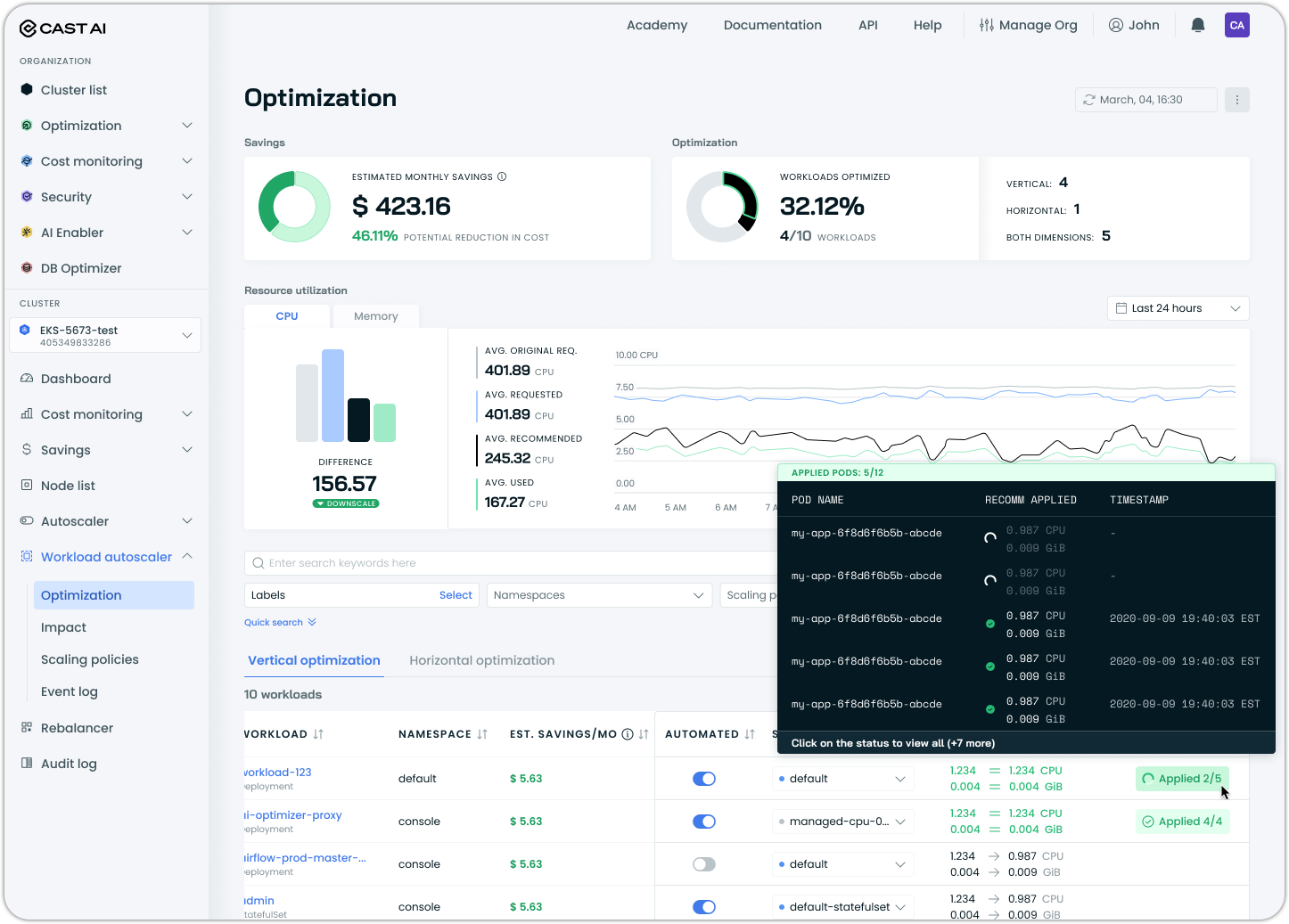
Workload Status Tracking
Workload Autoscaler now provides detailed status tracking for recommendation deployment and pod-level application. The workload list displays an "Applied" status showing how many pods are running the latest recommendation (e.g., "Applied 3/5"), with drill-down details available in the workload view.
The status view shows per-pod information, including recommendation application timestamps, in-place resize progress, and any deployment issues.
Semi-Automatic CPU Limit Management
Workload Autoscaler now offers a semi-automatic CPU limit option that provides conditional limit management based on workload configuration. When enabled, this setting applies CPU limits as a multiple of requests only to workloads that already have CPU limits defined and where existing limits are lower than the calculated result. For workloads without existing limits or with higher limits, the configuration remains unchanged.
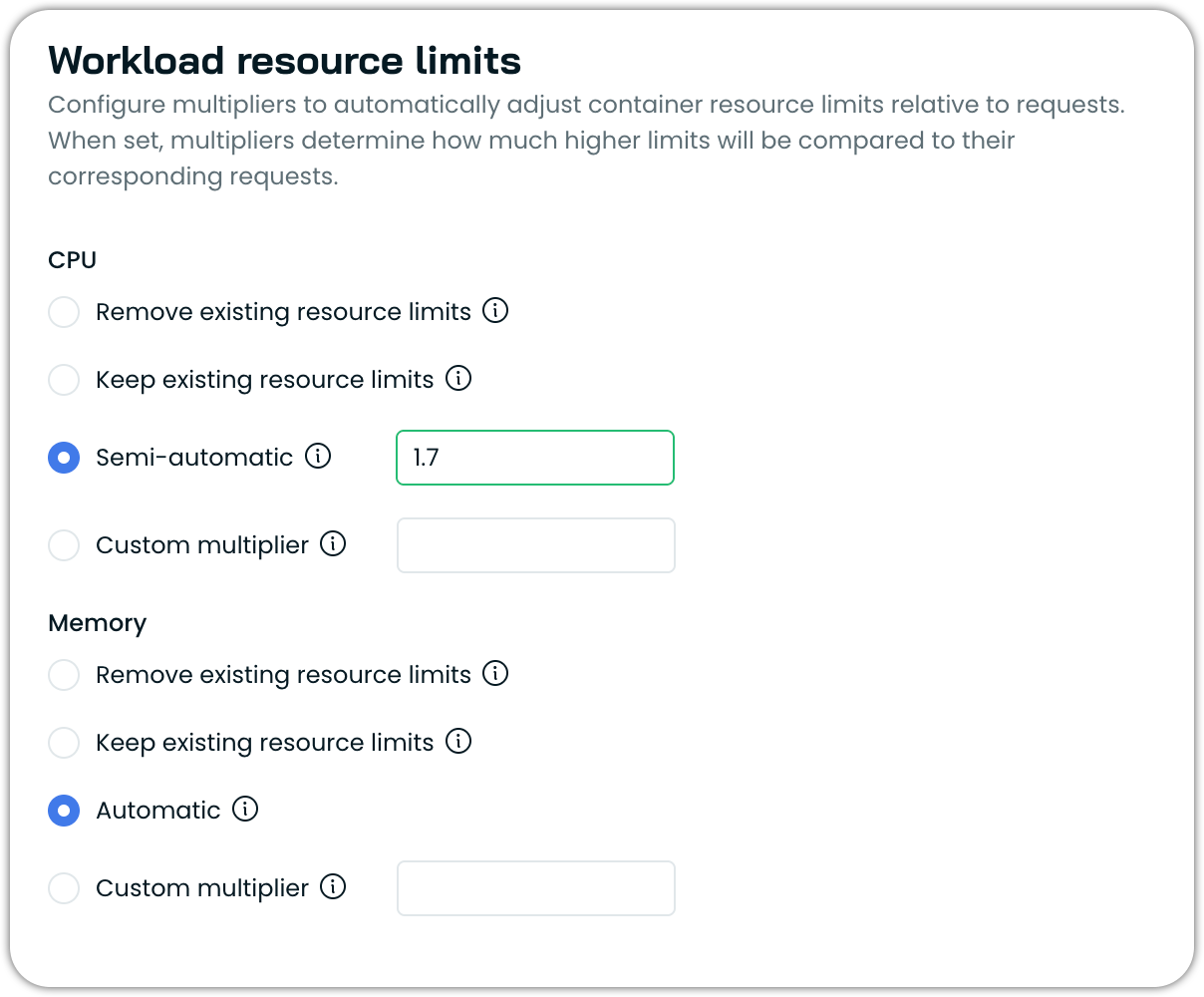
See the updated documentation on workload resource limits.
Improved KEDA Custom Metric Handling
Workload Autoscaler now detects when KEDA workloads scale primarily based on custom or external metrics rather than CPU usage. When custom metrics dominate scaling behavior, the system applies reduced or no vertical scaling corrections to CPU requests, preventing unnecessary resource increases that don't improve throughput.
This addresses scenarios where workloads use KEDA with both CPU and custom metrics (such as queue length or application-specific metrics), but scale primarily in response to the custom metric. Previously, vertical scaling adjustments could push CPU requests higher even when additional CPU capacity wouldn't increase per-replica throughput, leading to over-provisioning.
Learn more in our KEDA compatibility documentation.
Automatic Startup Probe Failure Detection and Remediation
Workload Autoscaler now automatically detects and responds to readiness and startup probe failures during container startup. When probe failures are detected (more than 10 failures within a 5-minute window), the system automatically adds a 20% overhead to CPU and memory recommendations to help containers start successfully.
This overhead gradually decays over time, similar to out-of-memory kill (OOM) protection, ensuring workloads have sufficient resources during startup without permanently inflating resource requests. The feature helps prevent scenarios where optimized resource recommendations cause containers to fail health checks during initialization, particularly when multiple workloads restart simultaneously.
Probe failure detection requires the workload-autoscaler-exporter component version 0.60.0 or higher, and is enabled by default for workloads with vertical optimization active.
Configurable Confidence Threshold for Scaling Policies
Scaling policies now include a configurable confidence threshold setting that determines the minimum confidence level required before automatically applying resource recommendations to workloads. This setting enables teams to strike a balance between optimization speed and recommendation reliability, tailored to their risk tolerance and workload characteristics.
Confidence is calculated based on the ratio of collected metric data points to expected data points within the configured look-back period. For example, 90% confidence means at least 90% of expected metrics have been collected, providing sufficient data quality for reliable recommendations.

Refer to the recommendation confidence documentation for more information.
Database Optimization
Extended MySQL Query Support
Database Optimizer now supports MySQL UNION, INTERSECT, and EXCEPT statements in cached queries. These set operations can now be parsed and cached like other query types, expanding DBO's compatibility with complex MySQL workloads.
Query Search for Database Optimizer Caches
Database Optimizer cache views now include server-side query search functionality. Users can search for specific queries within a cache by entering search terms, with results filtering as they type.
Helm Values File Download for Database Optimizer
Database Optimizer cache deployment now supports Helm-based installation through downloadable values files. Users can download a pre-configured values file containing endpoint details and cache settings, customize it as needed, and install the cache component using Helm.
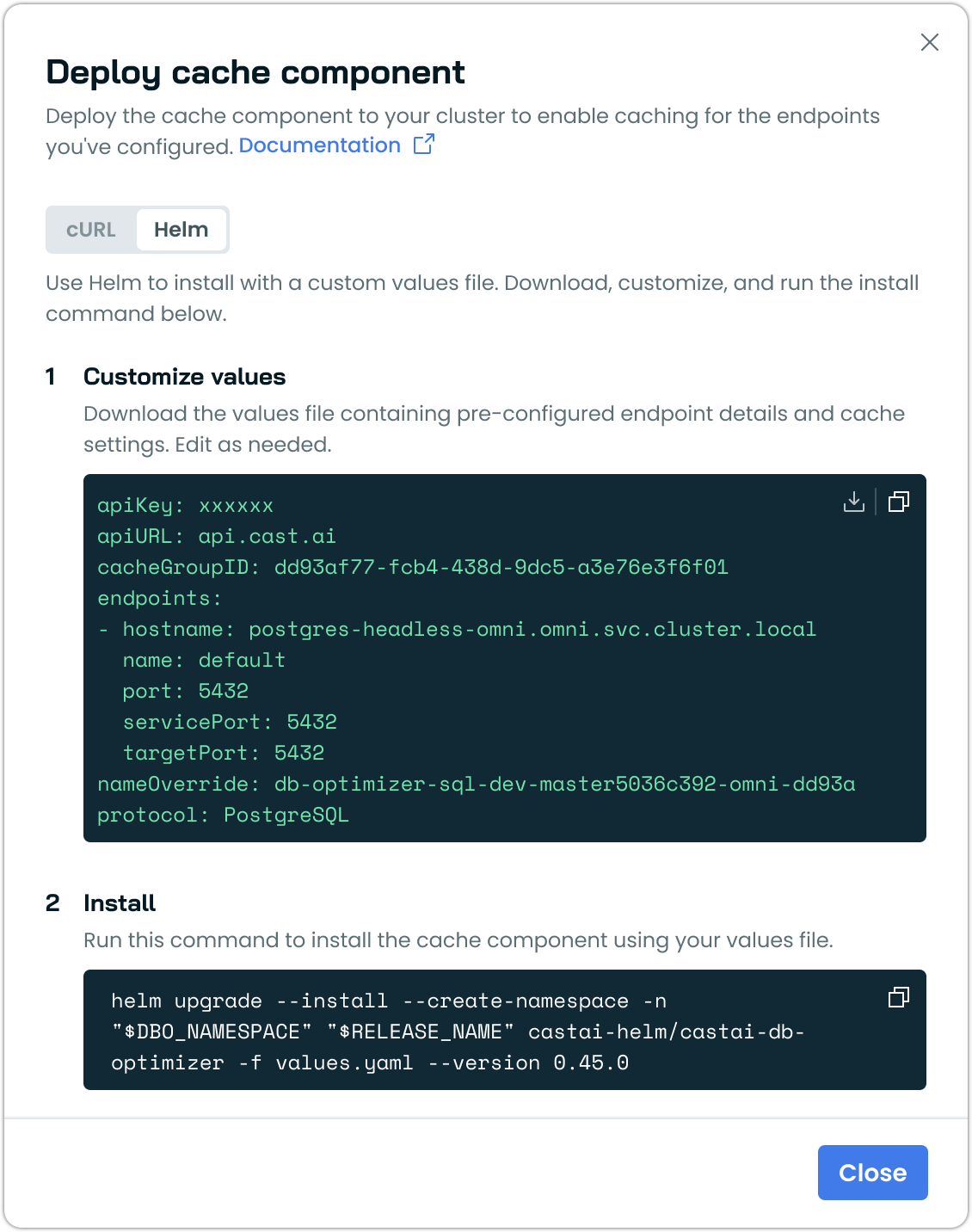
This provides an alternative to the automated installation script for teams that require manual review or customization of Helm charts before installation.
AI Enabler
Custom or Fine-Tuned Model Registration and Deployment
AI Enabler now supports registering and deploying custom fine-tuned models through the model library. Engineers can connect their fine-tuned model repository directly to AI Enabler and deploy them without writing code or managing YAML configurations.
After connection, AI Enabler automatically generates a node template with recommended resource provisions based on the model size.
Custom models are automatically exposed as providers in the AI Enabler interface and appear in the model library with a custom model designation. Users can deploy these models directly from there using the same deployment workflow as pre-configured models.
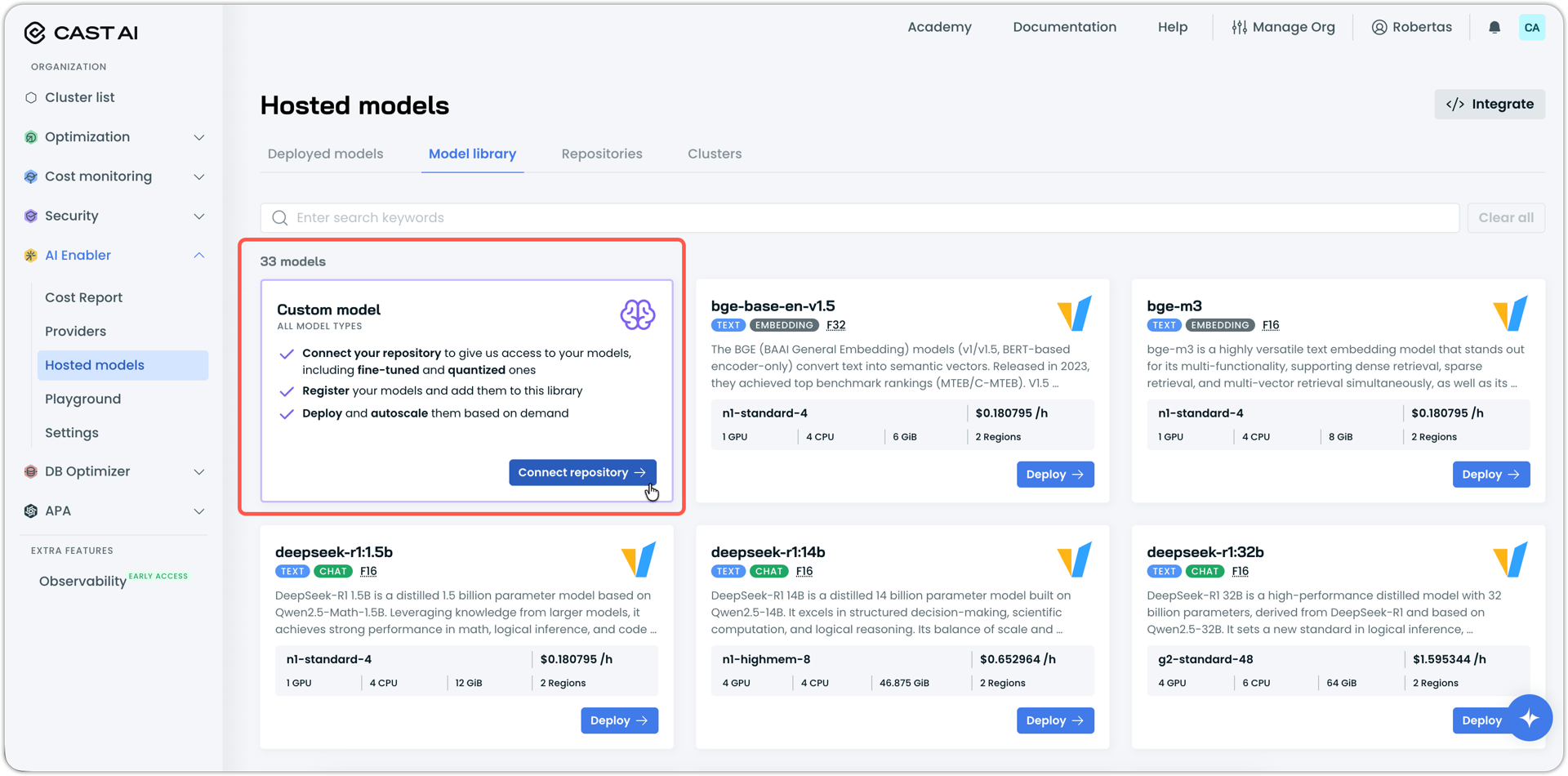
Expanded Model Support
AI Enabler now supports additional models for deployment:
- bge-m3: Multi-lingual embedding model for semantic search and retrieval-augmented generation (RAG) applications
- Mistral 7B Instruct v0.3: Instruction-tuned language model for text generation, question answering, and conversational AI tasks
- Qwen2.5-3B: Compact language model optimized for efficient inference across diverse tasks
- Qwen3-Coder-30B-A3B-Instruct: Specialized code generation model for software development workflows
This expands AI Enabler's model library to support diverse AI workloads across multiple cloud providers.
Learn how to see the most up-to-date list of supported LLM providers using our Supported Providers documentation.
Spot Interruption Visibility for Hosted Models
AI Enabler now displays Spot interruption events and status changes for hosted models. When a Spot interruption occurs, the model status updates to "Restarting" with an explanation that the model is restarting on a newly provisioned node. Spot interruption events also appear in the model's event log with timestamps, providing clear visibility into infrastructure changes affecting model availability.
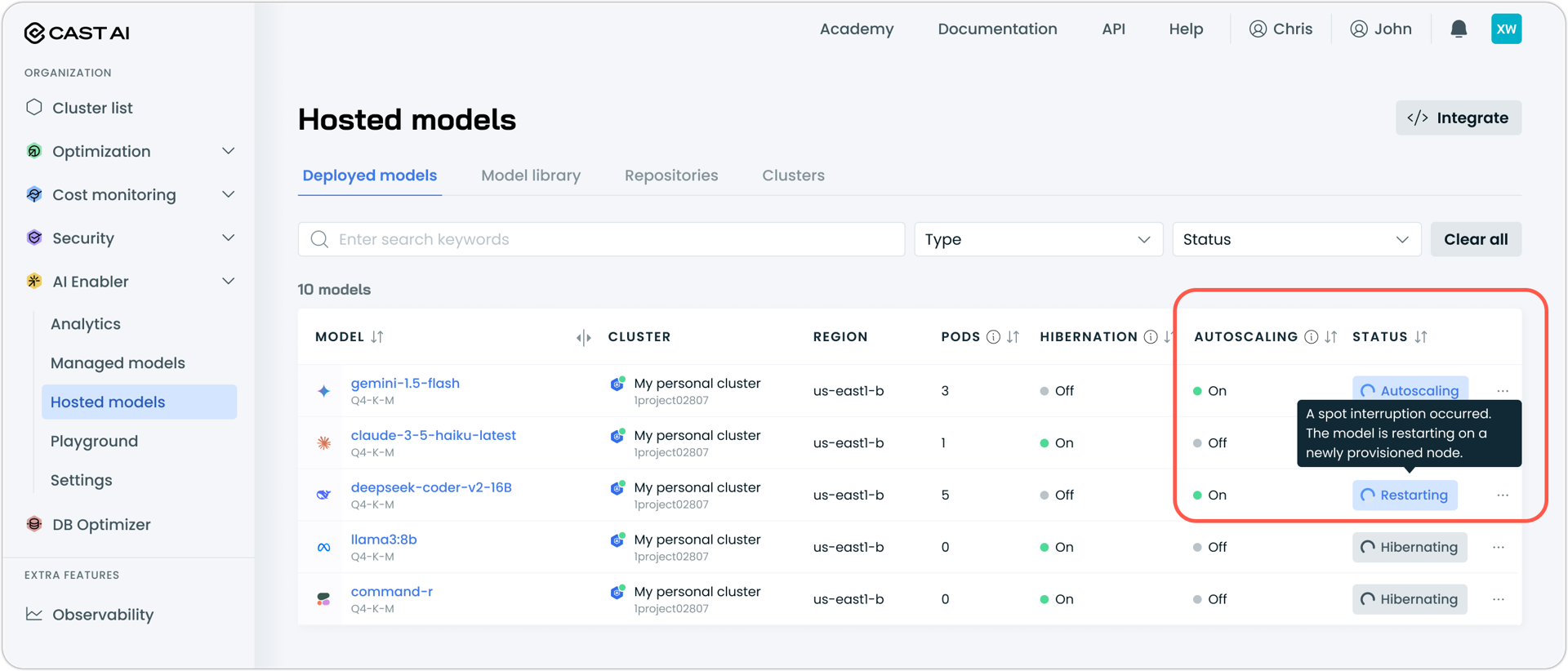
Node Configuration
Dynamic Max Pods Formula for GKE
GKE node configurations now support a dynamic max pods per node formula that calculates pod limits based on instance characteristics. This advanced option utilizes variables such as NUM_CPU and NUM_RAM_GB to set distinct pod limits for various instance types within the same node configuration.
For most use cases, the existing static max pods per node value remains the recommended approach. The formula option is intended for scenarios requiring variable pod limits across diverse instance types.
For configuration details and examples, see our Node Configuration documentation
Organization Management
Terraform Support for Enterprise Role Bindings
The Cast AI Terraform provider now supports managing enterprise role bindings through the castai_enterprise_role_bindings resource. This enables infrastructure-as-code configuration of role assignments across enterprise organizations, including user, service account, and group bindings with organization and cluster-level scopes.
For more details, see the relevant Pull Request.
Enterprise API Key Support for Child Organizations
Enterprise API keys can now access resources within child organizations. Enterprise Owners and Viewers can automate workflows and manage all enterprise resources using a single API key, eliminating the need to generate separate keys for each child organization.
To access child organization resources, generate a user API key for the parent organization (Enterprise) and include both the API key and the target child organization ID in the X-CastAI-Organization-Id header when making API requests. The system automatically validates the parent-child relationship and grants access if the requesting organization is authorized to manage the target organization.
Cost Management
Automatic Commitment Enablement During Import
Commitment import workflows for AWS and Azure now include an auto-enablement option that is selected by default. When enabled, newly imported commitments are automatically enabled for autoscaler usage and assigned to all clusters, ensuring immediate utilization of Reserved Instances and Savings Plans without requiring manual activation.
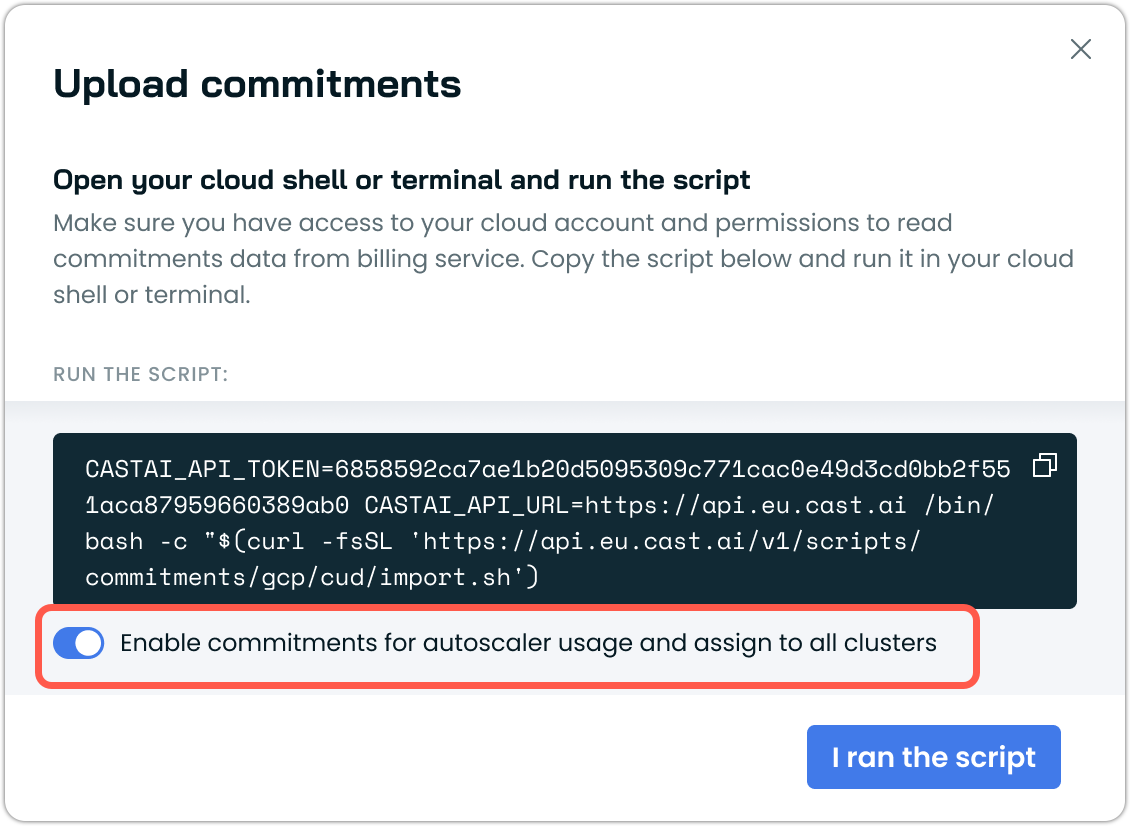
See Commitments documentation to get started.
Automatic Cost Detection for Cast AI Anywhere Clusters
Cast AI Anywhere clusters now automatically detect the underlying cloud provider and infer instance pricing for cost reporting for Oracle Cloud Infrastructure (OCI) and kOps hosted on AWS. This provides cost visibility for clusters without requiring manual price inputs, enabling more accurate cost tracking across these diverse Kubernetes environments.
User Interface Improvements
Uplifted Workload Autoscaler Interface
The Workload Autoscaler workload detail view has been slightly redesigned with improved organization and navigation. The updated interface includes:
- Summary dashboard: Displays estimated monthly savings, CPU and memory differences, and optimization status at the top of the page
- Tabbed navigation: Organizes information into Charts, Settings, and Latest Events tabs for easier access to workload data
- Policy selection: Scaling policy dropdown relocated to the top of the page for more convenient policy switching
- Latest events tab: Shows recent workload events from the event log with expandable details for troubleshooting and monitoring
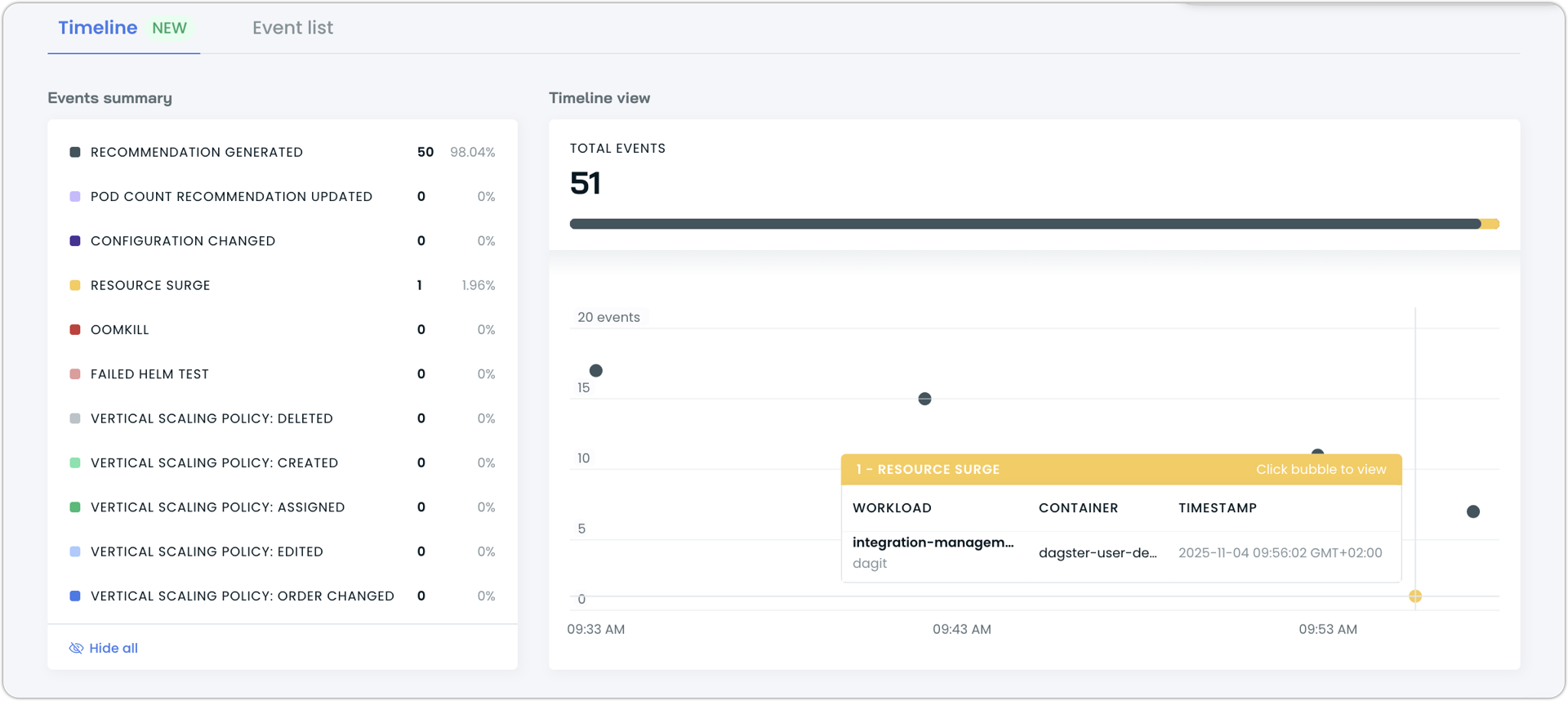
Recommendation Confidence Indicators
Workload Autoscaler recommendation cards now display detailed confidence information through expanded tooltips. When recommendations have low data confidence, tooltips show the current confidence percentage, the number of data points collected, the lookback period for each resource (CPU and memory), when the last recommendation was applied, and an estimated time to reach higher confidence levels.
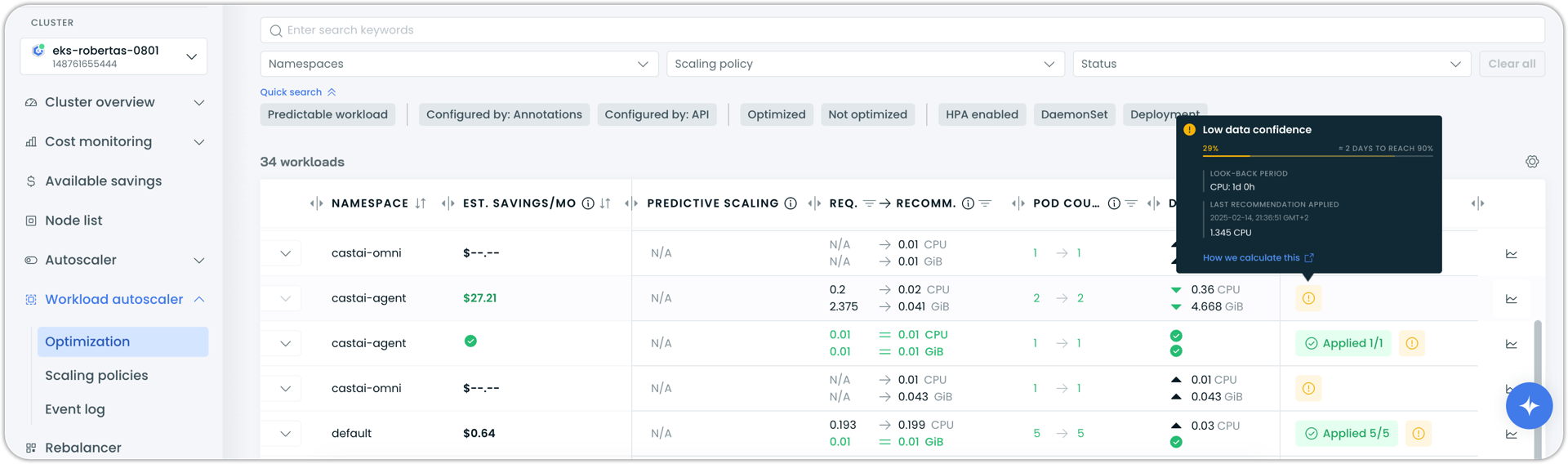
This provides transparency into the data collection process and helps users understand when recommendations will become more stable and reliable as more usage data is gathered.
In-Place Rightsizing Status Indicator
The Workload Autoscaler dashboard now displays an in-place rightsizing status indicator, indicating when Kubernetes in-place Pod resizing is active for workload optimization. This provides immediate visibility into whether recommendations are being applied through pod restarts or via in-place resize, helping teams understand the optimization method being used.
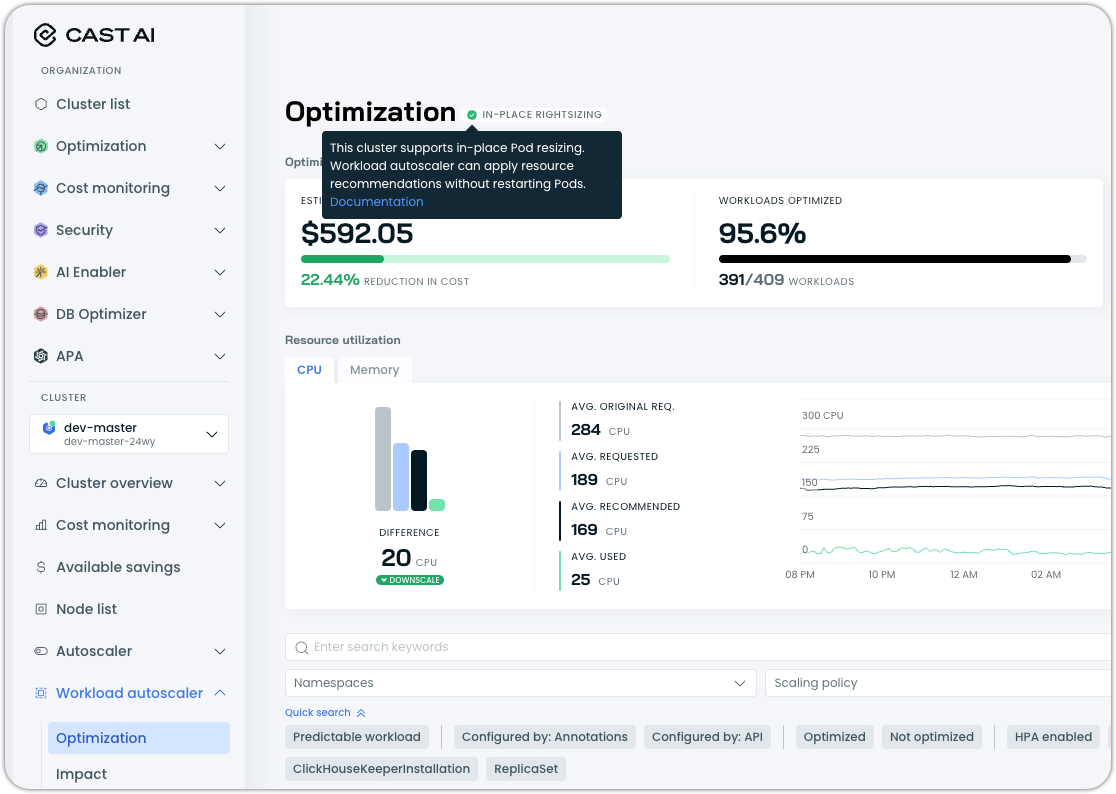
See our In-place Pod Resizing documentation for the requirements.
Pod Mutation Impact Visibility
The Pod Mutations list now displays the number of pods affected by each mutation, providing immediate visibility into the reach and impact of each mutation.
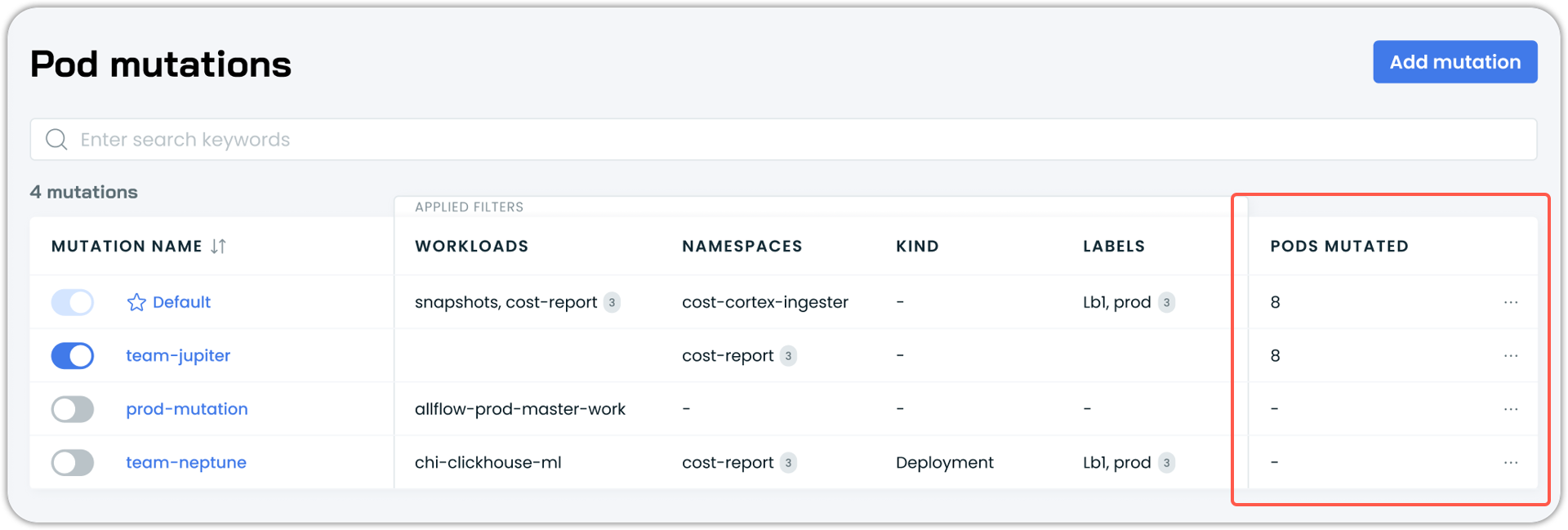
Cluster Tags Display and Filtering
Clusters now display associated tags in both the cluster dashboard and cluster list views. Tags appear in a dedicated section on the cluster dashboard, with a drawer view available for clusters with multiple tags. The cluster list includes tag-based filtering, so users can quickly locate clusters by their assigned tags.
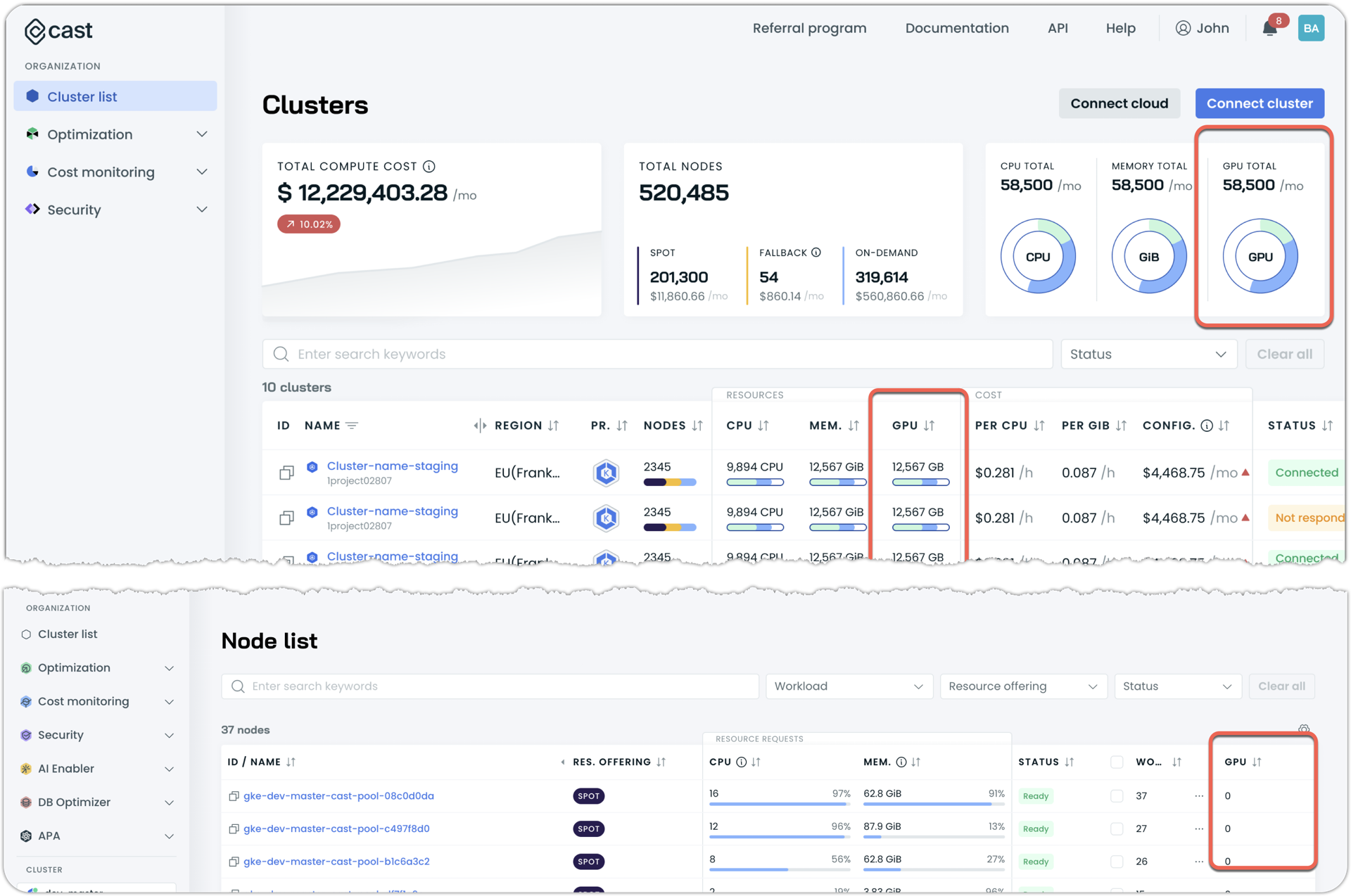
GPU Metrics in Cluster and Node Lists
The cluster list now displays GPU information in both the summary widgets and as an optional column, while the node list offers the optional GPU column.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are now ready for use in your infrastructure-as-code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.