
April-July 2025
Advanced GPU Sharing, Enterprise-Grade Access Control, and Cluster Hibernation Schedules
We are excited to be back with our comprehensive release notes, covering the significant innovations and improvements we've delivered over the past few months. During this period, our team has been hard at work expanding Cast AI's capabilities across all areas of business and products. This consolidated update highlights major platform advances, including rather sophisticated GPU sharing we were able to implement, enterprise-grade access controls that so many of you have asked for, comprehensive cluster scoring to make optimization more accessible, and dozens of other improvements that make Kubernetes optimization more hassle-free and powerful than ever.
Major Features and Improvements
GPU Sharing Support with Time-Slicing and MIG
Cast AI now supports advanced GPU sharing capabilities through both time-slicing and Multi-Instance GPU (MIG) technology, enabling significantly improved GPU utilization and cost optimization for AI workloads.
Time-slicing capabilities:
- Multi-workload GPU sharing: Multiple workloads can share a single physical GPU through rapid context switching, maximizing resource utilization for inference and development workloads
- Flexible sharing ratios: Configure up to 48 shared clients per GPU with customizable ratios per GPU type
- Cloud provider support: Available on AWS EKS (Bottlerocket) and GCP GKE
Multi-Instance GPU (MIG) support:
- Hardware-level isolation: Partition high-end GPUs like A100 and H100 into up to 7 isolated instances with dedicated memory and compute resources
- Automatic provisioning: Cast AI detects MIG workload requirements and automatically provisions and configures GPU partitions during node creation
- Combined optimization: MIG can be combined with time-slicing to achieve even higher density (e.g., 28 workloads on a single A100 with 7 MIG partitions and 4× time-sharing)
Enhanced autoscaling:
- Smart resource calculation: The autoscaler accounts for GPU sharing multipliers and MIG partition configurations when making provisioning decisions
- Improved bin-packing: Better GPU resource allocation considering shared GPU capacity and partition isolation requirements
This advancement addresses the growing demand for cost-effective GPU utilization in AI workloads, particularly for inference, development, and multi-tenant scenarios where dedicated GPU access isn't required.
For detailed configuration examples and setup instructions, see our GPU documentation.
Enterprise Management for Multi-Organization Governance
Cast AI has introduced Enterprises, a new organizational layer that enables large customers to manage multiple Cast AI organizations with centralized governance while maintaining business unit autonomy. This addresses the growing need for enterprise-scale management of distributed Kubernetes environments.
Key capabilities:
- Hierarchical organization structure: Parent organizations act as Enterprise control points, managing multiple child organizations that function as independent business units
- Cascading access control: Enterprise-scoped roles automatically cascade permissions across all child organizations, eliminating manual role assignments
- Centralized SSO management: Configure single sign-on once at the Enterprise level to govern authentication across all child organizations
The Enterprise model allows platform teams to manage user access and governance from a single interface while business units retain complete control over their clusters and Cast AI product configurations.
Enterprise setup is currently available through manual migration support. Contact your Cast AI team for enterprise configuration assistance.
Cluster Score: Comprehensive Optimization Assessment
A new Cluster Score feature provides a comprehensive 0-10 rating that evaluates your cluster's optimization across multiple dimensions. Rather than focusing on single metrics, the score analyzes resource provisioning, workload efficiency, and rebalancing effectiveness to deliver actionable insights.
Key features:
- Real-time scoring that updates automatically every hour with instant manual refresh capability
- Benchmarking against averages from all Cast AI customers for industry context
- Detailed breakdown across three main categories: Resource Provisioning, Workload Resource Optimization, and Rebalancer usage with specific improvement recommendations
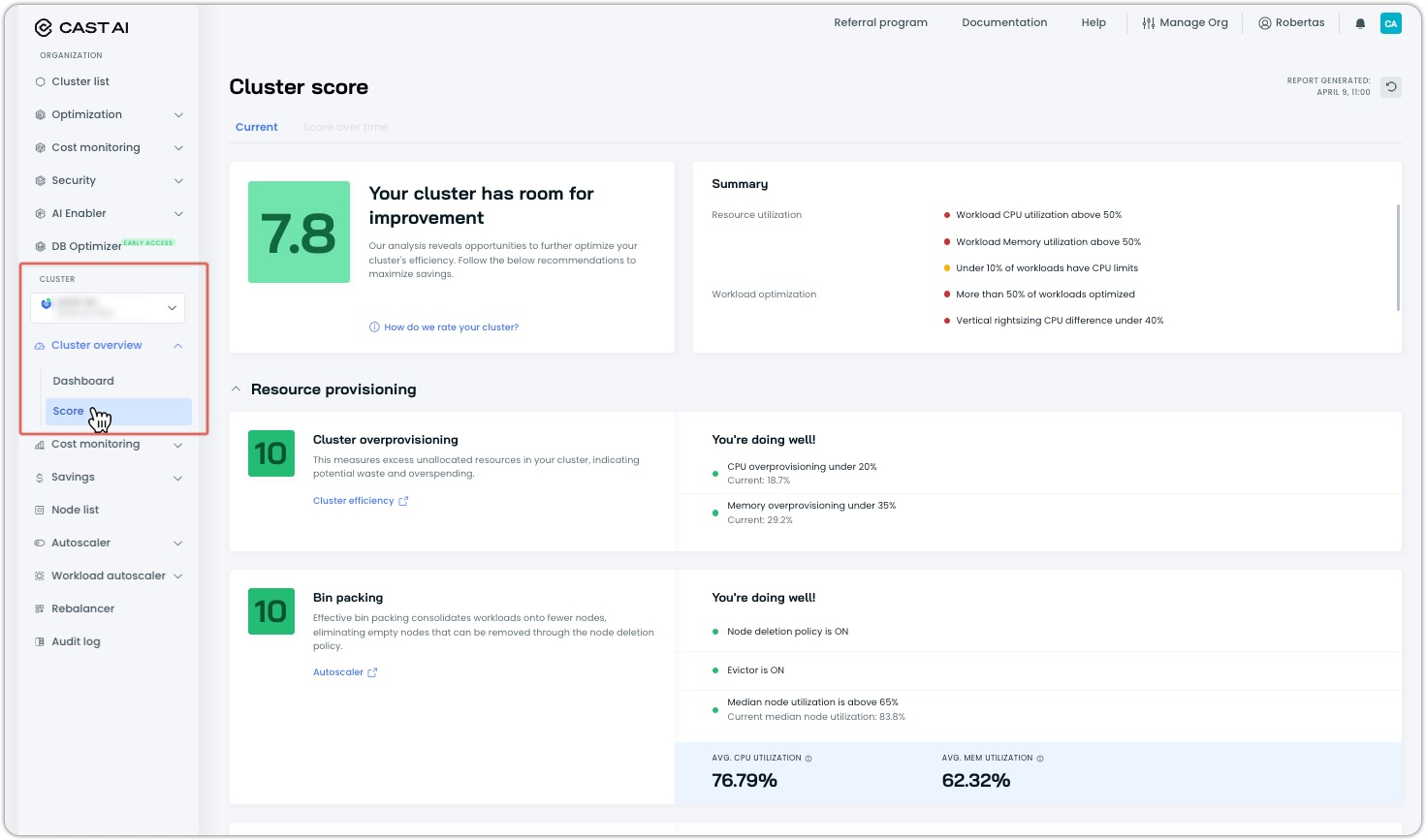
The score helps prioritize optimization efforts by identifying which areas will deliver the greatest impact. Each component provides targeted recommendations, from enabling the Workload Autoscaler to configuring appropriate rebalancing schedules.
Note that full scoring requires Phase 2 (automated optimization) cluster connection, while Phase 1 clusters receive partial scores for overprovisioning and utilization metrics only.
For detailed information about improving your cluster score, see our Cluster Score documentation.
Organization Management
Role Bindings for Granular Access Management
Role bindings have been introduced to provide granular access control by defining the association between subjects (users, groups, or service accounts) and roles within specific scopes. This foundational capability enables precise permission management at the organization and cluster levels.
Key capabilities:
- Flexible subject assignment: Bind roles to individual users, user groups, or service accounts based on your exact organizational needs
- Scope-aware permissions: Configure access at the organization level for broad permissions or the cluster level for targeted resource access
- Multi-interface support: Manage role bindings through the console interface, REST API, or Terraform provider for seamless integration with existing workflows
- Hierarchical access control: Support for inherited permissions where organization-level bindings can provide broader access while cluster-specific bindings offer targeted control
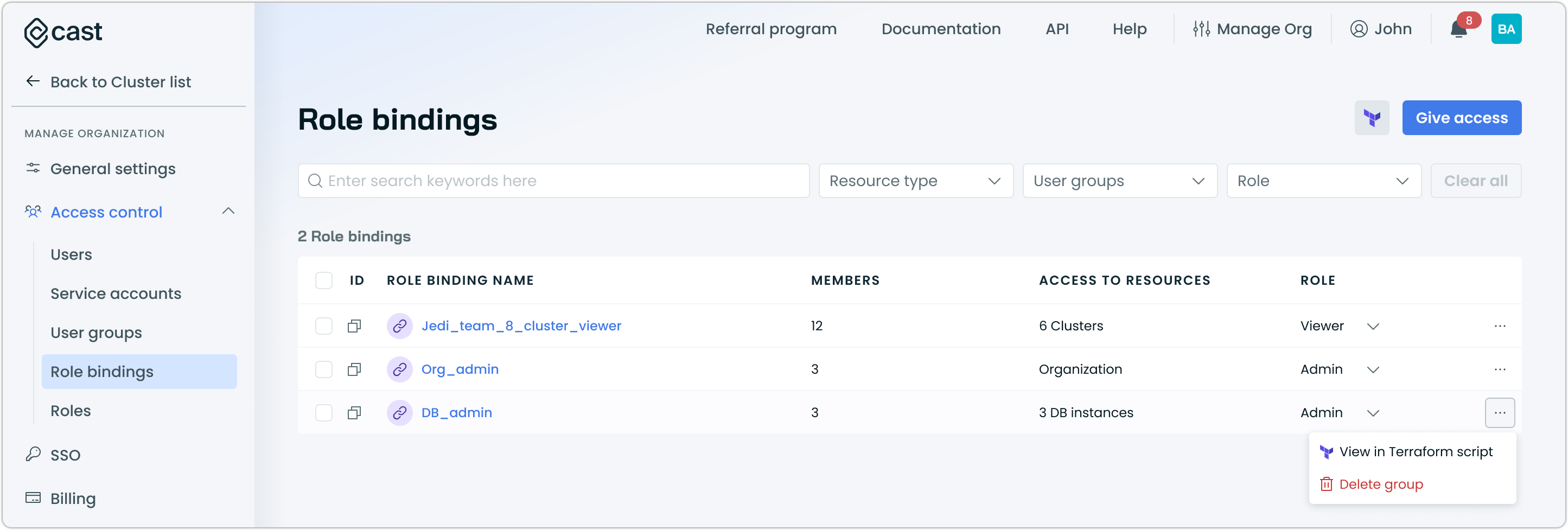
Role bindings work alongside the existing user and group management system to create a comprehensive RBAC framework. The system follows an "allow wins" approach where allowing access takes precedence over denying it, ensuring predictable access patterns across different permission sources.
Optimization and Cost Management
Improved Cluster Hibernation
Cluster hibernation now features improved accessibility through a dedicated console interface and Terraform provider support, making it easier to implement automated cost optimization for non-production environments. Previously available through API only, hibernation can now be managed through multiple interfaces for greater workflow integration.
Enhanced management options:
- Console interface: Direct hibernation scheduling and management through the Cast AI console with intuitive configuration options
- Terraform integration: Full Infrastructure as Code support for hibernation schedules, enabling automated deployment and configuration management
- Organization-level scheduling: Centralized hibernation schedules that can be applied across multiple clusters with consistent timing and policies
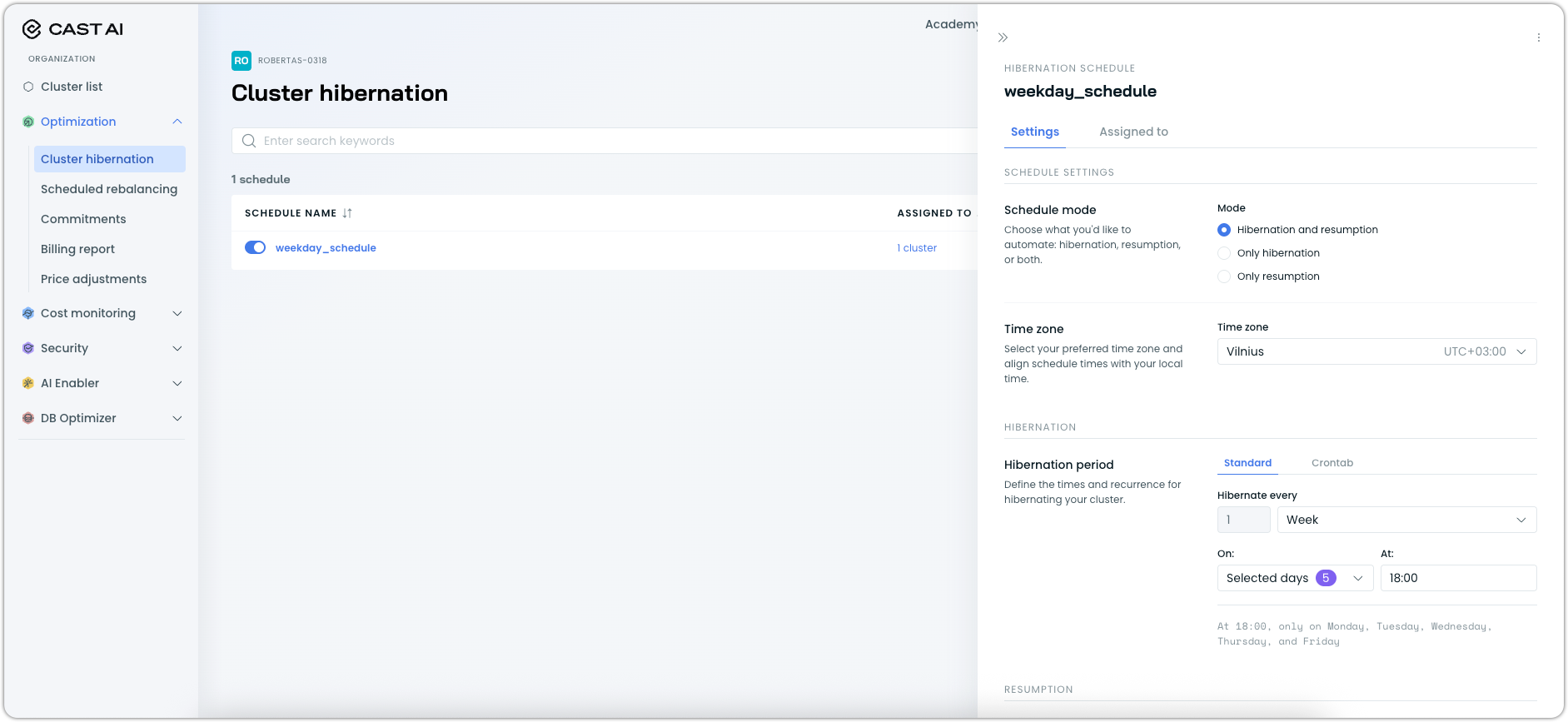
These improvements make cluster hibernation more accessible for teams seeking to optimize costs for development clusters, staging environments, and other infrastructure that doesn't require 24/7 availability.
For detailed configuration instructions, see our Cluster Hibernation documentation.
Cluster Score Historical Tracking
The Cluster Score feature now includes historical tracking capabilities, allowing you to monitor optimization progress over time. This provides valuable insights into how your cluster's efficiency evolves as you implement various optimization strategies.
Key features:
- Time-series visualization: Track cluster score changes over configurable time periods to measure improvement
- Performance correlation: Correlate score changes with specific optimization actions like enabling Workload Autoscaler, configuring rebalancing schedules, or adjusting node templates
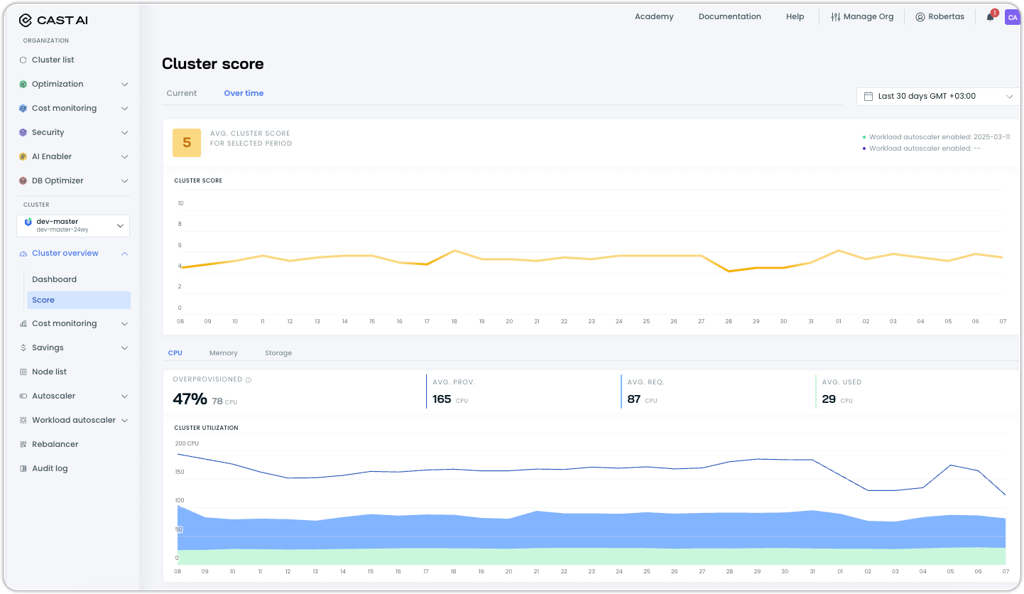
The historical view complements the existing real-time cluster scoring by providing context for optimization decisions and helping understand the long-term impact of configuration changes.
This capability is currently available behind a feature flag for early access testing and feedback.
Enhanced Allocation Groups with Historical Recalculation
Allocation Groups now support historical data recalculation when filters are modified, providing better cost visibility across any time period. This eliminates the previous limitation where data was only calculated from the moment new filters were applied.
Allocation Groups are now also supported in the Cast AI Terraform provider, enabling Infrastructure as Code management of cost allocation strategies alongside cluster configurations.
Workload Optimization
Automated Workload Profiling and System Scaling Policies
Workload optimization becomes significantly more streamlined with the introduction of automated workload profiling and predefined system scaling policies. New clusters now benefit from intelligent policy assignment that happens automatically during onboarding, eliminating manual configuration overhead.
Automated workload profiling:
- Intelligent policy assignment: All workloads are automatically analyzed and assigned to appropriate system policies based on labels, types, and namespaces during cluster onboarding
- Instant optimization coverage: Workloads receive immediate policy assignment without manual intervention, accelerating time-to-value
System scaling policies:
- Purpose-built configurations: Predefined policies including resiliency for StatefulSets, balanced for optimal cost-performance trade-offs, cost-savings for maximum efficiency, and stability for consistent performance
- Experience-based optimization: Policies are pre-configured with settings derived from Cast AI's extensive Kubernetes workload optimization experience
- Customization foundation: System policies can be duplicated to create fully customizable versions, providing an excellent starting point for organization-specific requirements
The new approach replaces manual policy assignment with intelligent automation while maintaining the flexibility to create custom policies for specific use cases.
For detailed configuration options and policy management, see our Workload Autoscaling documentation.
Assignment Rules for Scaling Policies
The Workload Autoscaler now supports assignment rules for scaling policies, enabling automatic workload assignment based on sophisticated matching criteria. This eliminates manual policy assignments by intelligently categorizing workloads according to their characteristics and assigning them to appropriate policies for automated optimization.
Key capabilities:
- Automated workload assignment: Define rules based on namespaces, workload types, and label expressions to automatically assign policies without manual intervention
- Priority-based evaluation: Configure policy priority ordering where higher-priority policies take precedence when multiple rules match the same workload
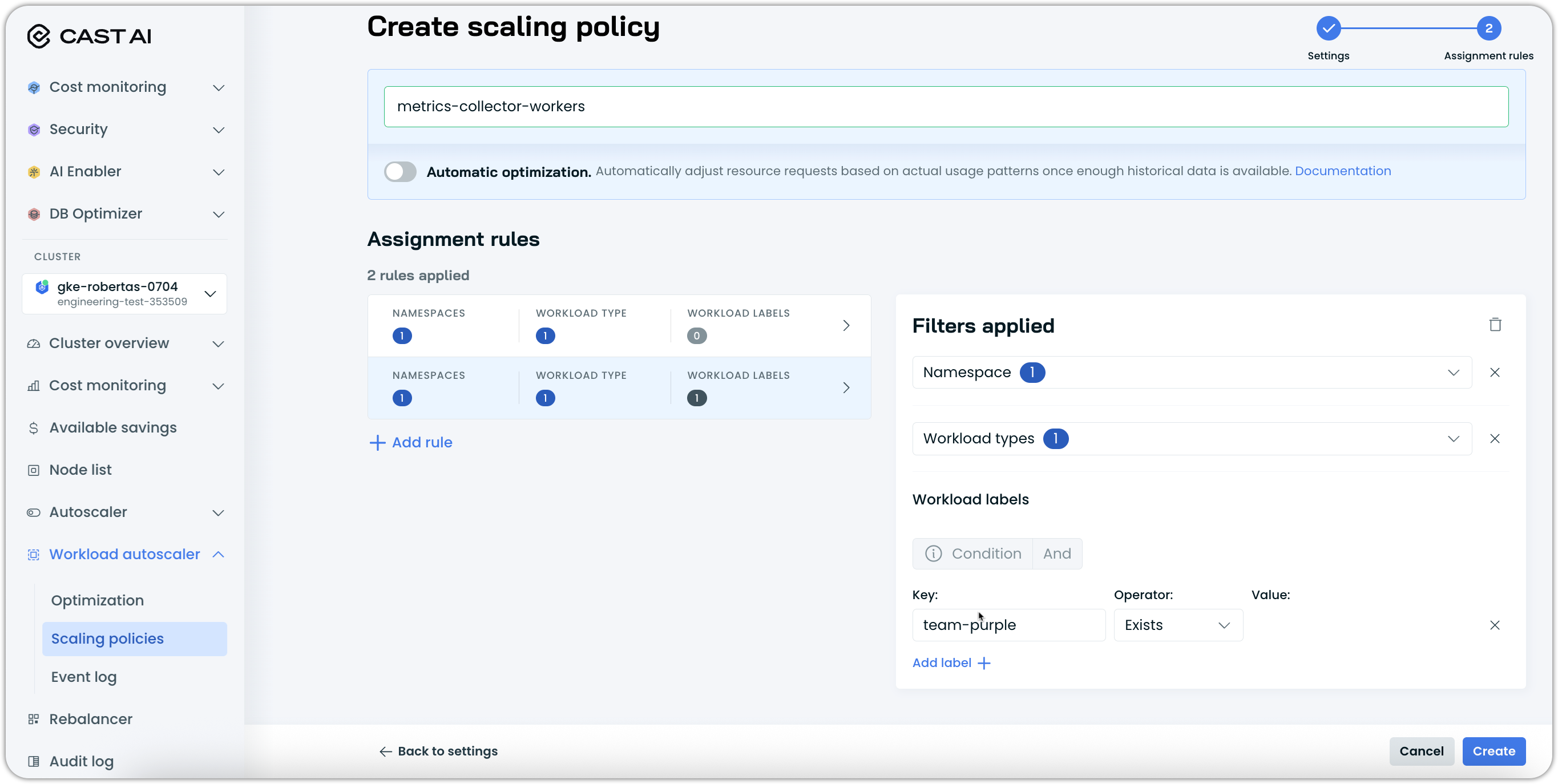
Assignment rules support sophisticated label expressions including existence checks, regex matching, and value-based filtering. This allows teams to create highly specific policies that automatically capture workloads.
The feature is available through the console interface, API, and Terraform provider, enabling both interactive policy creation and Infrastructure as Code workflows.
For detailed configuration examples and rule syntax, see our Scaling Policies documentation.
In-Place Resizing Support for Workload Autoscaler
The Workload Autoscaler now supports Kubernetes in-place resource resizing for clusters running Kubernetes v1.33+, enabling resource adjustments without pod restarts for improved application availability and reduced optimization overhead. This feature allows workloads to have their CPU and memory requests dynamically adjusted while maintaining continuous operation.
Key capabilities:
- Zero-downtime optimization: Resource requests can be adjusted without pod restarts, maintaining application availability during optimization
- Intelligent memory handling: Automatic protection against memory limit reduction during downscaling to prevent potential application issues, following Kubernetes best practices
- Kubernetes-native integration: Leverages the standard Kubernetes in-place resizing API for compatibility across different cluster configurations
This is valuable for production workloads where minimizing disruption is critical, while still achieving the cost and performance benefits of continuous resource optimization.
See Kubernetes documentation or Workload Autoscaler documentation for more information on in-place resizing.
CronJob Support
The Workload Autoscaler now natively supports CronJob optimization. This addition enables resource optimization for periodic and scheduled workloads alongside existing support for other workload types. This extends the Workload Autoscaler's coverage to a broader range of Kubernetes workload types.
Reduced Minimum Lookback Period
The minimum lookback period for Workload Autoscaler has been reduced to 3 hours, accommodating customer requests for faster optimization cycles in environments with shorter, predictable usage patterns.
Single Replica Handling with Zero-Downtime Updates
Workload Autoscaler now supports Single Replica Handling, providing zero-downtime updates for single-replica workloads. This capability allows seamless service continuity during resource adjustments by temporarily running a new replica alongside the existing one. Once the new pod is healthy, the original is removed—ensuring uninterrupted service during scaling actions.
Highlights:
- Enables zero-downtime updates for single-replica deployments
- Supported via annotations and scaling policies
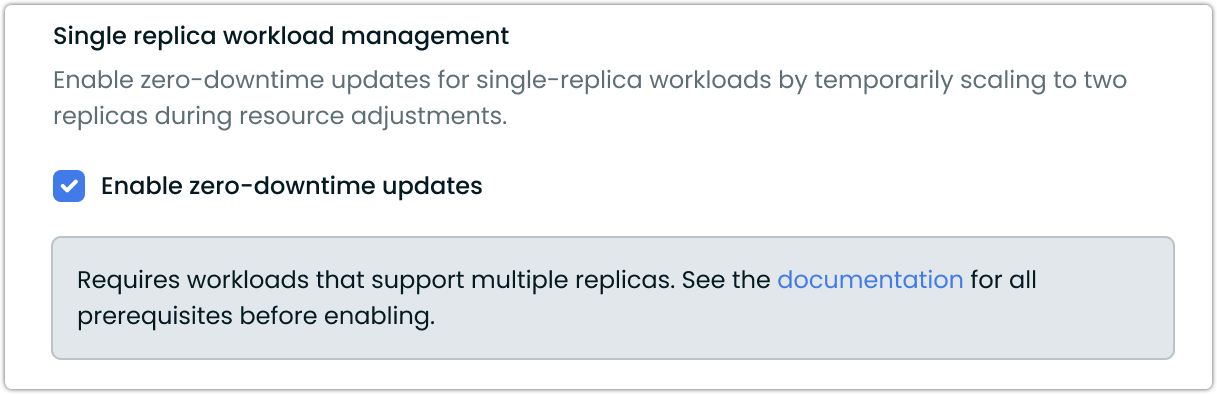
For setup details and requirements, see our documentation.
Immediate Apply Mode for Custom Workloads
The Workload Autoscaler now automates resource updates for custom workloads that use rolling update controllers like ReplicaSets and StatefulSets. This means resource recommendations can be applied immediately without requiring manual restarts, reducing downtime and simplifying workload management.
For more information on supported controllers and other requirements, see our documentation.
Native ReplicaSet Support
The Workload Autoscaler now provides native support for ReplicaSet resources, extending optimization capabilities beyond already supported Kinds. ReplicaSets can now be directly optimized with both immediate and deferred scaling modes.
Job-Like Custom Workloads Support
Cast AI's Workload Autoscaler now allows users to mark custom workloads as job-like, differentiating them from long-running applications. This distinction addresses the unique behavior of job-like workloads, which run sporadically for short durations and then vanish, such as Spark executors, GitLab runners, and workflow engines.
Key benefits:
- Faster confidence building with only 3 runs required within the configured look-back period
- Retains recommendation Custom Resource Definitions (CRDs) in the cluster during the entire look-back period, even when no pods are running, preventing premature removal
- Auto-detects common job-like workloads, including Tekton TaskRuns, Argo Workflows, GitLab runner pods, and Apache Spark workloads based on specific annotations and labels
- Supports manual marking of workloads as job-like via labels and annotations for additional custom workloads
- Allows overriding auto-discovery to mark workloads as continuous if needed
This update ensures job-like workloads are managed with proper timing and lifecycle strategies, improving recommendation accuracy and preventing inconsistencies.
For configuration details and examples, see our documentation.
Dynamic Change Sensitivity for Scaling Policies
The Workload Autoscaler now supports dynamic change sensitivity settings, improving when resource recommendation changes are applied to your workloads. With dynamic sensitivity, the minimum threshold that triggers an update automatically adapts based on each workload's size. This ensures that smaller workloads avoid frequent unnecessary updates, while larger workloads can benefit from more precise, meaningful optimizations.
Highlights:
- Dynamic sensitivity (recommended): Adjusts thresholds automatically for each workload, minimizing disruptions and tuning optimizations without manual intervention
- Percentage sensitivity: Applies the same fixed threshold percentage to all workloads—best for environments where workloads are uniform in size
- Simulation: Visualizes how the dynamic threshold scales as resource requests grow, making it easy to see exactly when an update will be triggered for a given workload
- Advanced tuning: Power users can further customize thresholds via annotations, including independent settings for CPU and memory or custom algorithm parameters
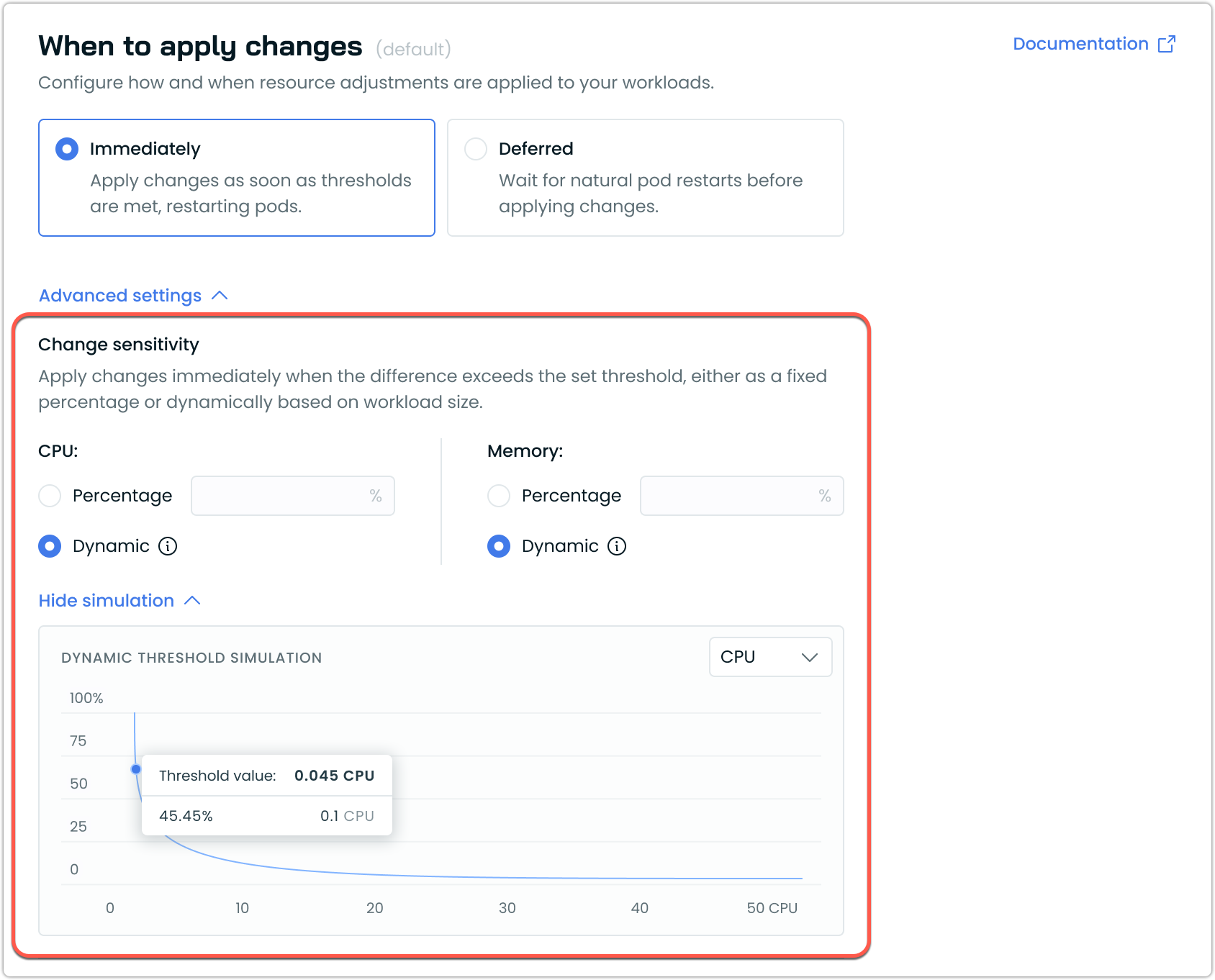
This enhancement helps users maintain optimal performance and cost efficiency with less guesswork or maintenance. Dynamic sensitivity is available through scaling policy settings in the Workload Autoscaler UI, with additional configuration options for advanced users via annotations.
For more information, see our documentation on workload autoscaling configuration.
Improved Handling of OOMKilled StatefulSet Pods
Starting from Workload Autoscaler version 0.51.0, Workload Autoscaler has improved the reliability of recovering StatefulSet pods that have been terminated due to Out-Of-Memory (OOM) kills. Previously, recovery from OOM kills in StatefulSet pods was often unpredictable, causing operational challenges and increased support cases.
With this update, Workload Autoscaler will actively attempt to evict OOMKilled StatefulSet pods that fail to restart cleanly. Pod Disruption Budgets (PDBs) still protect your pods, but customers can also choose to enable evictions for unhealthy StatefulSet pods by configuring the unhealthyPodEvictionPolicy in the PDB specification.
This new approach helps teams running resilient StatefulSet workloads recover faster from memory-related pod failures and significantly enhances cluster stability.
Configurable Resource Limits
The Workload Autoscaler now offers flexible options for handling existing resource limits, including the ability to preserve current limit configurations. This addresses customer requirements to maintain the existing limits while still benefiting from resource request optimization.
Key options:
- Remove existing limits: Eliminates resource limits to prevent throttling and improve performance (recommended approach)
- Keep existing limits: Preserves current limit configurations unchanged during optimization
- Custom multiplier: Applies configurable multipliers to automatically adjust limits relative to optimized requests
- Automatic limits: Sets limits to 1.5x requests when limits are low, with unchanged limits when they already exceed this threshold
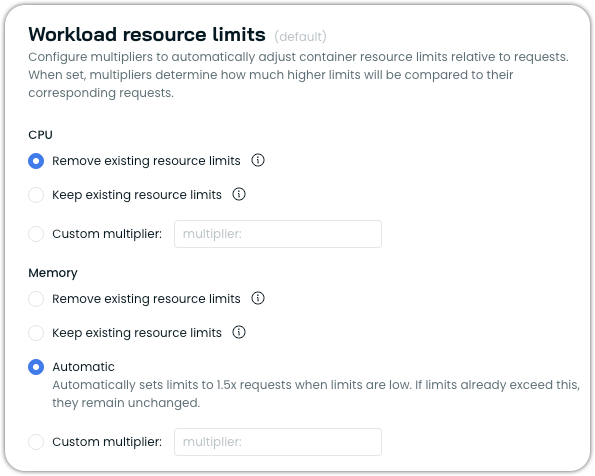
This flexibility allows customers to adopt workload optimization while respecting existing internal policies or performance requirements that mandate specific limit configurations.
Enhanced Evictor Support for Deferred Workload Recommendations
The Evictor now accounts for pending Workload Autoscaler recommendations when generating rebalancing plans. This prevents scenarios where nodes are provisioned that can't accommodate updated pod resource requests, avoiding unnecessary node provisioning and improving resource allocation accuracy.
DaemonSet Resource Detection for Node Provisioning
The node provisioning process now accounts for DaemonSet resource requests that have been modified by Cast AI's Workload Autoscaler or third-party optimization tools. This prevents node sizing loops and improves cluster stability when DaemonSets have dynamically updated resource requirements.
The system now considers both deferred and applied workload recommendations to make better provisioning decisions.
Node Configuration
Auto-Generated Node Templates
Node template creation now includes an auto-generation feature that provides intelligent template suggestions based on cluster workload analysis. This simplifies node template configuration by automatically recommending optimized templates tailored to specific workload requirements.
The auto-generation feature creates templates in a disabled state, allowing teams to review and customize configurations before enabling them for use in their clusters.
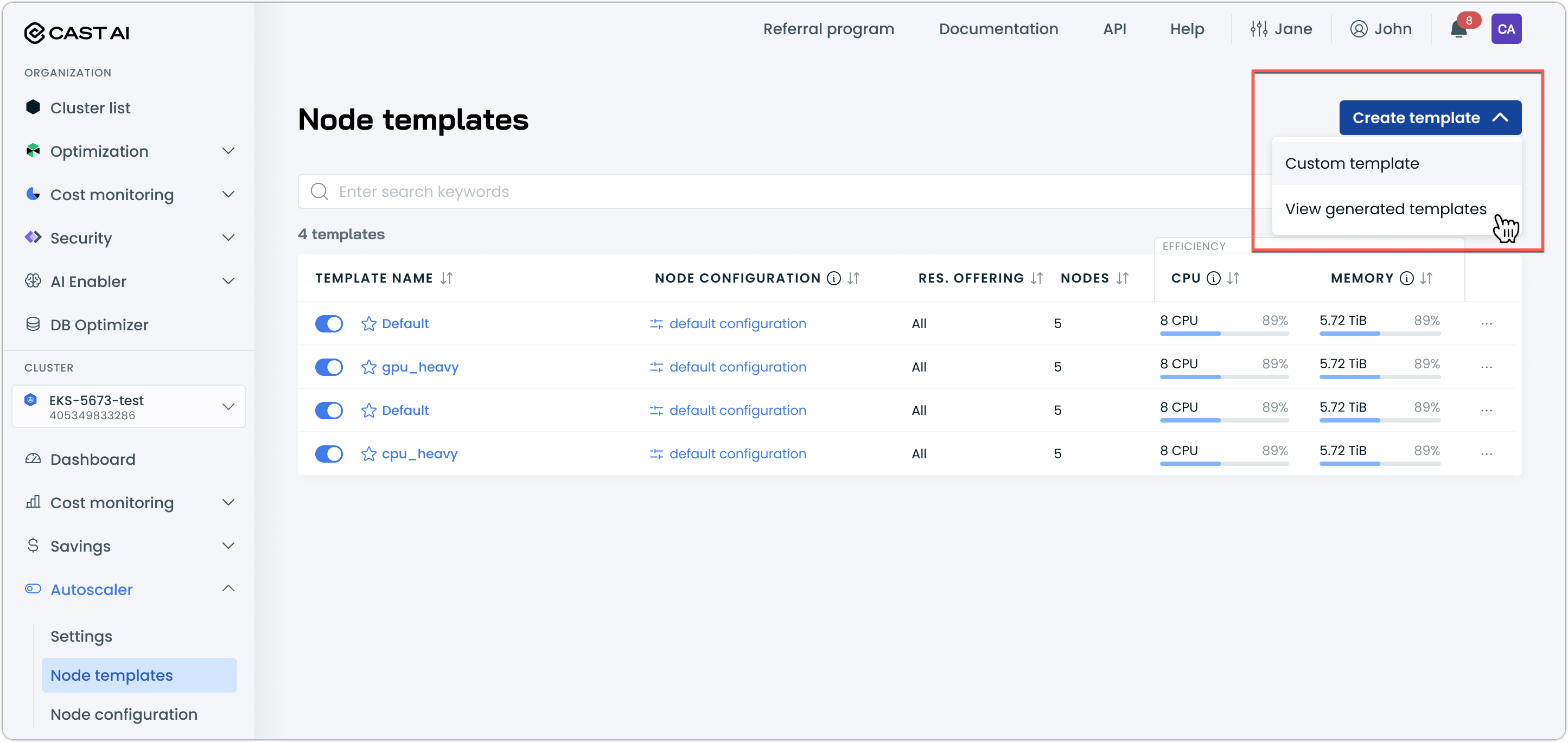
This feature is currently in Early Access. Contact your Account Manager to enable it for your organization.
EKS Node Image Update: Default to Amazon Linux 2023 for Kubernetes 1.33+
Starting with Kubernetes version 1.33, Cast AI provisions Amazon EKS nodes using the Amazon Linux 2023 (AL2023) image family by default, aligning with the EKS lifecycle policy which marks version 1.32 as the last to support Amazon Linux 2 (AL2) AMIs. This update ensures that nodes are launched with the latest supported operating system, delivering improved security, performance, and seamless integration with AWS features.
AL2023 Nodeadm Config Support with MIME Multipart Init Scripts
Cast AI now supports using Amazon Linux 2023 (AL2023) nodeadm NodeConfig via MIME multipart format in Init Scripts for node provisioning. Customers can specify detailed nodeadm NodeConfig configurations alongside traditional shell scripts within the same Init Script, providing greater flexibility and control over node initialization.
The previous Init Script behavior remains unchanged, ensuring backward compatibility.
For more details on using Amazon Linux 2023 and nodeadm NodeConfig, see our documentation.
Spot Reliability in Node Templates
Cast AI now offers Spot Reliability within Node Templates, using machine learning to select more reliable Spot Instances that are less likely to be interrupted. By analyzing historical Spot Instance data, this feature predicts and prioritizes instance types with longer average runtimes. It is meant as an alternative and later as a replacement for "Spot Diversity".
You can enable Spot Reliability when creating or updating a Node Template by setting the appropriate constraints via API or Terraform, including a maximum price increase tolerance to balance reliability with cost.
For configuration details, see our documentation.
Cloud Provider Integrations
Azure Linux 3.0 Support for AKS
Cast AI now supports Azure Linux 3.0 for AKS node provisioning, providing access to Microsoft's latest container-optimized Linux distribution with enhanced security and performance improvements.
Azure Linux 3.0 includes significant updates, bug fixes, and CVE patches compared to previous versions. The operating system can be selected through node configuration options and is automatically supported for AKS clusters running Kubernetes 1.32 and later, aligning with Azure's migration timeline where AKS will default to Azure Linux 3.0 for new cluster versions.
AWS Reserved Instance Support for Autoscaling Commitments
Cast AI now supports AWS Reserved Instances within its commitments feature, allowing the autoscaler to prioritize and use your reserved capacity efficiently. This helps maximize cost savings by automating the application of your long-term AWS commitments across clusters.
Unified Commitment Upload Process for All Cloud Providers
Commitment management now uses a consistent script-based approach across all supported cloud providers. Azure Reserved Instance (RI) commitments have transitioned from the previous CSV upload method to the same streamlined script-based solution already used for AWS and GCP.
This resolves potential issues with CSV uploads, including format inconsistencies, file size limitations, and export errors. All cloud providers now follow the same workflow: generate a script in the console with a single button, run it in your cloud shell or terminal, and commitments are automatically imported into Cast AI.
Cluster Onboarding
Cloud Connect: Easy Cluster Discovery and Onboarding
Cast AI's Cloud Connect feature simplifies cluster onboarding by discovering your GKE and EKS clusters with a quick script run in your cloud shell. This lets you view all of your clusters right in the Cast console, and select the ones you want to install the Cast AI agent to for automation.
Cloud Connect streamlines the onboarding process through an automated script that sets up required permissions for each cloud provider.
For full details, see Cast AI's documentation on getting started.
AI Enabler
Expanded LLM Model Support and Deployment Options
Cast AI's AI Enabler continues to broaden its model ecosystem with support for additional cutting-edge language models across both self-hosted and cloud provider deployments. Recent additions expand the platform's ability to automatically route requests to the most cost-effective and performant models for each specific use case.
Enhanced deployment capabilities:
- Self-hosted model expansion: Added vLLM deployment support for additional models, including Deepseek, expanding beyond the existing Ollama deployment options for greater flexibility in model hosting
- Fine-tuned model integration: Improved testing and registration capabilities for organizations deploying custom fine-tuned models in their infrastructure
Intelligent routing improvements:
- Enhanced model routing: Expanded router training with support for numerous new models across providers, including Anthropic's Claude 3.7 and Mistral Medium 3, enabling more precise automatic model selection based on query complexity and cost optimization
- Provider lifecycle management: Handled model deprecation across multiple providers, ensuring seamless transitions when models are retired or updated
This continued expansion ensures teams have access to the latest AI capabilities while maintaining cost efficiency through Cast AI's automated model selection and Kubernetes optimization. Note that the models and providers mentioned represent examples of broader support additions across the AI model ecosystem.
Self-Hosted Model Autoscaling with Hibernation and Fallback
The AI Enabler now supports autoscaling for self-hosted model deployments, including automatic hibernation during low usage periods and fallback to external SaaS providers when needed.
Key benefits:
- Replica-based scaling: Configure minimum and maximum replica counts with automatic scaling based on traffic demand and GPU utilization metrics
- Intelligent hibernation: Automatically hibernate model deployments to zero replicas during periods of inactivity to minimize GPU costs
- SaaS fallback integration: Route requests to external model providers when self-hosted models are unavailable or scaling, ensuring continuous service availability
- Configurable scaling metrics: Scale based on request volume, GPU cache usage, or custom performance thresholds
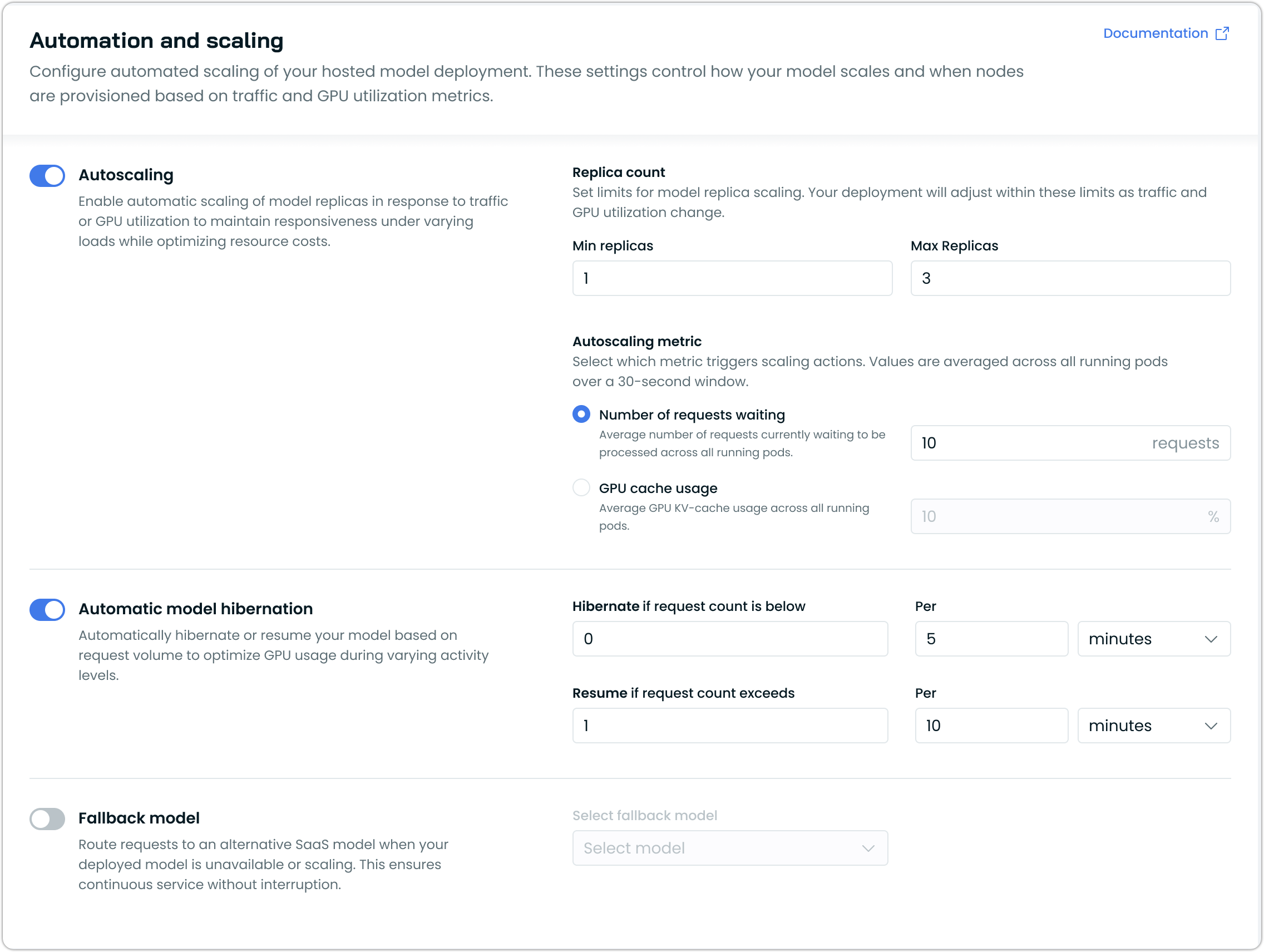
This functionality is accessible through both the model deployment interface and post-deployment configuration settings, allowing teams to optimize their self-hosted model infrastructure as needed.
Database Optimizer
MySQL Database Support
Database Optimizer (DBO) now supports MySQL databases alongside existing PostgreSQL capabilities. Organizations can connect MySQL instances through the same onboarding process, extending Cast AI's database optimization features to a wider customer base.
Infrastructure as Code
Runtime Security Support in Terraform Provider
The Terraform provider now includes support for enabling and configuring Cast AI's Runtime Security features. This allows teams to deploy Kvisor security agents and configure runtime monitoring capabilities as part of their automated cluster provisioning workflows.
Key capabilities:
- Complete Kvisor configuration: Deploy both Kvisor controller and agent components with customizable security feature settings
- Runtime security: Configure eBPF events, file hash enrichment, netflow monitoring, and other runtime security features through Terraform variables
- Flexible configuration options: Support for granular security feature control, including image scanning, Kubernetes benchmarking, and runtime event monitoring
The implementation includes comprehensive examples for EKS, AKS, and GKE deployments, making it easier to incorporate security configurations.
For detailed configuration examples and security feature options, see the updated Cast AI Terraform provider documentation.
User Interface Improvements
CSV Export for Cluster Lists
A new CSV export option allows you to download cluster list data directly from the console. The export includes all visible cluster metrics with clean formatting - measurement units in headers and bare values for easy analysis in external tools.
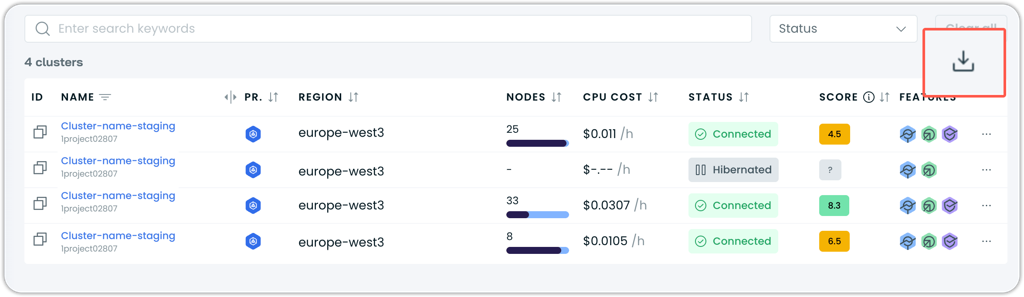
The export button is located in the top-right corner of the cluster list for easy access.
Pod Mutations Audit Logging
Pod mutation operations are now tracked in the audit log, providing visibility into when and how workload configurations are modified. This improves transparency and troubleshooting capabilities for pod mutation workflows.
The audit log captures detailed information about mutation events, including which mutations were applied, the affected workloads, and the specific configuration changes made.
Interactive Charts with Zoom and Line Toggle
Chart visualization across the platform has received significant usability improvements, starting with Workload Autoscaler and expanding to other areas. Charts now support intuitive zoom functionality and selective data line visibility for enhanced data analysis.
New chart capabilities:
- Click-and-drag zoom: Zoom into specific time periods or data ranges by simply clicking and dragging on any chart area for detailed analysis
- Legend-based line toggling: Click summary items in chart legends to show or hide specific data lines, particularly useful when outliers make other metrics difficult to view
These improvements are currently available in Workload Autoscaler charts, with Database Optimizer charts in development. The improved chart functionality will gradually expand to reporting charts and other visualization areas across the platform.
Available Savings Experience Refresh
The Available Savings report has received a major user experience update, now available under a feature flag.
Highlights:
- Refreshed, consolidated report design for clearer insights and easier navigation
- Potential savings percentage and figures are now always visible—no matter where you are in the optimization process
- Savings insights from the Workload Autoscaler are included if it's installed, with details showing which workloads are contributing
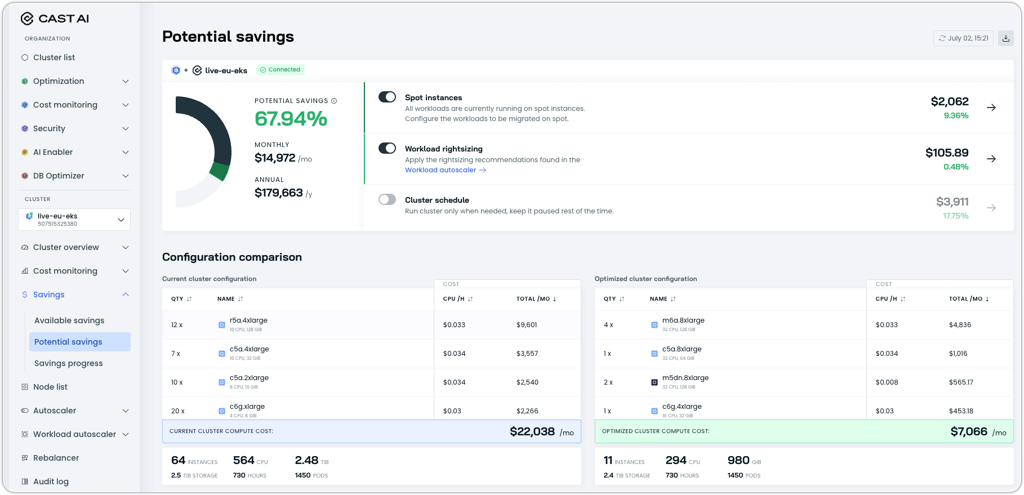
Explore the new experience and share your feedback, as the old version will be phased out in upcoming releases.
Component Control: Centralized Dashboard for Cast AI Components
Cast AI has introduced Component Control, which is a unified dashboard for managing all Cast AI components across your connected Kubernetes clusters. With this centralized interface, you can monitor health, update, and troubleshoot every Cast AI component from a single location, replacing the need to juggle multiple tools.
Component Control provides:
- An at-a-glance summary of component health across your organization
- Detailed installation and status information for each component, with easy access to update or remediation commands for fast resolution
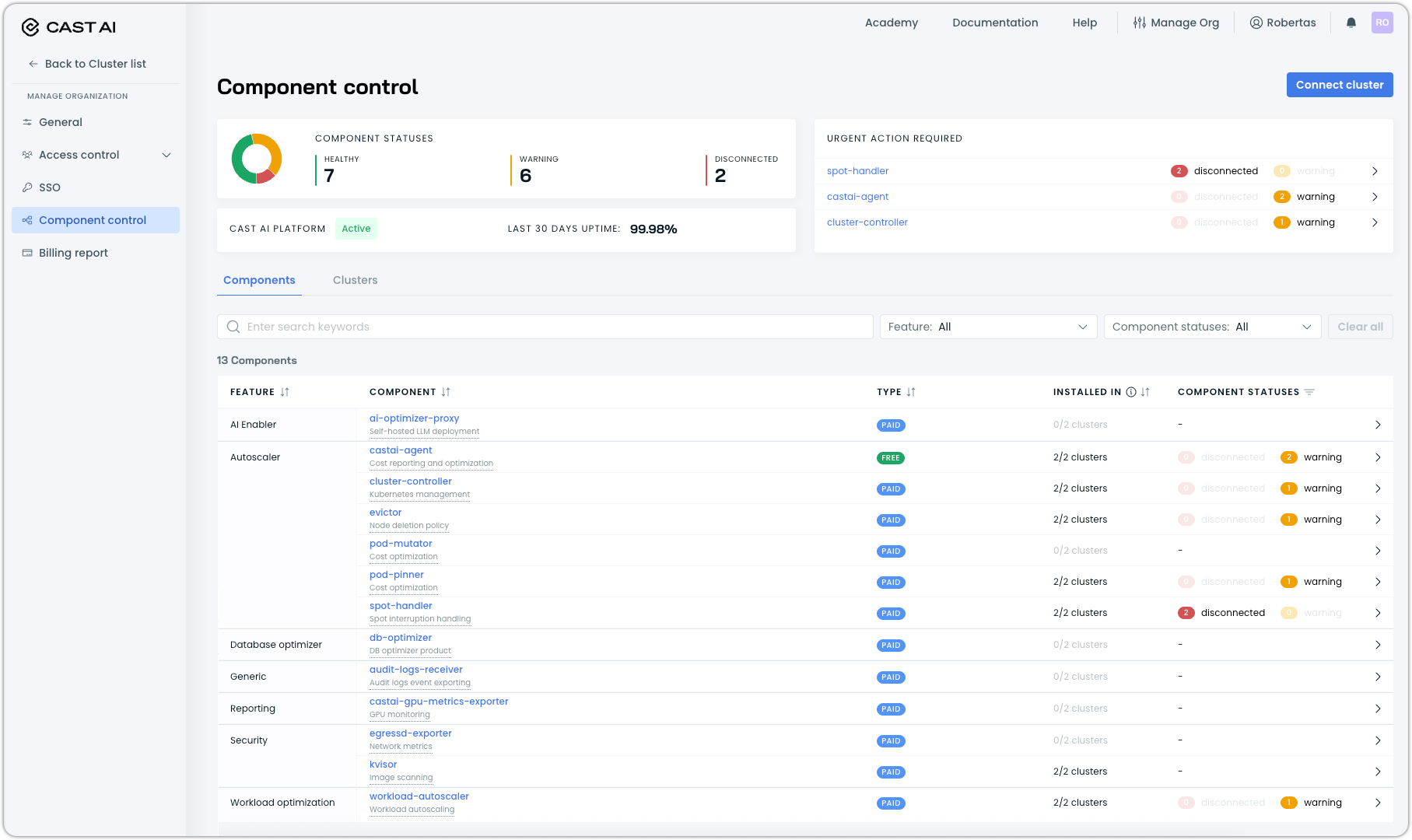
This streamlined view ensures you stay on top of your Cast AI ecosystem, proactively maintaining cluster health and accelerating troubleshooting.
To learn about all of the capabilities of this feature, see our documentation.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are ready for use in your infrastructure as code projects in Terraform's registry.
We have released a new version of the Cast AI agent. The complete list of changes is here.