
February 2025
Upgraded RBAC System, Database Optimization for PostgreSQL, and Advanced Workload Controls
Major Features and Improvements
Upgraded Role-Based Access Control System
The platform-wide Role-Based Access Control (RBAC) system has received a comprehensive upgrade, delivering enterprise-grade access management capabilities while maintaining a streamlined user experience. This significant enhancement addresses key requirements for organizations that are managing complex multi-team environments.
Key improvements include:
- Cluster-Level Permissions: Access management can now be configured at the individual cluster level, not just organization-wide, allowing for more precise control and team-specific access patterns
- Service Account Management: Create dedicated authentication credentials for automation systems, CI/CD pipelines, and external integrations, each with precisely defined permissions and independent lifecycle management
- User Groups: Simplify administration by organizing users into logical groups based on roles, teams, or responsibilities, then manage permissions at the group level
- Refined Role Definitions: More granular and consistent permission sets across all platform areas, providing predictable access patterns regardless of feature
For detailed guidance and best practices for leveraging the new capabilities, see our RBAC documentation.
Manual Database Onboarding for Postgres
Database Optimizer (DBO) now supports manual onboarding of PostgreSQL databases from any hosting environment. This allows organizations to leverage Cast AI's database optimization capabilities regardless of where their PostgreSQL instances are deployed.
This flexibility extends Cast AI's database optimization offering beyond cloud-managed services to include self-hosted instances, databases in private data centers, and third-party PostgreSQL hosting providers. While performance insights are currently optimized for AWS RDS instances, caching capabilities are available for all PostgreSQL deployments.
Be sure to check out the documentation to get started with Postgres onboarding if you're interested.
Reporting and Cost Optimization
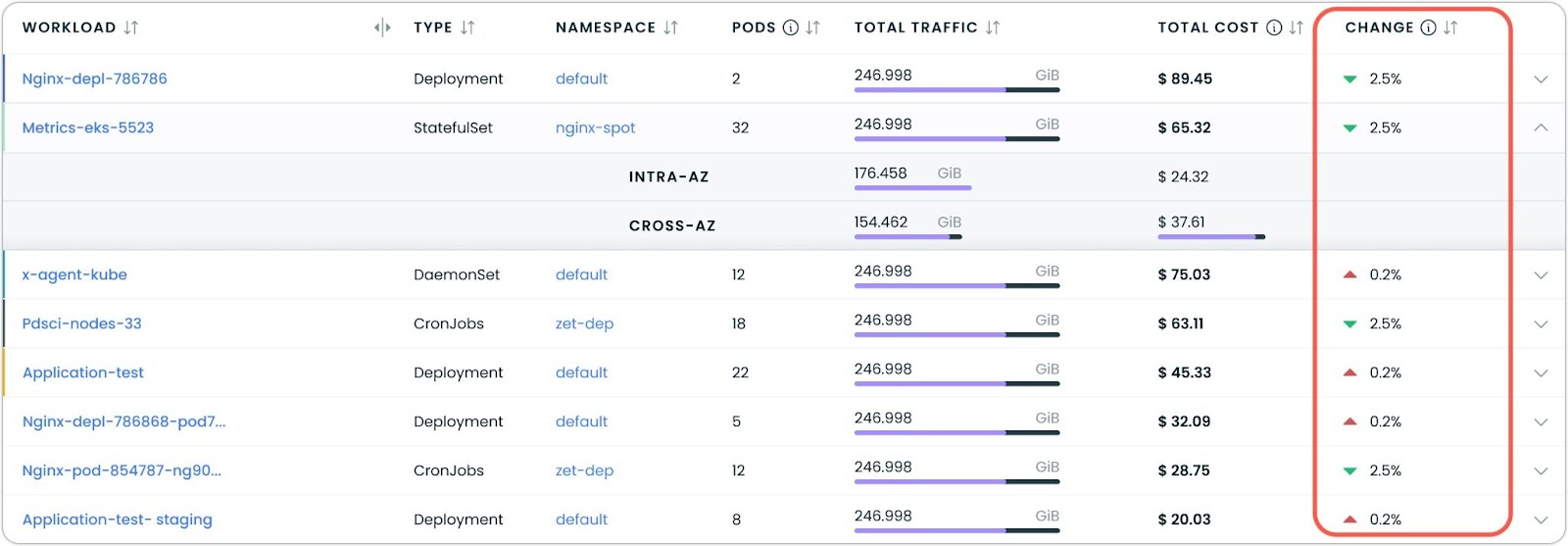
Percentage Change in Workload Cost Reports
Workload cost reports now include a percentage change indicator that shows how costs have evolved over time. This new column provides immediate visibility into cost trends, letting you see at a glance whether individual workload expenses are increasing or decreasing compared to the previous period.
Workload Optimization
Immediate Resource Adjustment for OOM Events
Out-of-memory events now trigger the latest resource recommendations to be applied regardless of configured thresholds when the immediate mode is configured for memory events. This ensures faster recovery for memory-constrained workloads by bypassing the standard threshold after an OOM event occurs.
Configure the workload autoscaler to handle memory events immediately to have this behavior.
For more information about configuring workload restart behavior, see our Workload Autoscaler documentation.
Policy-Level Resource Constraints for Workload Autoscaler
The Workload Autoscaler now supports setting resource boundaries at the scaling policy level, providing more efficient management of autoscaling guardrails across multiple workloads. This allows administrators to define common CPU and memory min/max thresholds once and apply them consistently to groups of workloads.
These boundaries act as guardrails within which automatic scaling can occur, ensuring that autoscaling recommendations stay within acceptable ranges while still allowing individual workload-specific optimizations. This capability is particularly valuable for large-scale deployments where maintaining consistent resource governance across dozens or hundreds of workloads is essential.
The feature is available through the Cast AI Console, API, and Terraform provider.

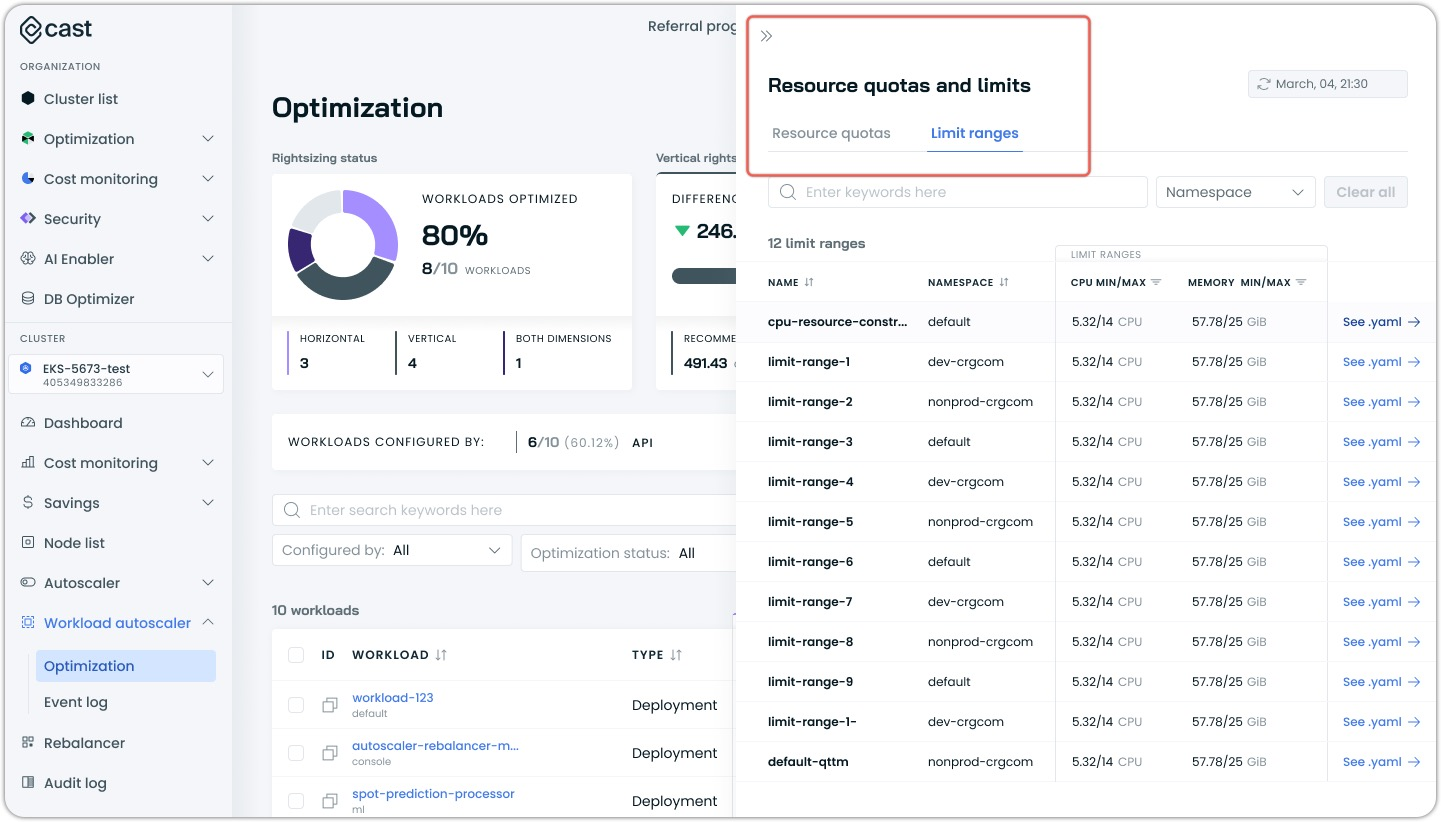
Resource Quotas and Limit Ranges Visibility
Kubernetes resource constraints are now visible directly in the Cast AI console, providing insight into resource quotas and limit ranges that affect workload optimization.
The system collects and displays these Kubernetes-native constraints in a dedicated interface, allowing users to quickly identify potential conflicts between optimization recommendations and namespace policies. Resource ranges are presented in an intuitive table format with filtering options by namespace.
For each limit range, the console shows both CPU and memory constraints along with quick access to the underlying YAML definitions. This transparency helps ensure optimization actions respect existing governance guardrails within the cluster.
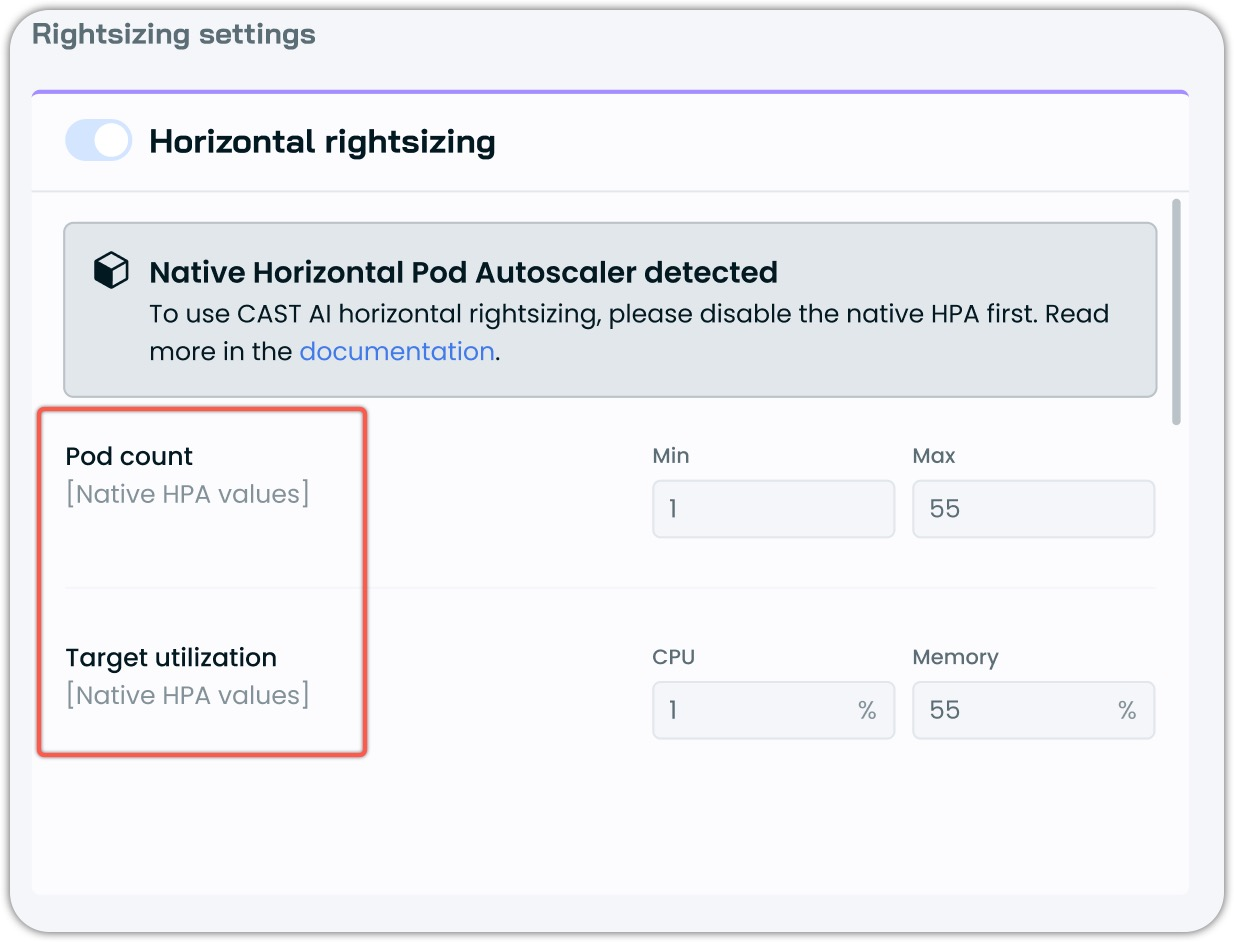
Native HPA Configuration Visibility
Ever wonder what your native Horizontal Pod Autoscaler is configured to do? The console now displays these settings directly in the workload autoscaler interface, exposing critical configuration details that were previously hidden.
When native HPA is detected, the system reveals both pod count parameters and target utilization thresholds for CPU and memory. These values appear alongside Cast AI's own configuration options, creating a complete picture of how autoscaling behaves in your environment.
Cast AI Anywhere
Simplified Price Management for Cast AI Anywhere
The cluster onboarding process now features improved price configuration handling for Cast AI Anywhere. Default pricing is automatically applied during onboarding, eliminating the need for manual price configuration in many scenarios.
This ensures consistent cost visibility from the moment clusters are connected while allowing for customization when needed. The system handles price updates through a unified process, maintaining accurate cost calculations throughout the cluster lifecycle.
If you have not yet had the chance to see how Cast can be used on any cluster, anywhere -- be sure to visit the Cast AI Anywhere documentation to see how straightforward it is to get started (yes, you can use Minikube!).
Cloud Provider Integrations
FIPS Compliance Support for AKS GovCloud
Azure Kubernetes Service (AKS) clusters in GovCloud environments can now utilize FIPS-compliant nodes through a simple configuration option. This allows government and regulated industry customers to meet Federal Information Processing Standard (FIPS) requirements while benefiting from Cast AI's optimization capabilities.
The node configuration interface now includes a FIPS enablement option that automatically configures the appropriate gallery base images and necessary system components. When enabled, all provisioned nodes will use FIPS-validated cryptographic modules, ensuring compliance with federal security standards.
Enhanced Subnet Capacity Diagnostics
Scaling failures due to subnet capacity constraints now provide more detailed diagnostic information. When a cluster cannot scale due to IP address limitations, the system captures and displays comprehensive information about the affected subnet, including available IPs, maximum capacity, and specific subnet identifiers.
These enhanced diagnostics appear both in pod events visible through the Cast AI Console and in system logs. For multi-subnet environments, the information clearly identifies which specific subnet has reached capacity, enabling faster resolution of networking constraints.
Node Configuration
Expanded EKS DNS Configuration with IPv6 Support
We've expanded the DNS cluster IP configuration options for Amazon EKS clusters to support both IPv4 and IPv6 address formats. This enables proper DNS resolution configuration in dual-stack and IPv6-only clusters.
The dns-cluster-ip field in node configuration now accepts IPv6 addresses, allowing users to override the default DNS cluster IP with either address format.
For detailed configuration options, see our Node Configuration documentation.
GKE Secondary IP range Support
To support advanced pod networking use cases, we have released support for a secondary IP range on Cast AI-created node pools in GKE clusters. This feature is currently implemented in API and Terraform and is available behind a feature flag.
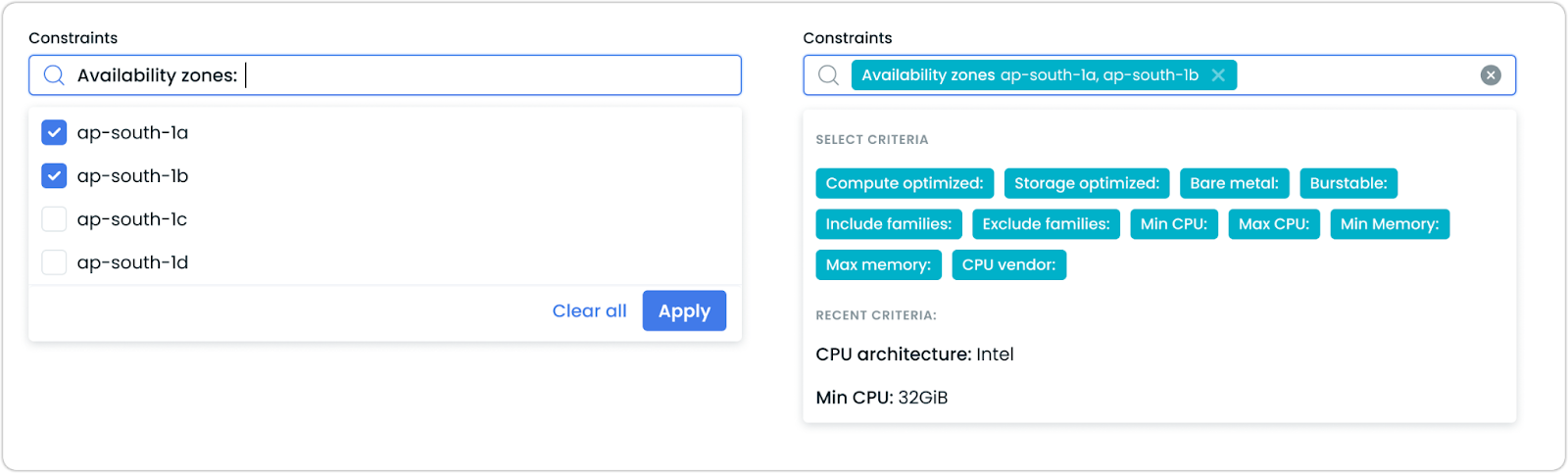
Availability Zone Selection in Node Templates
Node templates now feature explicit availability zone selection capabilities across all supported cloud providers. This gives precise control over where Cast AI provisions nodes, supporting specific availability requirements.
The availability zone selection is accessible when creating or editing node templates, with support for all major cloud providers including AWS, Azure, and Google Cloud.
For more information on configuring node templates with availability zone constraints, visit our documentation.
CPU Limits for Node Templates
Template-specific CPU limits have arrived, bringing finer resource control to specialized workload environments. Unlike cluster-wide restrictions, these limits operate at the template level, creating boundaries that apply only to nodes launched from that specific template.
When configuring templates, users now see CPU limit options alongside existing constraints.
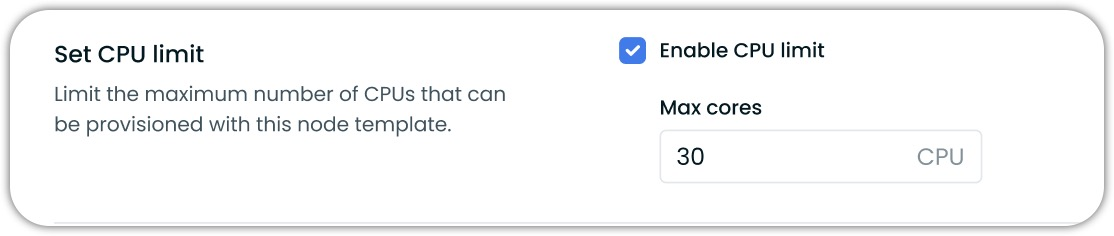
The system generates clear pod events when scheduling is prevented by these limits, helping teams understand resource constraints during deployment. Both the console interface and Terraform support this feature, fitting seamlessly into existing workflows.
This highly-requested feature addresses feedback from organizations needing more targeted control over infrastructure costs and resource allocation.
Pod Mutations
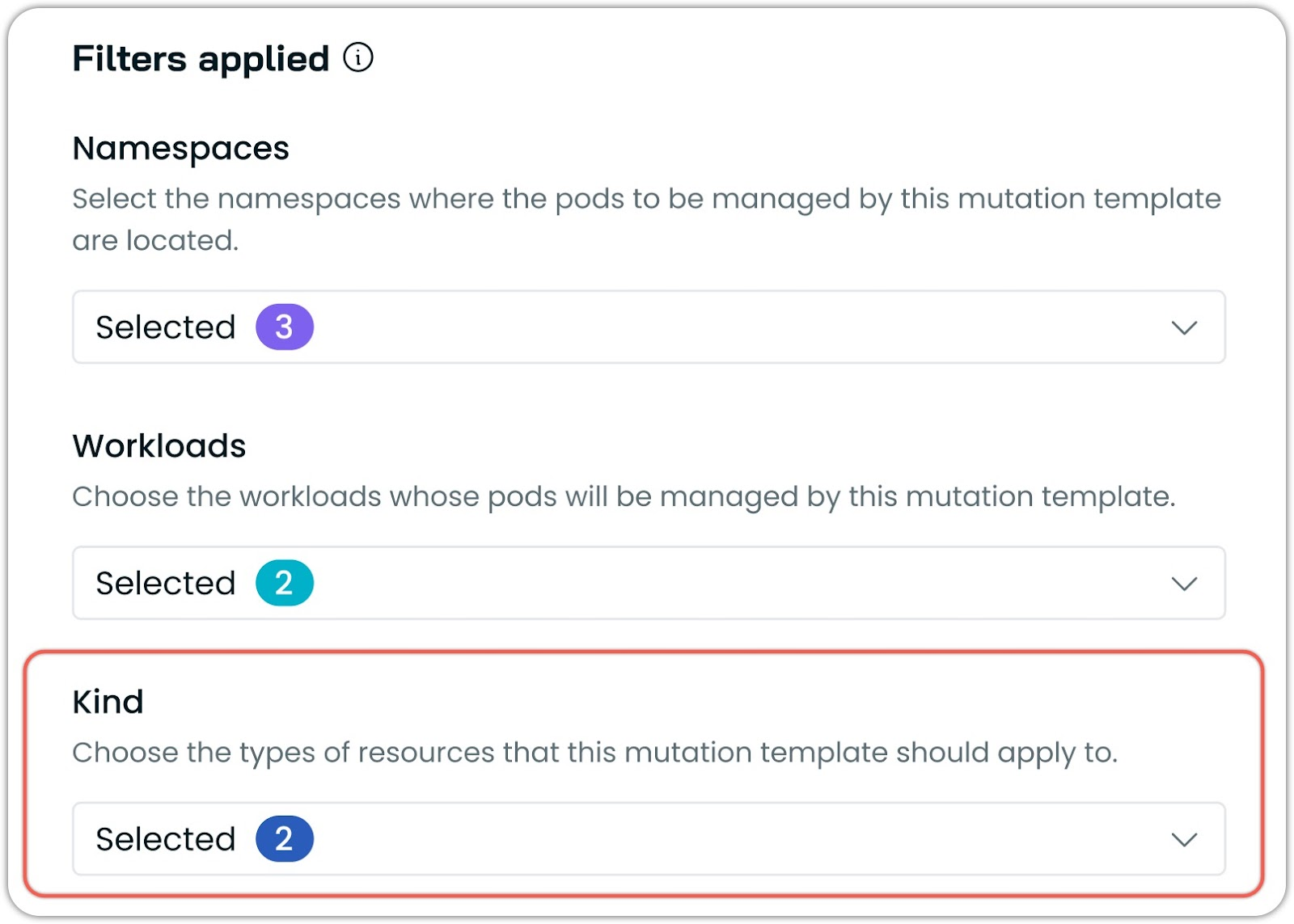
Resource Kind Filtering for Pod Mutations
Pod mutations now support filtering by Kubernetes resource kinds, enhancing the precision of pod template modifications. This allows to target specific resource types such as Deployments, StatefulSets, DaemonSets, or Jobs when applying mutations.
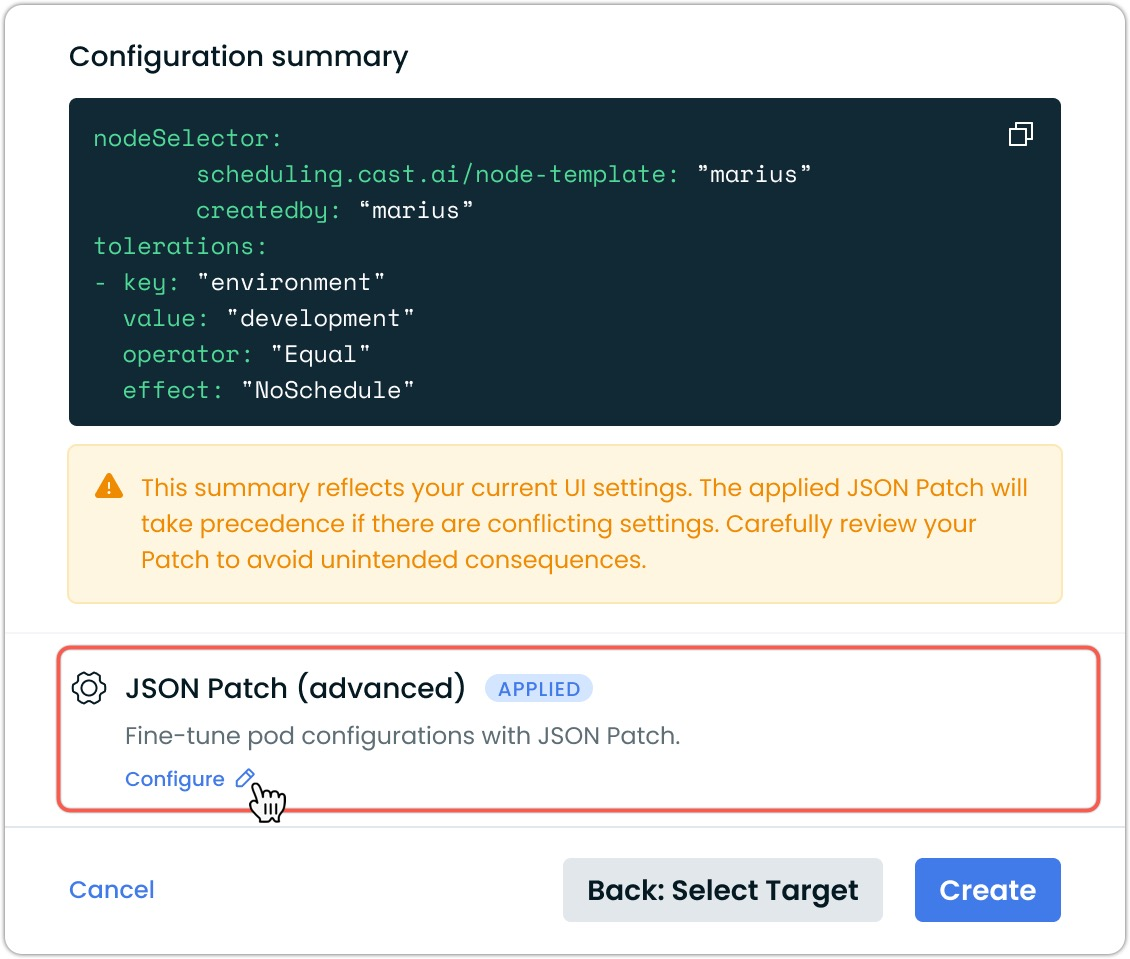
Advanced Pod Mutations with JSON Patch
Pod Mutations now support JSON Patch operations, giving precise control over complex pod specifications beyond what standard UI options provide. This powerful capability enables targeted modifications to virtually any field in the pod specification through standard JSON Patch operations.
JSON Patch allows for sophisticated pod transformations including:
- Adding or removing specific node selectors and tolerations
- Modifying affinity rules with exact precision
The feature is available through an intuitive editor in the Pod Mutations interface, where users can define sequences of patch operations to be applied in order. Each operation targets a specific path in the pod specification.
Head over to Pod Mutations documentation for some guidance and examples on how to begin patching your pod configurations today.
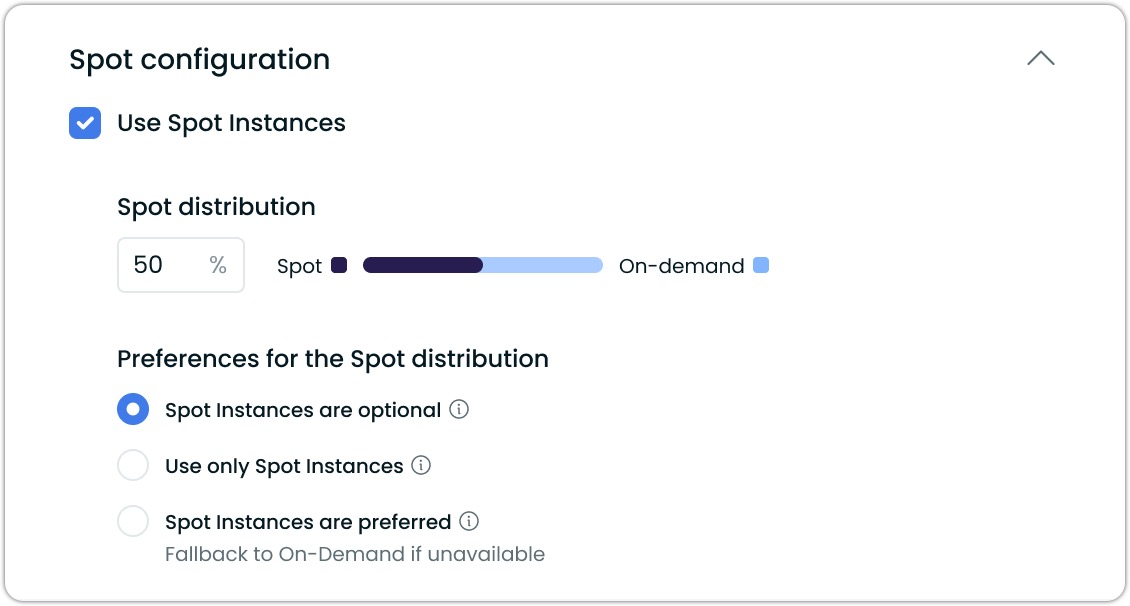
Custom Spot/On-Demand Distribution in Pod Mutations
Pod mutations now support percentage-based distribution between spot and on-demand instances. This highly requested feature gives administrators precise control over workload placement across different instance types.
When configuring mutations, users can specify both the desired distribution percentage and instance behavior. Three spot modes are available: "optional" for maximum flexibility, "use-only" for strict enforcement, and "preferred" for automatic failover to on-demand when needed.
For example, a 75% spot distribution with preferred mode would target three-quarters of pods to Spot Instances while maintaining the remaining quarter on on-demand nodes, with automatic rebalancing during instance availability changes.
Kubernetes Security
Network Flow Analytics with Kubernetes Context
A new Netflow analytics capability brings comprehensive network visibility with rich Kubernetes context. The intuitive interface features interactive time-series graphs that visualize traffic patterns, making it easy to spot anomalies and bandwidth spikes between workloads.
The intuitive interface supports powerful querying through Common Expression Language (CEL), enabling administrators to quickly identify cross-zone traffic, internet-bound connections, or unexpected communication patterns. Dynamic grouping options allow for flexible analysis by workload, namespace, node, or process.
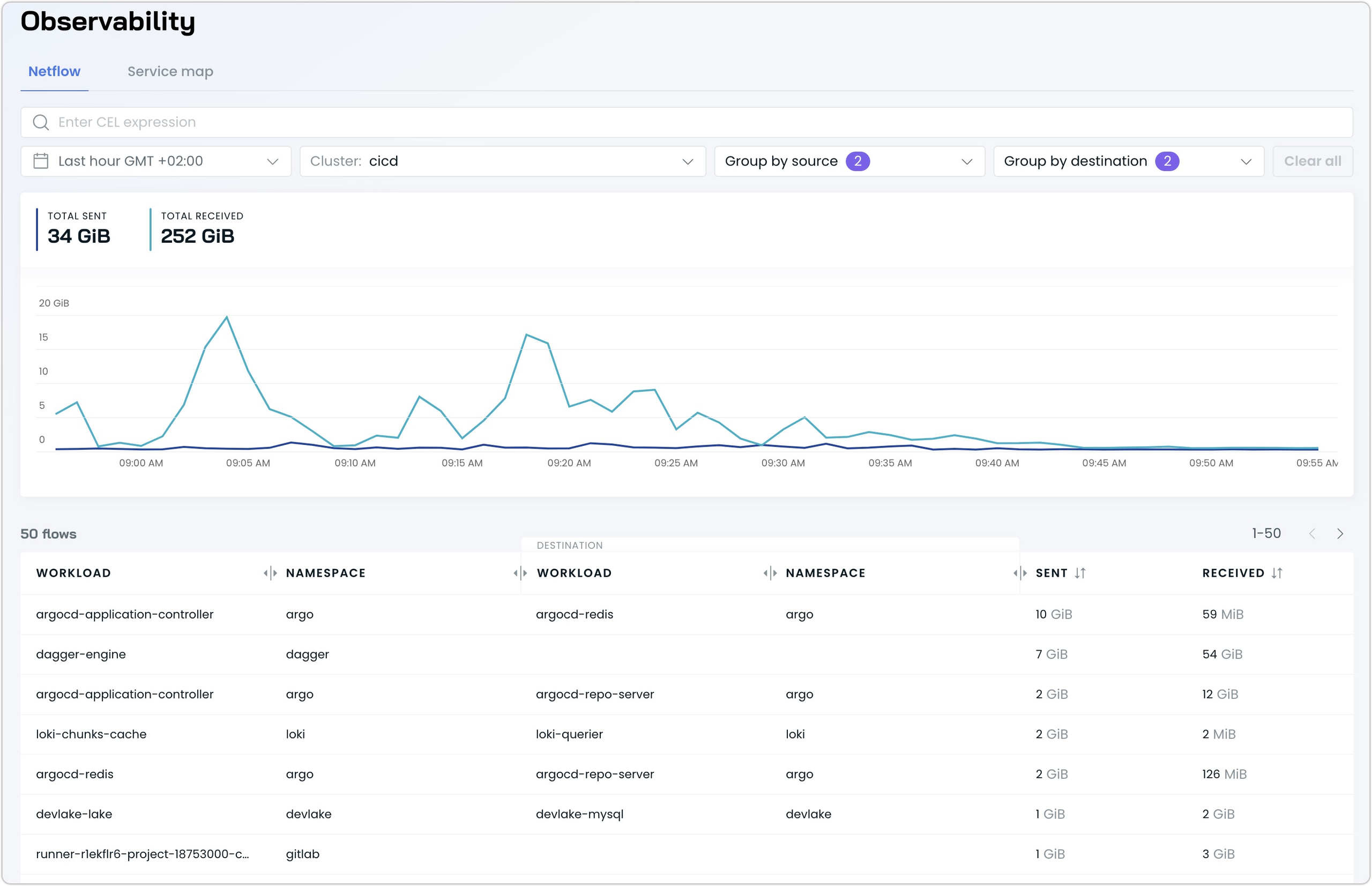
Key use cases include:
- Identifying bandwidth-intensive cross-zone traffic
- Monitoring outbound internet connections
- Troubleshooting unexpected network flows
This capability is implemented through the Cast AI Kvisor agent and can be enabled with a simple Helm chart configuration. The feature is currently available behind a feature flag.
For detailed configuration options and query examples, see our Network Observability documentation.
AI Enabler
Support for Latest LLM Models
The AI Enabler now supports an expanded selection of cutting-edge language models, including Anthropic's Claude 3.5 Haiku (20241022), OpenAI's o1, and DeepSeek's R1 Distill Llama 70B. These additions ensure access to the most advanced capabilities for your AI applications, including improved reasoning, increased reliability, and enhanced performance.
VRAM Requirement Calculation for Self-Hosted Models
AI Enabler now includes automatic VRAM requirement calculation for self-hosted large language models. This new capability helps organizations accurately determine GPU memory needs before deploying models, ensuring proper hardware allocation and preventing out-of-memory errors.
The system uses model size and quantization information to calculate required VRAM. These calculations account for model weights, KV cache requirements, and overhead needed for efficient inference, providing reliable estimates for hardware planning.
DeepSeek-R1 Model Deployment Support
The AI Enabler now supports deploying DeepSeek-R1 models directly within your Kubernetes clusters using Ollama. This integration allows organizations to run these high-performance models in their own infrastructure while maintaining control over data and resources.
DeepSeek-R1 joins the growing list of supported self-hosted model options, expanding the platform's flexibility for organizations seeking to balance performance, cost, and data governance requirements. The deployment process follows the same streamlined workflow as other supported models.
For detailed deployment instructions and configuration options, see our AI Enabler Hosted Model Deployment documentation.
Improved Support for Structured JSON Output
The AI Enabler proxy now correctly handles structured output formats when working with OpenAI models. This resolves an issue where requests specifying a structured response format would fail when routed through the proxy, even though they worked correctly when sent directly to the provider.
This ensures compatibility with application code using Pydantic models for response formatting through libraries like LiteLLM or the OpenAI SDK. Client applications can now specify structured JSON outputs through either direct provider connections or the AI Enabler proxy without modifying their code.
User Interface Improvements
Enhanced Event Log for Scaling Policies
The Workload Autoscaler event log now includes comprehensive tracking for scaling policy lifecycle events. This expanded visibility provides clear documentation of all policy-related actions, including creation, assignment, modification, and deletion.
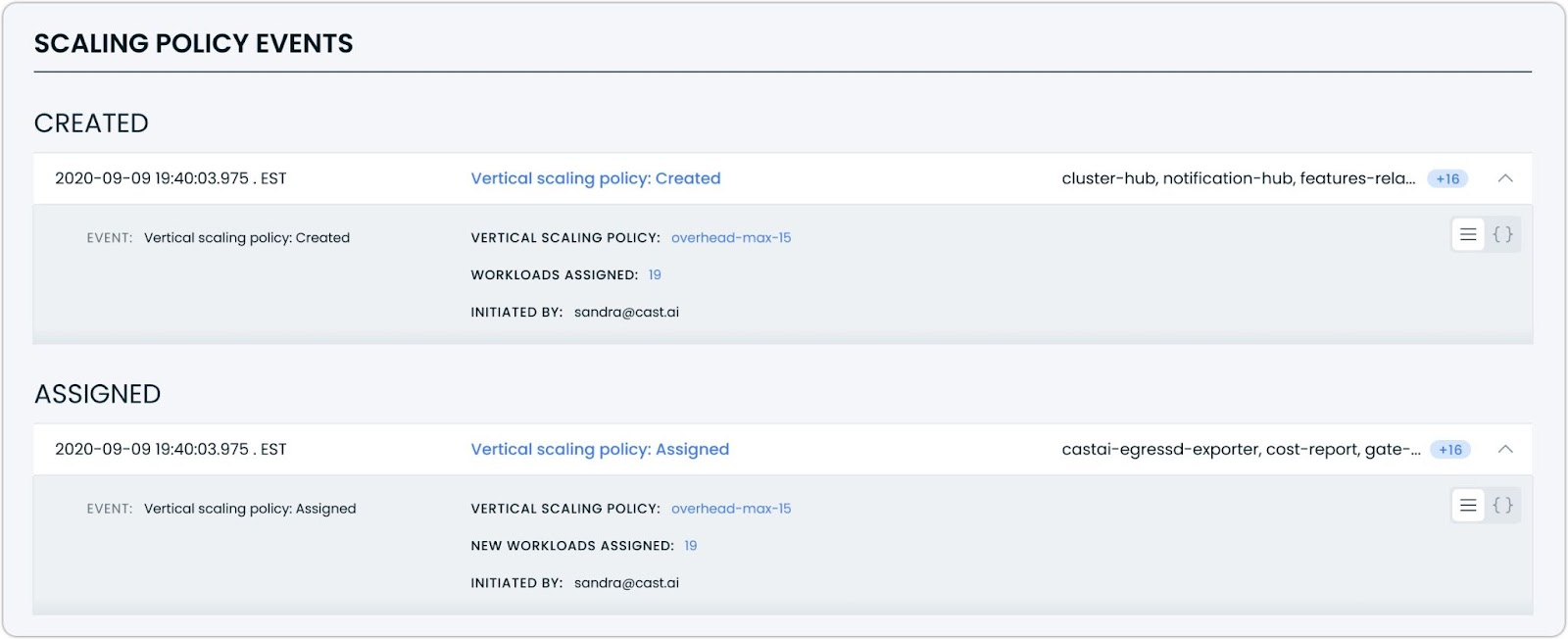
Each event type displays relevant contextual information:
- Policy creation events show workload counts, policy name, and initiator
- Assignment events display newly affected workloads
- Edit events reveal before-and-after comparisons of policy settings
- Deletion events document policy removal with timestamp and initiator details
The expanded event log makes it easier to understand who made changes, what was modified, and which workloads were affected.
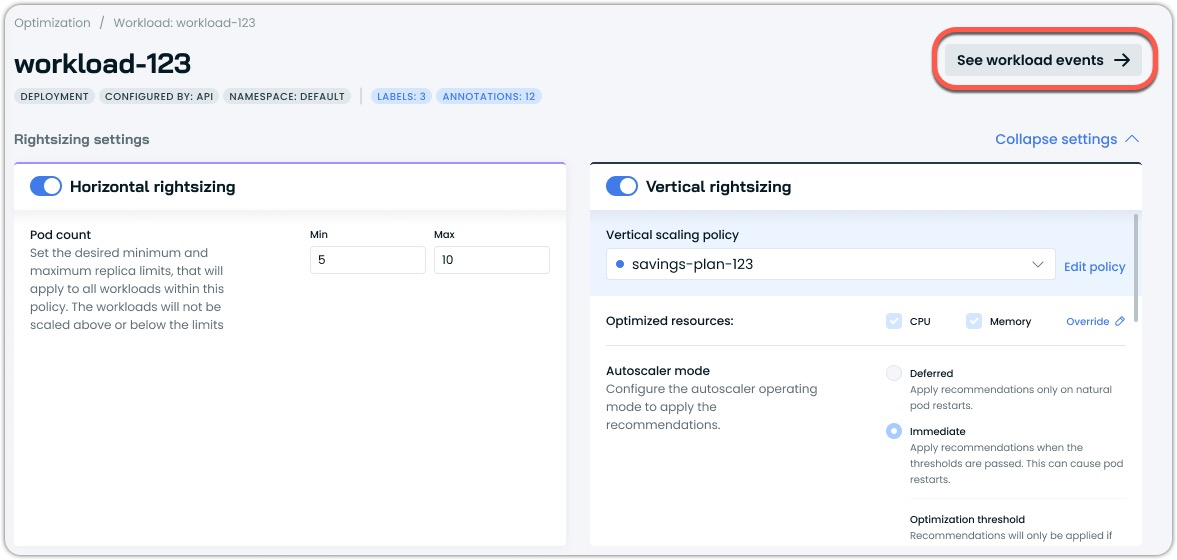
Improved Workload Event Visibility
A new "See workload events" button has been added to the workload view, providing direct access to filtered event logs specific to that workload. This improvement makes troubleshooting and monitoring individual workloads more efficient by eliminating manual filtering steps.
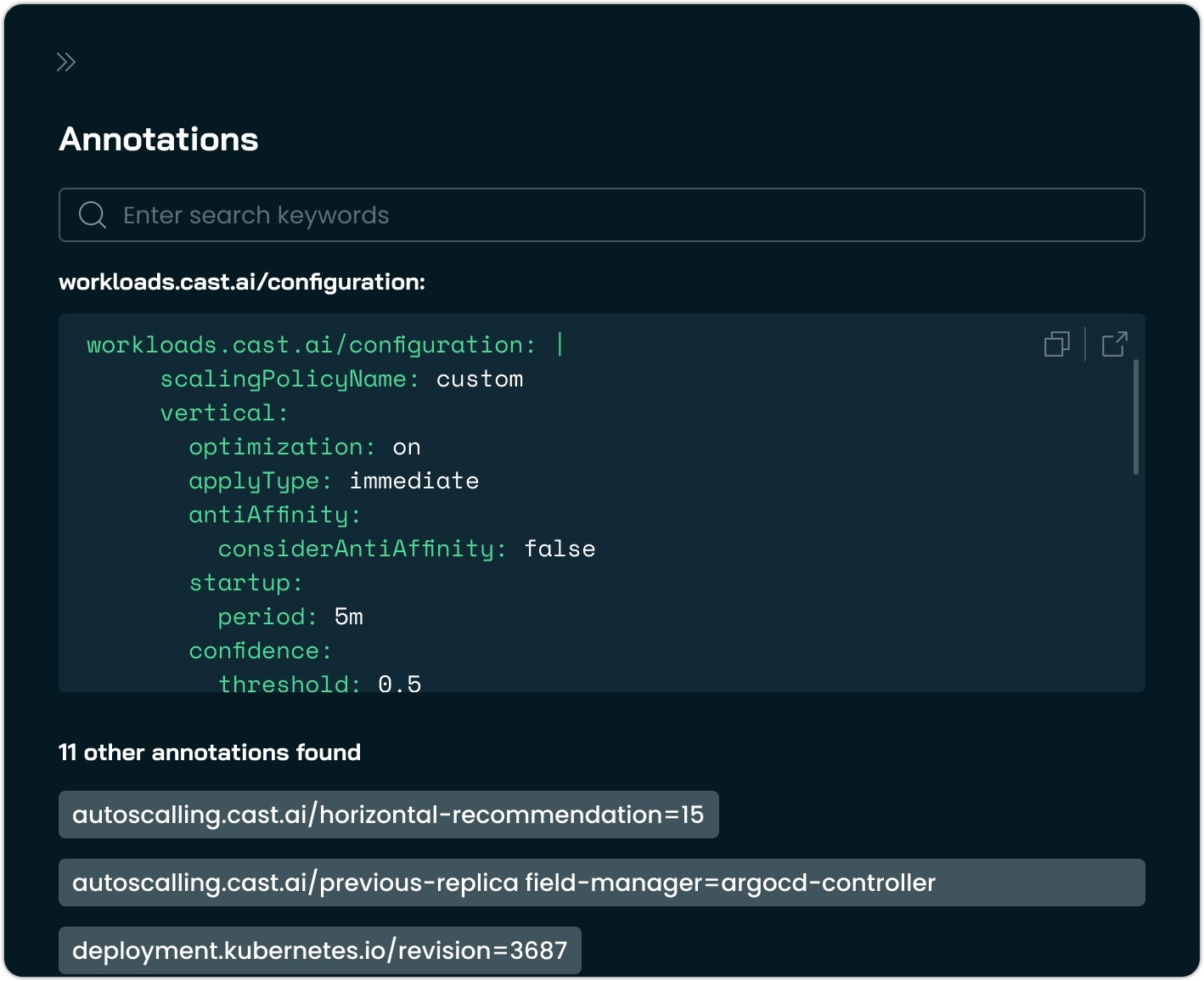
Reworked Annotations View for Workload Autoscaler
A redesigned annotations view brings clarity to workload autoscaling configurations. The interface now properly displays the consolidated annotation structure, where all configuration parameters are grouped under a single workloads.cast.ai/configuration annotation instead of scattered across multiple keys.
The new view presents the YAML configuration in a syntax-highlighted editor for improved readability, while also listing other annotations present on the workload. This makes it easier to understand complex scaling configurations and troubleshoot potential conflicts between settings.
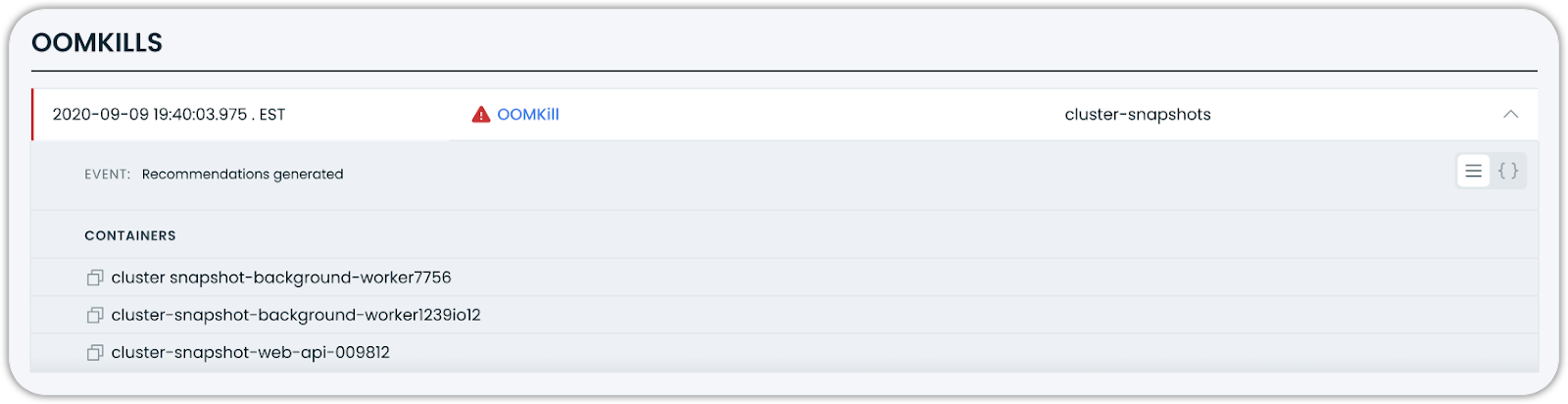
Enhanced OOM Kill Event Visualization
The event log now provides more detailed information about Out-of-Memory (OOM) kill events, helping better understand and respond to memory-related failures. When containers are terminated due to memory constraints, the system displays the affected containers with clear indicators.
This improvement makes it easier to identify which specific containers within a pod were terminated during an OOM event, supporting faster troubleshooting and more informed resource allocation decisions.
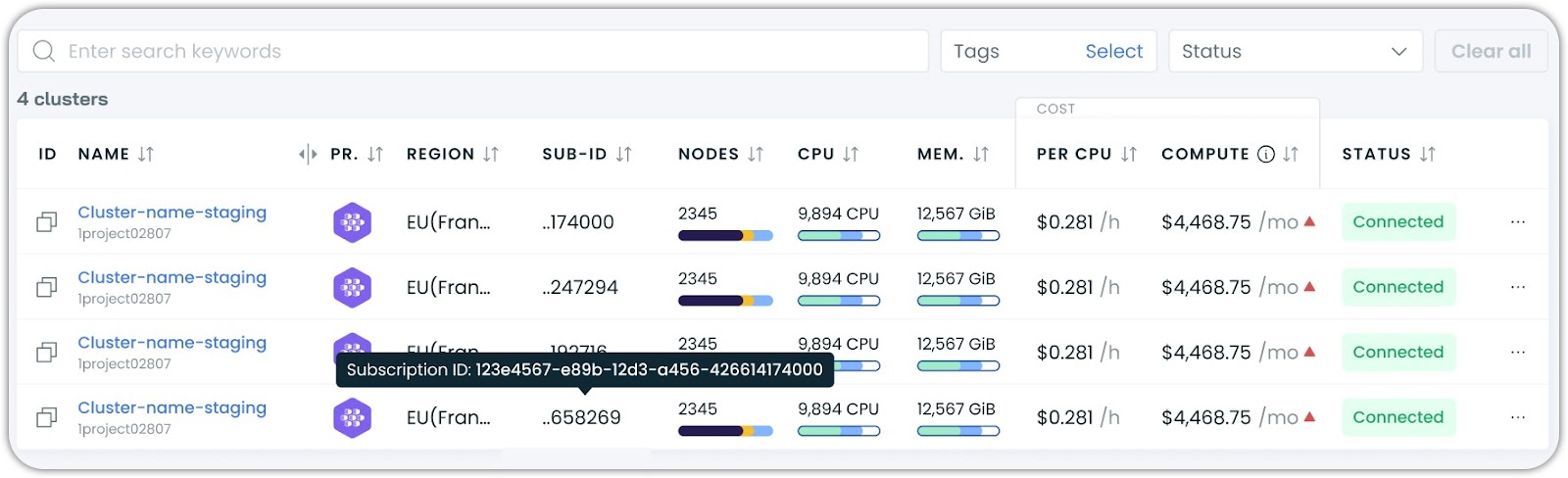
Azure Subscription ID Column in Cluster List
The cluster list now includes an optional column displaying Azure subscription IDs for AKS clusters. This makes it easier for organizations managing multiple Azure subscriptions to quickly identify and navigate between clusters based on their subscription context.
Infrastructure as Code
Improved Access to Workload Autoscaler Helm Chart
Finding and retrieving the Workload Autoscaler Helm chart is now more straightforward, with expanded documentation and improved discoverability. The chart can be accessed through the Cast AI Helm repository with several flexible options to fit different workflows.
Users can obtain the chart using standard Helm commands. Direct download via curl is also supported for environments without Helm CLI access. Comprehensive instructions are now available in the GitHub repository.
Component Updates
PriorityClass Support for Spot Handler
The Spot Handler Helm chart now supports configuring PriorityClass for its pods, ensuring proper scheduling priority in resource-constrained environments. This allows to configure appropriate scheduling priorities, ensuring this critical component is properly prioritized by the Kubernetes scheduler.
Adding PriorityClass support brings the Spot Handler component in line with other Cast AI components, creating consistency across the platform. The configuration is available through the values.yaml file, making it easy to integrate with existing deployment workflows and GitOps practices.
Terraform and Agent Updates
We've released an updated version of our Terraform provider. As always, the latest changes are detailed in the changelog on GitHub. The updated provider and modules are ready for use in your infrastructure.
We have released a new version of the Cast AI agent. The complete list of changes is here.