
Node configuration
What is Node configuration?
The Cast AI provisioner allows you to set node configuration parameters that the platform will apply to provisioned nodes. Node configuration on its own does not influence workload placement. Its sole purpose is to apply user-provided configuration settings on the node during the provisioning process.
A cluster can have multiple Node Configurations linked to various Node Templates. However, you can select only one node configuration, which Cast AI Autoscaler will use as the default.
Note
You can link node configuration to multiple node templates, but one node template can have just a single node configuration link.
You can manage node configurations via UI:Autoscaler->Node configuration, API or Terraform.
Shared configuration options
The following table provides a list of supported cloud-agnostic configuration parameters:
| Configuration | Description | Default value |
|---|---|---|
| Root volume ratio | CPU to storage (GiB) ratio | 1 CPU: 0 GiB |
| Initial disk size | The base size of the disk attached to the node | 100 GiB |
| Image | Image to be used when building a Cast AI provisioned node. See virtual machine image choice below for cloud-specific behaviors. | The latest available for Kubernetes release, based on an OS chosen by Cast AI |
| SSH key | Base64-encoded public key or AWS key ID | "" |
| Subnets | Subnet IDs for Cast AI provisioned nodes | All subnets pointing to NAT/Internet Gateways inside the cluster's VPC |
| Instance tags | Tags/VM labels to be applied on Cast AI provisioned nodes | "" |
| Kubelet configuration | A set of values that will be added or overwritten in the Kubelet configuration | JSON {} |
| Init script | A script to be run when building the node | bash "" |
Instance type compatibility and limitations
When configuring nodes in Cast AI, certain instance types may have limitations or specific requirements based on their underlying hardware architecture and features. Understanding these limitations is crucial for proper cluster configuration.
Instance Type Identification
You can identify instance types and their underlying architecture through:
- Cloud Service Provider (CSP) documentation for each instance family
- Instance type naming patterns
- CLI commands, which vary for each CSP
AWS Nitro System
The AWS Nitro System is Amazon's virtualization infrastructure that provides enhanced networking, high-performance storage, and improved security features. Instance types based on the Nitro system have different capabilities compared to non-Nitro instances.
AWS Bottlerocket Images
Bottlerocket is a Linux distribution designed and optimized for container orchestration. It contains only the essential components required for this purpose, minimizing the attack surface and enforcing container best practices.
Bottlerocket has specific instance type requirements and limitations.
Note
When using Bottlerocket AMIs, ensure your node templates include only Nitro-based instance types. Non-Nitro instances are not supported and will fail to provision.
EKS-specific subnet rules
Note
In EKS only subnets which match one of the rules below are allowed to be added to Node Configuration:
- association with a route table that has a 0.0.0.0/0 route to Internet Gateway, it's known as a public subnet. Subnet also must have "MapPublicIpOnLaunch: true" set
- association with a route table that has a 0.0.0.0/0 route to Transit Gateway, it's known as a private subnet
- association with a route table that has a 0.0.0.0/0 route to NAT Gateway, it's known as a private subnet
If CAST AI cannot detect a routable subnet (a subnet that has access to the Internet), you can add a tag
cast.ai/routable=trueto the subnet. Cast AI will then consider a subnet with this tag as having Internet access.
Some configuration options are cloud provider-specific. See the table below:
EKS-specific configuration options
| Configuration | Description | Default value |
|---|---|---|
| Security groups | Security group IDs for nodes provisioned in Cast AI. | Tagged and Cast AI SG |
| Instance profile ARN | This is the instance profile ARN for Cast AI provisioned nodes. It is not recommended that you share this profile with EKS-managed (shared) node pools. | cast-<cluster-name>-eks-<cluster-id> (only the last 8 digits of the cluster ID) |
| Dns-cluster-ip | Override the IP address to be used for DNS queries within the cluster. Supports both IPv4 and IPv6 formats. | "" |
| Container runtime | Container runtime engine selection: Docker or containerd. | Unspecified |
| Docker configuration | A set of values that will be overwritten in the Docker daemon configuration. | JSON {} |
| Volume type | EBS volume type to be used for provisioned nodes. | gp3 |
| Volume IOPS | EBS volume IOPS value to be used for provisioned nodes. | 3000 |
| KMS Key ARN | Customer-managed KMS encryption key to be used when encrypting EBS volumes. | Unspecified |
| Volume throughput | EBS volume throughput in MiB/s to be used for provisioned nodes. | 125 |
| Use IMDS v1 | IMDSv1 and v2 are enabled by default; otherwise, only IMDSv2 will be allowed. (For IMDSv2 as Required use False). | True |
| Target Groups | A list of Arn and port (optional). New instances will automatically be registered for all given load balancer target groups upon creation. | Unspecified |
| Image Family | The OS family used when provisioning nodes. Possible values: FAMILY_AL2, FAMILY_AL2023, FAMILY_BOTTLEROCKET. Note: FAMILY_AL2 is being deprecated with Kubernetes v1.33. New deployments should use FAMILY_AL2023 or FAMILY_BOTTLEROCKET. | Amazon Linux 2023 (FAMILY_AL2023) for new node groups |
| Max Pods Formula | Dynamic formula to calculate the max pods restriction on the node's kubelet. See the Maximum pods formula section for tips on using this field correctly. | Unspecified (uses EKS default) |
Kubelet configuration
Note that
kubeReservedis not supported in EKS configurations.
Important: AWS is ending support for Amazon Linux 2 (AL2) with Kubernetes v1.32
Starting with Kubernetes v1.33, only AL2023 and Bottlerocket AMIs will be supported by AWS for EKS. This change has the following implications:
- New Cast AI-managed node groups already default to AL2023
- Existing AL2-based node groups won't be automatically upgraded - manual migration is required
- The upgrade deadline, based on AWS's initial guidance, is expected to be around November 2025
To prepare for this change, we recommend:
- Update your Node Configuration to use
FAMILY_AL2023orFAMILY_BOTTLEROCKETfor the Image Family setting- Test the new OS images in non-production environments first
- Plan a gradual migration of your production workloads before the deadline
Do not hesitate to contact Cast AI Customer Success for any additional guidance and support.
KMS key for EBS volume
The key that you provide for the encryption of EBS volume must have the following policy:
{
"Sid": "Allow access through EBS for all principals in the account that are authorized to use EBS",
"Effect": "Allow",
"Principal": {
"AWS": "*"
},
"Action": [
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:Encrypt",
"kms:DescribeKey",
"kms:Decrypt",
"kms:CreateGrant"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"kms:CallerAccount": "<<account_ID>",
"kms:ViaService": "ec2.<<region>>.amazonaws.com"
}
}
}
module "kms" {
source = "terraform-aws-modules/kms/aws"
description = "EBS key"
key_usage = "ENCRYPT_DECRYPT"
# Policy
key_statements = [
{
sid = "Allow access through EBS for all principals in the account that are authorized to use EBS",
principals = [
{
type = "AWS"
identifiers = ["*"]
}
]
actions = [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:CreateGrant",
"kms:DescribeKey"
],
resources = ["*"],
conditions = [
{
test = "StringEquals"
variable = "kms:ViaService"
values = [
"ec2.${var.cluster_region}.amazonaws.com",
]
},
{
test = "StringEquals"
variable = "kms:CallerAccount"
values = [
data.aws_caller_identity.current.account_id
]
}
]}
]
# Aliases
aliases = ["mycompany/ebs"]
tags = {
Terraform = "true"
Environment = "dev"
}
}
Load balancer target group prerequisites
To use load balancer target groups with Cast AI-managed nodes, you need to:
- Configure the appropriate IAM permissions
- Specify target groups in your node configuration
Required IAM permissions
The Cast AI IAM role requires additional permissions to register and deregister nodes with target groups. Add the following IAM policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "castai-target-group",
"Effect": "Allow",
"Action": [
"elasticloadbalancing:RegisterTargets",
"elasticloadbalancing:DeregisterTargets"
],
"Resource": "arn:aws:elasticloadbalancing:<region>:<account>:targetgroup/*/*"
}
]
}
Note
- This example policy allows access to all target groups. For enhanced security, replace the wildcards
*with specific target group ARNs.- If your cluster uses IPv6, ensure your nodes have the necessary IPv6 address assignment permissions configured. See the AWS documentation for IPv6 networking and Cast AI cloud permissions documentation.
How target groups work
- When specified in the node configuration, new instances are automatically registered with the load balancer target groups upon creation
- Without proper permissions, nodes will still be created but won't be registered with target groups
- If registration fails, you'll receive a notification detailing which target groups weren't updated
Using IP prefix delegation with Cast AI
Prefix delegation mode in AWS CNI is a way to increase pod density on instances beyond the normal limits. Cast AI detects when this setting is turned on in the CNI and adjusts the calculations about subnet and node capacity accordingly. See AWS documentation for more information on how the setting affects IP address management.
If prefix delegation is used, a Maximum Pods formula should be set to properly configure the kubelet's maximum pod count. See Prefix delegation formula below for the default formula that matches AWS recommendations. This can be adjusted if needed (for example, to reserve an IP for extra ENIs on the nodes for other purposes). If the formula is not set, it is possible to see lower pod density than expected, even though there are sufficient IP slots available on the node.
Maximum Pods formula
The Maximum Pods formula dynamically determines the maximum number of pods that can run on a node in your EKS cluster. This calculation serves two primary purposes:
- It informs the
kubeletabout the maximum number of pods that can be hosted on a node. - It assists the Cast AI Autoscaler in planning and optimizing cluster resources.
You can optimize your cluster's pod distribution and resource utilization by fine-tuning this formula.
When using AWS CNI for IP address management, setting a static value for max pods directly in the kubelet configuration is not recommended. The same node configuration is usually used for different instance types, and the max pods differ per instance type. Use the Maximum Pods formula to make the value dynamic while still configuring the kubelet accordingly or remove the setting from the kubelet's configuration (the value will be calculated dynamically at node bootstrap time by default).
Formula variables
Maximum Pods formulas are constructed using the following variables:
| Variable | Description | Range/Value | Default |
|---|---|---|---|
NUM_IP_PER_PREFIX | Number of IPv4 addresses per prefix. Affects calculation when using prefix delegation. Specified as a parameter in the node configuration. | 0-256 | 1 |
NUM_MAX_NET_INTERFACES | Maximum number of network interfaces. | Instance-specific | N/A |
NUM_IP_PER_INTERFACE | Number of IPv4 addresses per interface. | Instance-specific | N/A |
NUM_CPU | Number of CPUs. | Instance-specific | N/A |
NUM_RAM_GB | Amount of RAM in GB. | Instance-specific | N/A |
Cast AI provides several preset formulas by default from which to choose.
Example formulas
The Maximum Pods formula can be tailored to different cluster configurations and requirements. Here are some common examples:
Default EKS formula
NUM_MAX_NET_INTERFACES * (NUM_IP_PER_INTERFACE - 1) + 2
This is often the default formula for EKS clusters. It calculates the maximum pods based on available network interfaces and IPs, reserving one IP per interface and adding 2 for system pods.
Prefix delegation formula
NUM_MAX_NET_INTERFACES * (NUM_IP_PER_INTERFACE - 1) * NUM_IP_PER_PREFIX + 2
This formula accounts for the additional IPs available through prefix delegation. Since the values of the formula can get unrealistically high for large instance types, Cast AI provides a preset that also puts a reasonable upper limit:
math.least((NUM_MAX_NET_INTERFACES - 1) _ (NUM_IP_PER_INTERFACE - 1) _ NUM_IP_PER_PREFIX + 2, 300)
Note
The 300-pod cap is a safeguard against node instability that can occur with extremely high pod counts. While AWS instances can theoretically support higher IP counts, running hundreds of pods on a single node can lead to resource constraints and performance issues, especially for the kubelet process. AWS's own calculator caps at 250 pods for similar stability reasons.
If your workload is specifically designed to handle higher pod densities and you have tested node stability at these counts, you can create a custom formula without this cap using the API or Terraform.
Note
AWS prefix delegation is not supported on non-Nitro instance types. If you're using prefix delegation in your cluster, ensure your node templates exclude non-Nitro instance families. This limitation applies regardless of which autoscaling solution you use, as it is an AWS-imposed limitation.
If you're not using prefix delegation, you can safely use max pods formulas (without the
NUM_IP_PER_PREFIXvariable) with any instance type.
Reserved network interface formula
(NUM_MAX_NET_INTERFACES - 1) * (NUM_IP_PER_INTERFACE - 1) + 2
This formula reserves one entire network interface.
Subtracting a network interface is also required if the pod security groups feature is used, as 1 ENI is not available for pod IP allocation in this case. See relevant AWS documentation. This applies to formulas above if the feature is used in tandem.
Fixed value
512
Simple scalar values are allowed. This example sets a fixed maximum of 512 pods per node, regardless of other factors.
These examples demonstrate the flexibility of the Maximum Pods formula. You can create custom formulas that best suit your cluster's specific needs and constraints.
How the Maximum Pods formula works
The MaxPods formula is an expression that evaluates a number. We use Common Expression Language (CEL) to evaluate it. Here is how it operates:
- Input: The formula takes the node's characteristics as input variables (e.g.,
NUM_MAX_NET_INTERFACES,NUM_CPU, scalers, etc.). - Calculation: It performs evaluation using the CEL library.
- Output: The calculation result is used as an integer. This number becomes the maximum number of pods allowed on the node.
- Application: The calculated value is used by the
kubeletto limit pod scheduling and by the CAST AI Autoscaler for capacity planning.
For example, let's break down a simple formula:
NUM_MAX_NET_INTERFACES * (NUM_IP_PER_INTERFACE - 1) + 2
If a node has 4 network interfaces (NUM_MAX_NET_INTERFACES = 4) and 10 IPs per interface (NUM_IP_PER_INTERFACE = 10), the calculation would be:
4 * (10 - 1) + 2 = 4 * 9 + 2 = 36 + 2 = 38
Thus, this node would be allowed to run a maximum of 38 pods.
The formula's flexibility allows for complex calculations that can account for various resource constraints and operational requirements. When you select or create a formula, you define the logic for this pod limit calculation.
Custom formulas
While the Cast AI Console UI provides several preset formulas for configuring an EKS node, you can define a custom formula using Terraform for more advanced configurations.
Using Bottlerocket with Cast AI
Bottlerocket is a Linux distribution designed and optimized for container orchestration. It contains only the essential components required for this purpose, minimizing the attack surface and enforcing container best practices. This section provides guidance on using Bottlerocket with Cast AI, including instructions on passing custom configurations and important considerations to remember. Useful resources are linked throughout to further understand Bottlerocket and its use cases. To start, here is a Bottlerocket overview:
Container Host - Bottlerocket - Amazon Web Services
Using Bottlerocket
You can use Bottlerocket on Cast AI by specifying the appropriate Amazon Machine Image (AMI) ID or name in Cast AI node configurations. This works out of the box for standard setups, but applying custom configurations requires a slightly different approach due to Bottlerocket's unique architecture.

Specifying the appropriate Amazon Machine Image (AMI) ID

Specifying the appropriate Amazon Machine Image (AMI) name
Limitations with Advanced Node Configuration
When using Bottlerocket AMIs, many of the fields in the advanced section of Cast AI's node configurations do not apply and cannot be used to pass custom configurations. This limitation is due to Bottlerocket's security-focused architecture, which does not provide a default shell in its container. Consequently, any changes to the AMI configuration must be passed through the settings exposed in the Bottlerocket API.
For a full list of settings available in Bottlerocket’s API, refer to the Bottlerocket Settings API Reference.
Passing Custom Configurations via Init Script
Outside of Cast AI, custom configurations are typically passed to Bottlerocket AMIs in TOML format. Here's an example:
[settings.kubernetes]
api-server = "${endpoint}"
cluster-certificate = "${cluster_auth_base64}"
cluster-name = "${cluster_name}"
${additional_userdata}
[settings.kubernetes.node-labels]
"ingress" = "allowed"
"environment" = "prod"
[settings.kubernetes.system-reserved]
cpu = "100m"
memory = "256Mi"
ephemeral-storage = "2Gi"
[settings.kubernetes.kube-reserved]
cpu = "100m"
memory = "256Mi"
ephemeral-storage = "512Mi"
[settings.kubernetes.eviction-hard]
"memory.available" = "10%"
# Hardening based on <https://github.com/bottlerocket-os/bottlerocket/blob/develop/SECURITY_GUIDANCE.md>
[settings.kernel]
lockdown = "integrity"
[settings.host-containers.admin]
enabled = false
source = "328549459982.dkr.ecr.eu-central-1.amazonaws.com/bottlerocket-admin:v0.7.2"
[settings.host-containers.control]
enabled = false
Converting TOML Settings to Init Script Format
In Cast AI, you can pass custom Bottlerocket configurations through the init script in the advanced section of node configurations. However, the settings must be converted to a single-line format compatible with the init script to do this.
Below is an example that converts the TOML-style settings listed above into a format compatible with the init script:
Note
The shebang
#!/bin/bashis required to pass our init script validation, even though Bottlerocket AMIs do not have a default shell.
#!/bin/bash
settings.kubernetes.node-labels."ingress"="allowed"
settings.kubernetes.node-labels."environment"="prod"
settings.kubernetes.system-reserved.cpu="100m"
settings.kubernetes.system-reserved.memory="256Mi"
settings.kubernetes.system-reserved.ephemeral-storage="2Gi"
settings.kubernetes.kube-reserved.cpu="100m"
settings.kubernetes.kube-reserved.memory="256Mi"
settings.kubernetes.kube-reserved.ephemeral-storage="512Mi"
settings.kubernetes.eviction-hard."memory.available"="10%"
settings.kernel.lockdown="integrity"
settings.host-containers.admin.enabled=false
settings.host-containers.admin.source="328549459982.dkr.ecr.eu-central-1.amazonaws.com/bottlerocket-admin:v0.7.2"
settings.host-containers.control.enabled=false
Bottlerocket GPU nodes
When using GPU nodes with Bottlerocket, you must keep the default parameter
settings.kernel.lockdown="none".
There is a known Bottlerocket issue with self-signing the NVIDIA drivers: https://github.com/bottlerocket-os/bottlerocket/issues/4218.
Bottlerocket Settings Reference
The remaining fields in the advanced section of Cast AI's node configuration cannot be used to pass these configurations. Instead, you must use the settings exposed in the Bottlerocket API and set them within the init script.
Here is a visual of what sections of advanced node configuration settings can be used with Bottlerocket:
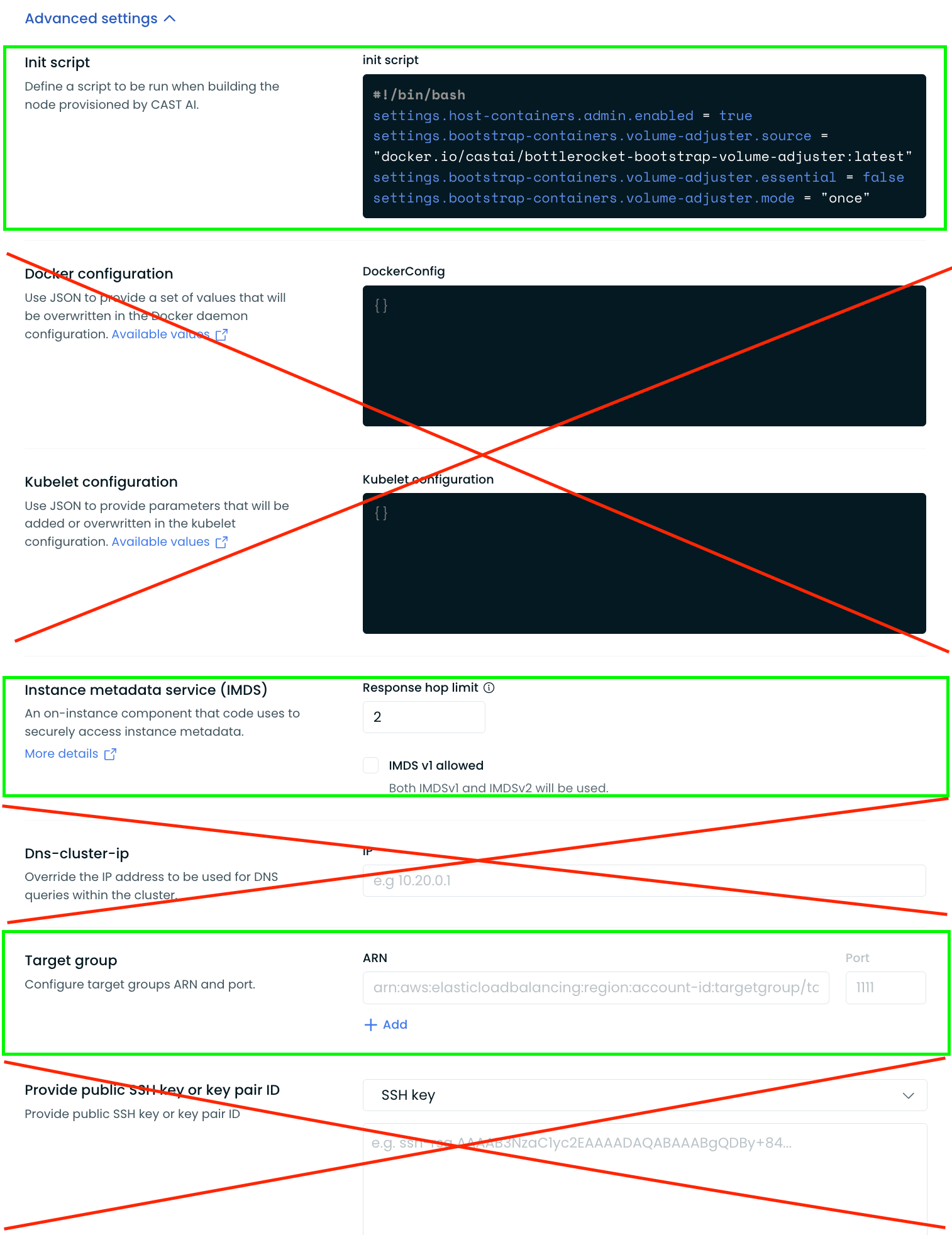
Customers migrating from other AMIs to Bottlerocket must convert their custom configurations into this Bottlerocket-compatible style and can only use the settings exposed in the API reference shared above.
Using Bootstrap Containers for Advanced Configurations
Any custom configurations outside of those settings, or the ability to change settings dynamically at boot, require the use of what Bottlerocket calls a bootstrap container.
Here is an example that dynamically adjusts the maximum number of pods per node based on the instance type:
settings.bootstrap-containers.max-pods-calculator.source = "docker.io/kisahm/bottlerocket-bootstrap-max-pods:v0.2"
settings.bootstrap-containers.max-pods-calculator.essential = false
settings.bootstrap-containers.max-pods-calculator.mode = "always"
settings.bootstrap-containers.max-pods-calculator.user-data = "ZXhwb3J0IEFERElUSU9OQUxfT1BUSU9OUz0iLS1jdXN0b20tY25pIGNpbGl1bSAtLWNpbGl1bS1maXJzdC1pbnRlcmZhY2UtaW5kZXggMSIK"
See the GitHub repository for detailed instructions: Bottlerocket Bootstrap Custom Max Pods
Connecting to Bottlerocket Nodes
Connecting to Bottlerocket nodes requires using an admin or control host container with special privileges. Guidance is provided in the Bottlerocket documentation:
Using Bottlerocket with Cast AI provides a secure foundation for container orchestration. While Bottlerocket's minimalistic design limits the use of traditional configuration methods, you can effectively pass custom configurations through the init script by converting them into the appropriate format. For advanced or dynamic configurations, bootstrap containers offer a solution to extend functionality.
GKE-specific configuration options
| Configuration | Description | Default value |
|---|---|---|
| Network tags | A string to be added to a tags field in a GCP VM resource | Empty |
| Max pods per node | Maximum number of pods to be hosted on a node | 110 |
| Boot disk | Boot disk storage type | balanced as per GCP documentation |
| Use Local SSD-backed ephemeral storage | Attach local ephemeral storage backed by Local SSD volumes. Check GCP documentation for more details. | False |
AKS-specific configuration options
| Configuration | Description | Default value |
|---|---|---|
| Max pods per node | Maximum number of pods to be hosted on a node. | 30 |
| OS Disk | The type of managed OS disk. | Standard SSD |
| Image Family | The OS family used for provisioning nodes. Possible values: - FAMILY_UNSPECIFIED- FAMILY_UBUNTU- FAMILY_AZURE_LINUX (Azure Linux 3.0 is available from AKS v1.32 onward)- FAMILY_WINDOWS_2019 - FAMILY_WINDOWS_2022Note: When verifying the OS version of an added node, don't rely on the Kubernetes label — log in to the node and check it directly. | FAMILY_UBUNTU |
| Load Balancers | A list of load balancers to attach nodes to. Setting this field disables Cast's default load balancer auto-discovery.id - The full ID of the Azure load balancer.ipBasedBackendPools - A list of IP-based backend pool names for attaching each node's IP.nicBasedBackendPools - A list of NIC-based backend pool names for attaching each node's NIC. | empty |
Note
Kubelet configuration is not supported in AKS.
Virtual machine image choice
When Cast AI provisions a node, it must choose an appropriate VM image. This choice is crucial because the OS and version of the image determine the correct bootstrapping logic and instance type support and are critical to ensuring the node joins the cluster successfully. For advanced use cases, Cast AI offers several options in the node configuration.
EKS
EKS supports a combination of the Image and Image Family fields to control OS choice.
- Image family: Determines the provisioning logic based on OS. If not provided, a default family is used for all operations (currently Amazon Linux 2).
- Image: Used to determine the actual image choice more precisely. The system supports three scenarios for this field:
- AMI ID (e.g.,
ami-1234567890abcdef0): A single item. Must point to a specific AMI. If the AMI architecture does not match the instance type, provisioning will fail. Use architecture restrictions in the Node template to avoid this scenario. The AMI must match the image family (default or provided value), or provisioning will fail. - Search string (e.g.,
amazon-eks-node-*): The search matches thenamefilter in aws describe-images and can include wildcards. The search can result in multiple images, and the system will choose the latest image in the list based on instance type, architecture, and Kubernetes version (if part of the image's name). If no images match the instance type architecture or the images are from a different family than the Image family field, provisioning will fail. - Empty: A default search will be performed based on the Image family. This search looks for public Amazon-owned images and will consider instance type architecture and Kubernetes versions to choose the proper image.
Sample scenarios and suggested configuration:
| Scenario | Suggested setup |
|---|---|
| Hands-off approach, let Cast AI choose. | Empty Image and Image family. |
| I want to use a specific OS family and let Cast AI choose the latest image based on the instance architecture and Kubernetes version. | Select Image family, empty Image field. |
| I want to use private or third-party AMI images and let Cast AI choose the image based on instance architecture. | Add a search string to the image that matches the required images. Select the proper image family (if different from the default). For multi-architecture instances, the list must include images for both arm64 and x86. |
| I want to use private or third-party AMI images that do not have architecture-agnostic builds, but let Cast AI choose the latest release. | Add a search string in Image. Select the proper image family (if different from the default). Add architecture constraints to node templates. |
| I want to use a specific golden AMI. | Enter the AMI in the Image field. Select the Image family (if different from the default) that matches the OS. Add architecture constraints to node templates. |
GKE/AKS
For GKE and AKS, the image field can be used to control the node bootstrapping logic (for Linux).
- The reference must point to a specific image.
- If the image does not match the instance type architecture (for example, an ARM64 image for an x86 node), node provisioning will fail.
- Changing the value might require a successful reconciliation to recreate Cast AI-owned node pools.
- If an image is not provided, the default behavior is to use the OS image captured when creating the
castpoolnode pool.
How to create a node configuration
A default node configuration is created during cluster onboarding in the Cast AI-managed mode.
You can choose to modify this configuration or create a new one. If you add a new node configuration that will be applied to all newly provisioned nodes, you must mark it as default.
Node configurations are versioned, and when the Cast AI provisioner adds a new node, the latest version of the node configuration is applied.
A new configuration can't be applied to an existing node. If you want to upgrade node configuration on a node or a set of nodes, you need to delete an existing node and wait until Autoscaler replaces it with a new one or rebalance the cluster (fully or partially).
Kubelet configuration examples
The Kubernetes documentation—Kubelet Configuration —contains all available Kubelet settings. Please refer to the version of your cluster.
For example, if you want to add some specific custom taints during node startup, you could do it with the following snippet:
{
"registerWithTaints": [
{
"effect": "NoSchedule",
"key": "nodes-service-critical",
"value": "true"
}
]
}
The second example involves configuring thekubelet image pulling and setting kube API limits like the following:
{
"eventBurst": 20,
"eventRecordQPS": 10,
"kubeAPIBurst": 20,
"kubeAPIQPS": 10,
"registryBurst": 20,
"registryPullQPS": 10
}
Since kubeReserved cannot be edited as it may cause conflicts with the Autoscaler, systemReserved can be configured instead in the Kubelet configuration under Advanced Settings in NodeConfig, as shown in the following example:
{
"systemReserved": {
"cpu": "500m",
"memory": "1Gi"
}
}
Create node configuration with the Cast AI Terraform provider
Use the resource castai_node_configuration from Cast AI terraform provider.
Reference example:
resource "castai_node_configuration" "test" {
name = local.name
cluster_id = castai_eks_cluster.test.id
disk_cpu_ratio = 5
subnets = aws_subnet.test[*].id
tags = {
env = "development"
}
eks {
instance_profile_arn = aws_iam_instance_profile.test.arn
dns_cluster_ip = "10.100.0.10"
security_groups = [aws_security_group.test.id]
}
}
Updated 16 days ago