
Serverless inference
Access production-ready open-source LLMs instantly through Cast AI's serverless inference endpoints. No infrastructure required.
Serverless Model APIs provide instant access to production-ready open-source LLMs hosted on Cast AI infrastructure. You can start making inference requests in minutes without provisioning GPUs, connecting a Kubernetes cluster, or managing any infrastructure of your own.
The API is fully OpenAI-compatible, making it a drop-in replacement for the integrations you already have. New users receive generous throughput limits to experiment before committing to a paid plan, and no credit card is required to get started.
Why use Serverless Model APIs
Generate an API key and make your first request immediately. No cluster setup, no GPU provisioning, no DevOps required.
Generous rate limits with no credit card required. Build and test your application before committing to a paid plan.
Use the same API format as OpenAI. Switch from other providers or integrate with existing tools with minimal code changes.
How it works
Serverless Model APIs run on Cast AI-managed infrastructure. When you make an inference request, Cast AI routes it to the requested model running on optimized GPU nodes. You pay per token used, with pricing that varies by model size.
This differs from other AI Enabler deployment options in important ways.
External API providers like OpenAI and Anthropic require you to provide your own API keys and pay them directly. AI Enabler acts as a gateway, forwarding each request to the specified provider and model.
Serverless Model APIs give you the simplicity of external providers with the cost advantages of open-source models. Cast AI runs the models on its own GPU infrastructure, and you pay only for the tokens you use.
Self-hosted deployments run models in your own Kubernetes cluster. You control the infrastructure and pay for compute resources rather than per-token pricing. This option requires a connected cluster managed by Cast AI.
Available models
Serverless Model APIs currently cover agentic coding use cases, meaning the supported models are optimised for coding purposes. We are constantly updating the list of supported use cases and models, but you can request a specific model by contacting our team.
| Model | Parameters | Best for |
|---|---|---|
| GLM 5 FP8 | 744B | Reasoning |
| Kimi K2.5 | 1T (32B active) | Agentic coding, image analysis |
| Minimax-M2.7 | 229B | Code generation, technical tasks |
| Minimax-M2.5 | 229B | Code generation, technical tasks |
For current pricing and the complete list of available models, see the Serverless models page in the Cast AI console under AI Enabler.
Getting started
To start using serverless endpoints, you need a Cast AI account and an API key.
Step 1: Sign up or log in
Navigate to the Cast AI console to create an account or log in.
Step 2: Generate an API key
Go to AI Enabler > Overview and click Generate API key. Copy the key and store it securely.
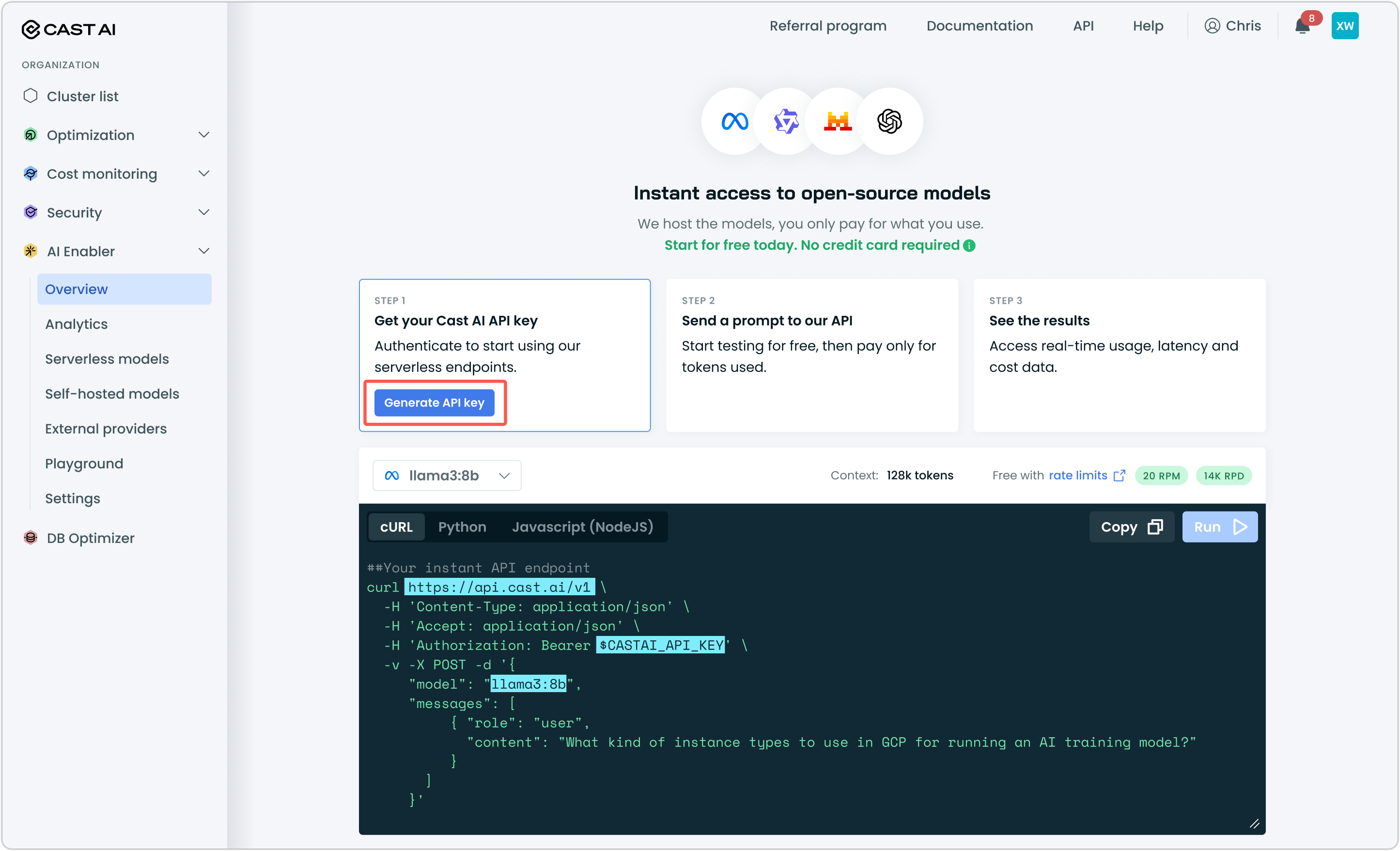
Step 3: Make your first request
Use any OpenAI-compatible client or make a direct HTTP request. Here's an example using cURL that you can copy-paste in your terminal, add your key, and just hit Enter:
curl https://llm.cast.ai/openai/v1/chat/completions \
-H 'Content-Type: application/json' \
-H 'Accept: application/json' \
-H 'Authorization: Bearer $CASTAI_API_KEY' \
-v -X POST -d '{
"model": "minimax-m2.7",
"messages": [
{
"role": "user",
"content": "What kind of instance types to use in GCP for running an AI training model?"
}
]
}'The response follows the standard OpenAI chat completions format, so existing code that works with OpenAI will work with Serverless Model APIs after changing the base URL and API key.
Pricing and billing
Serverless Model APIs use pay-per-token pricing. You're charged separately for input tokens (your prompts) and output tokens (model responses), with rates varying by model size.
The free tier offers rate limits suitable for small projects. When you need higher throughput, upgrade to a paid plan for increased rate limits and continued access after credits are exhausted.
For detailed rate limit information, see Rate limits.
When to use Serverless Model APIs vs. self-hosted
Serverless endpoints are ideal when you want to move fast without infrastructure overhead. Use them for prototyping, development, moderate production workloads, or when you don't have a Kubernetes cluster available.
Consider migrating to a self-hosted deployment when your usage grows to the point where per-token costs exceed compute costs, when you need dedicated capacity with guaranteed availability, or when compliance requirements mandate running models in your own environment.
The migration path is straightforward: the same models are available for self-hosted deployment, and the API format remains identical. You can run both serverless and self-hosted models simultaneously during a transition period. All made possible with AI Enabler.
Next steps
Understand request and token limits by plan before building for production.
Configure OpenCode to use different modesls for code generation and for reasoning in a cost-effective multi-model workflow.
Set up Cline CLI or your IDE to use AI Enabler as a drop-in provider for AI-assisted development.
Deploy models on your own cluster when per-token costs exceed compute costs or compliance requires it.
Updated 2 months ago